✅063 Введение в представления/ SQL ДЛЯ ЧАЙНИКОВ
71
1
00:12:03
18.10.2022
# sql #sqlлячайников # sqlуроки
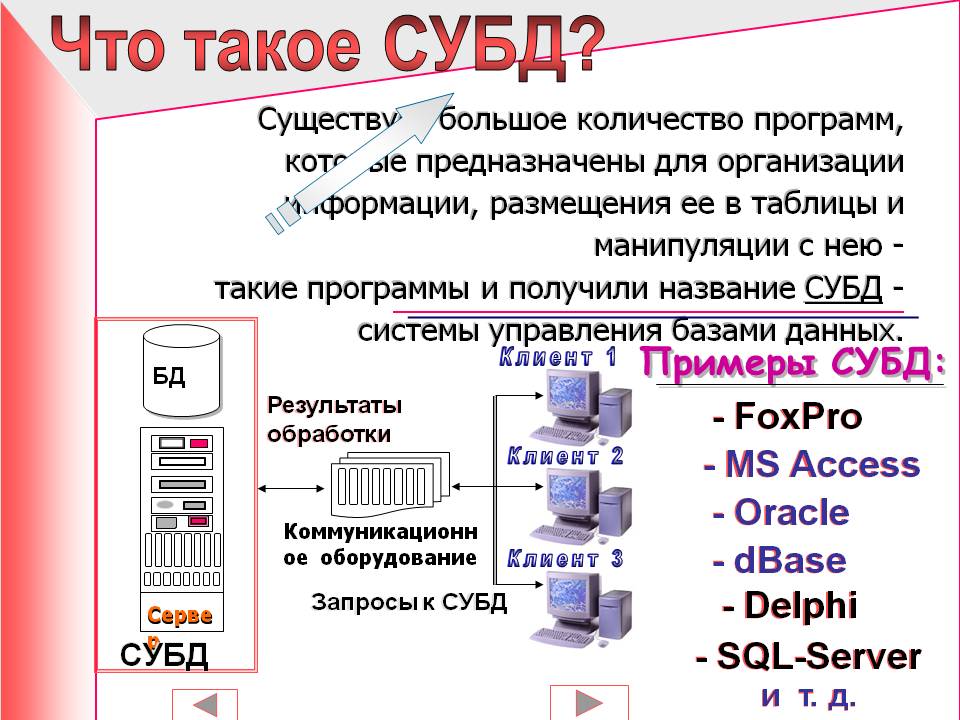
Вы научитесь читать и писать сложные запросы к базам данных, используя один из самых востребованных языков программирования — SQL и супер востребованную СУБД (систему управления базами данных) — PostgreSQL. Все те знания, которые вы получите на курсе, легко применимы и к другим СУБД, таким как MySQL, Microsoft SQL Server, Oracle.
Изучение SQL это один из самых быстрых способов подняться по карьерной лестнице и начать зарабатывать ещё больше. На курсе вы будете учиться и получать задания для собственной проверки и улучшения понимания материала.
Введение в SQL: концепции, реляционная модель, инсталляция postgres, создание БД, таблиц, виды отношений, типы данных
Простые выборки: SELECT, DISTINCT, COUNT, WHERE, AND / OR, BETWEEN, IN, ORDER BY, MIN/MAX/AVG, LIKE, LIMIT, GROUP BY, HAVING, UNION/INTERSECT/EXCEPT, проверки на NULL
Соединения: INNER, LEFT, RIGHT, SELF, USING и NATURAL JOIN
Подзапросы: WHERE EXISTS, подзапросы с квантификаторами
DDL: управление ключами (PK, FK), ограничения, последовательности, INSERT, UPDATE/DELETE/RETURNING
Проектирование БД: основы, рекомендации, нормальные формы (НФ)
Представления (Views): основы, создание, обновления через views, опция check
Логика с CASE WHEN, COALESCE и NULLIF
Функции SQL: основы, скалярные функции, IN/OUT/DEFAULT, возврат наборов данных
Функции PL/pgSQL: основы, возврат и присвоение, декларация переменных, логика с if-else, циклы, RETURN NEXT
Ошибки и их обработка
Индексы: основы, методы сканирования, виды, EXPLAIN, ANALYZE
Массивы: основы, создание, нарезка (slicing), операторы, VARIADIC и FOREACH
Продвинутая группировка с CUBE/ROLLUP
Пользовательские типы: домены, композитные типы, перечисления
psql и импорт данных
Транзакции
Безопасность
Оконные функции
Триггеры
И многое другое из области изучения и применения языка запросов SQL на практике!
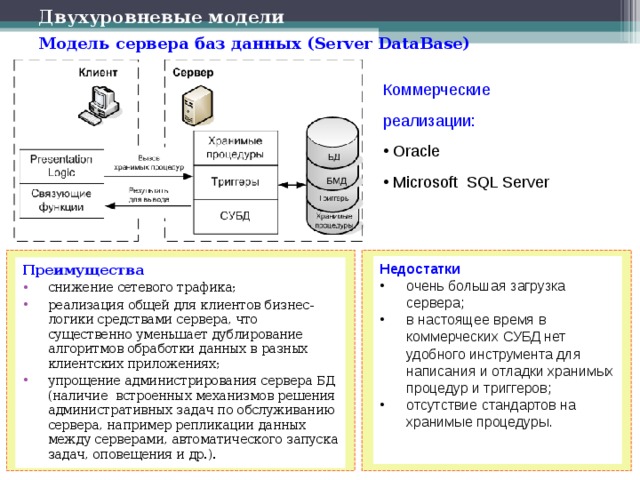
Перенос базы данных доступа на SQL Server
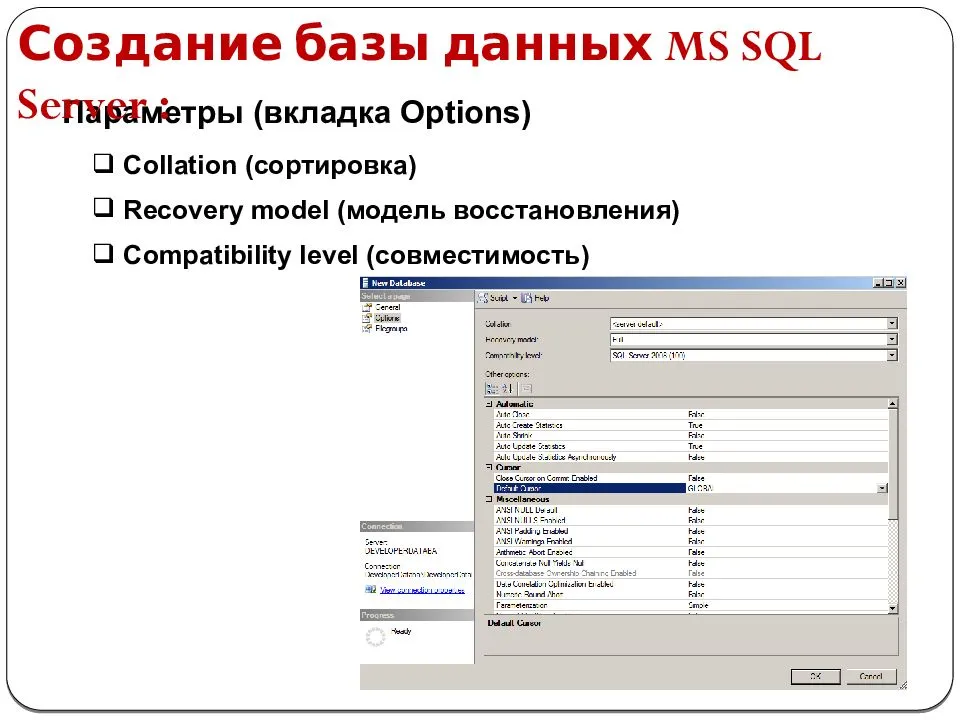
Откройте SQL Server Management Studio и подключитесь к серверу базы данных, в который вы хотите импортировать базу данных Access. Под Базы данныхщелкните правой кнопкой мыши и выберите Новая база данных, Если у вас уже есть база данных, и вы просто хотите импортировать пару таблиц из Access, просто пропустите это и перейдите к Импорт данных шаг ниже. Просто щелкните правой кнопкой мыши на вашей текущей базе данных вместо создания новой.
Если вы создаете новую базу данных, продолжайте, дайте ей имя и настройте параметры, если вы хотите изменить их по умолчанию.
Теперь нам нужно щелкнуть правой кнопкой мыши на тестовой базе данных, которую мы только что создали, и выбрать Задания а потом Импорт данных,
На Выберите источник данных диалоговое окно, выберите Microsoft Access (ядро базы данных Microsoft Jet) из выпадающего списка.
Следующий на Имя файлае, нажмите на Просматривать и перейдите к базе данных Access, которую вы хотите импортировать, и нажмите открыто, Обратите внимание, что база данных не может быть в Access 2007 или более высоком формате (ACCDB) как SQL Server не распознает это! Поэтому, если у вас есть база данных Access с 2007 по 2016, сначала преобразуйте ее в База данных 2002-2003 формат (MDB) зайдя в Файл — Сохранить как,
Идите вперед и нажмите следующий выбрать пункт назначения. Поскольку вы щелкнули правой кнопкой мыши базу данных, в которую хотите импортировать данные, она уже должна быть выбрана в списке. Если нет, выберите Собственный клиент SQL от Пункт назначения падать. Вы должны увидеть экземпляр базы данных под Название сервера и затем сможете выбрать конкретную базу данных внизу, как только вы выберете метод аутентификации.
щелчок следующий а затем укажите способ передачи данных из Access в SQL, выбрав Скопируйте данные из одной или нескольких таблиц или Напишите запрос, чтобы указать данные для передачи,
Если вы хотите скопировать все таблицы или только некоторые таблицы из базы данных Access без каких-либо манипуляций с данными, выберите первый вариант. Если вам нужно скопировать только определенные строки и столбцы данных из таблицы, выберите второй вариант и напишите SQL-запрос.
По умолчанию все таблицы должны быть выбраны, и если вы нажмете редактировать Отображения Кнопка, вы можете настроить, как поля отображаются между двумя таблицами. Если вы создали новую базу данных для импорта, то она будет точной копией.
Здесь у меня есть только одна таблица в моей базе данных Access. Нажмите Далее, и вы увидите Запустить пакет экран где Беги немедленно должны быть проверены.
щелчок следующий а затем нажмите Конец, Затем вы увидите, как происходит процесс передачи данных. После его завершения вы увидите количество строк, переданных для каждой таблицы в Сообщение колонка.
щелчок близко и вы сделали. Теперь вы можете запустить SELECT для ваших таблиц, чтобы убедиться, что все данные были импортированы. Теперь вы можете использовать возможности SQL Server для управления вашей базой данных.
Есть проблемы с импортом данных из Access в SQL Server? Если да, оставьте комментарий, и я постараюсь помочь. Наслаждайтесь!
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
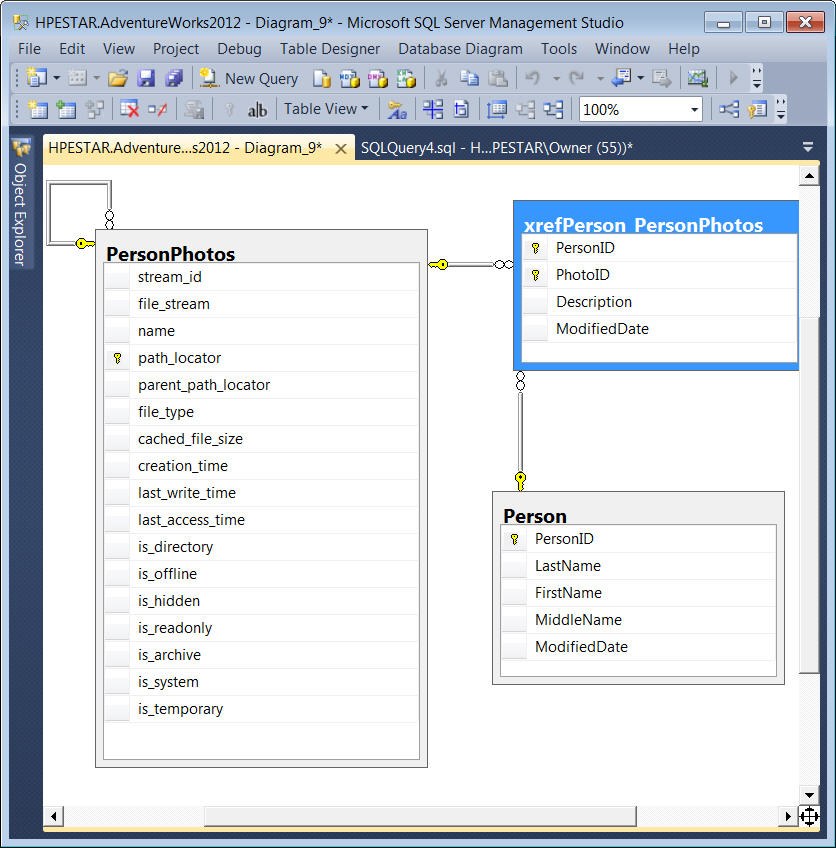
Table Expression VIEWs
An old usage for s was to do the work of CTEs when there were no CTEs. The programmers created s, and then used them. Of course they wasted space, caused disk reads and were only used in one statement. It might be worth looking at old code for s that are not shared.
Today the reverse is true. Programmers create the same CTE code over and over in different queries and give it local names for each appearance. Those local names are seldom the same and are often “place markers” like “X” or “CTE_1” and give no hint as to what the table expression means in the data model.
It can be hard to factor out common table expressions across multiple queries. One query uses an infixed JOIN operators and another uses a <span class=”mono”>FROM</span> list, the predicates are equivalent but written slightly different and so forth.
I recommend that you sit down and think of useful s, write them and then see if you can find places where they would make the code easier to read and maintain. As an example, our hotel application will probably need to find vacant rooms by calendar date, compute an occupancy ratio by calendar date and other basic facts.
Another bad use is the one per Base Table myth that was poplar with DB2 programmers years ago. The reasoning behind this myth was the applaudable desire to insulate application programs from database changes. All programs were to be written against s instead of base tables. When a change is made to the base table, the programs would not need to be modified because they access a , not the base table.
This does not work in the long run. All you do is accumulate weird orphaned s. Consider the simplest type of database change – adding a column to a table. If you do not add the column to the , no programs can access that column unless another is created that contains the new column. But if you create a new every time you add a new column it will not take long for your schema to be swamped with s. Even more troublesome is the question of which should be used by which program. Similar arguments can be made for any structural change to the tables.
Зачем нужны представления?
Одним из главных достоинством представлений является то, что они сильно упрощают взаимодействие с данными в базе данных. Допустим, Вам необходимо каждый раз делать сложную по своей структуре выборку, а как Вы знаете, запрос на выборку может быть, ну просто очень сложный и этому нет предела. И если не было бы вьюшек, то Вам приходилось бы каждый раз запускать этот запрос, или даже его модифицировать, например, для вставки условий. А так как у нас есть такие объекты как представления, нам этого делать не придется. Мы просто на всего создадим одну вьюшку, и потом уже к ней будем обращаться с помощью уже простых запросов, которые также можно делать сложными, если это необходимо. Например, вьюшки также можно объединять с другими таблицами или другими представлениями.
К представлениям можно обращаться и из приложений, например, Вам нужно вывести какой-нибудь отчет, формирование которого требует каких-то расчетов, это легко можно реализовать путем написания необходимого запроса (в котором и будут рассчитываться данные, например из разных таблиц
) и вставке этого запроса во вьюшку. А потом уже обращаться к этой вьюшке, например с помощью такого простого запроса как:
SELECT * FROM TableName
Как создать представление VIEWS?
Теперь давайте поговорим о том, как создавать эти самые вьюшки. Во-первых, сразу скажу, что для этого необходимы знания SQL (для построения сложных запросов
). Во-вторых, Вы за ранее должны определиться, что Вам необходимо вывести в результате того или иного запроса. Рассматривать процесс создания представления путем нажатия кнопок мы не будем, так это достаточно просто. Мы рассмотрим создание VIEWS с использованием языка SQL (хотя и это тоже просто
).
Например, в PostgreSQL запрос создания представления будет выглядеть так:
CREATE VIEW MyView
AS
SELECT id, name, org
FROM work.TableName
- CREATE VIEW – команда создания представления;
- MyView – название Вашей будущей вьюшки;
- SELECT id, name, org FROM work.TableName – запрос на выборку.
Здесь мы использовали простой запрос на выборку, Вы в свою очередь можете писать любой запрос, даже с объединением нескольких таблиц и условий к ним.
Полный синтаксис команды CREATE VIEW (в PostgreSQL) выглядит следующим образом:
CREATE
VIEW view_name
AS select_statement
CHECK OPTION]
После того, как Вы создали представление, Вы можете к нему обращаться. А данные, которые будет выводить вьюшка, будут изменяться в зависимости от изменений данных в исходных таблицах, так как данные во вьюшке формируются при обращении к этому представлению. Исходя из этого, можно сделать вывод, что данные, которые выводит вьюшка, будут всегда актуальные.


У меня все, надеюсь, теперь у Вас есть представление о том, что такое VIEWS, пока!
Представлениями
можно управлять в редакторе запросов,
выполняя сценарии SQL, которые используют
команды языка DDL: CREATE, ALTER и DROP. Основной
синтаксис создания представления
следующий:
CREATE VIEWимя_представления
AS
инструкция_SELECT
Например,
чтобы создать представление v_Customer,
возвращающее список клиентов с указанием
города проживания, программным путем,
в окне запросов должна быть выполнена
следующая команда.
CREATE
VIEW
.
SELECT
dbo.Customer.IdCust,
dbo.Customer.FName,
dbo.Customer.LName,
dbo.City.CityName
FROM
dbo.Customer
INNER
JOIN
dbo.City
ON
dbo.Customer.IdCity
=
dbo.City.IdCity
Попытка
создать представление, которое уже
существует, вызовет ошибку. Когда
представление создано, инструкцию
SELECT можно с легкостью отредактировать
с помощью команды ALTER:
ALTER
имя_представления
AS
измененная_инструкция_SELECT
Если
изменение представления предполагает
и изменение прав доступа на него,
предпочтительнее удалить его и создать
заново, поскольку удаление представления
также приводит и к удалению разрешений
доступа, установленных ранее.
Чтобы
удалить представление из базы данных,
используйте команду DROP:
DROP
VIEW имя_представления
Редактирование информации о представлениях
Наиболее важным представлением каталога применительно к представлениям является sys.objects. Как уже упоминалось, это представление каталога содержит информацию касательно всех объектов в текущей базе данных. Все строки этого представления со значением V в столбце type содержат информацию о представлениях.
А представление каталога sys.views содержит дополнительную информацию о существующих представлениях. Наиболее важным столбцом этого представления является столбец with_check_option, который информирует, указано или нет предложение WITH CHECK OPTION. Запрос для определенного представления можно отобразить посредством системной процедуры sp_helptext.
Что такое SQL ИНДЕКСЫ за 10 минут: Объяснение с примерами
34969
1963
56
00:10:41
02.01.2023
События и статьи про анализ и проектирование ИТ-систем — 🤍
В этой статье мы узнаем:
— Что такое индексация в SQL
— Для чего нужна индексация
— Как работает индексация
— Что такое двоичный поиск
— Что такое план выполнения запроса
— Когда лучше использовать индексы
— Когда лучше НЕ использовать индексы
— Что такое кластеризованный индекс
— Что такое некластеризованный индекс
Поддержать канал разово — 🤍
Поддержать канал подпиской — 🤍
Я.Дзен — 🤍
Телеграм-канал — 🤍
По вопросам сотрудничества — 🤍
Ссылка на статью 1 — 🤍
Ссылка на статью 2 — 🤍
Что такое SQL и реляционные базы данных — 🤍
Синтаксис SQL запросов: Часть 1 — 🤍
Что такое NoSQL за 6 минут — 🤍
Что такое ACID за 9 минут — 🤍
Что такое UML за 7 минут — 🤍
Что такое Scrum за 8 минут — 🤍
Обзор Agile — 🤍
Приоритизация бэклога за 4 минуты — 🤍
Что такое Kanban — 🤍
Что такое Канбан-доска — 🤍
Что такое HTTP и HTTPS за 9 минут — 🤍
Машинное обучение для чайников — 🤍
Что такое Big Data за 6 минут — 🤍
Что такое CRUD за 6 минут — 🤍
Введение в REST API за 7 минут — 🤍
Различия REST и SOAP за 4 минуты — 🤍
Что такое middleware за 7 минут — 🤍
Что такое UML за 7 минут — 🤍
Materialized Views
Materialized views are similar to standard views, however they store the result of the query in a physical table taking up memory in your database. This means that a query run on a materialized view will be faster than standard view because the underlying query does not need to be rerun each time the view is called. The query is run on the new Materialized view:
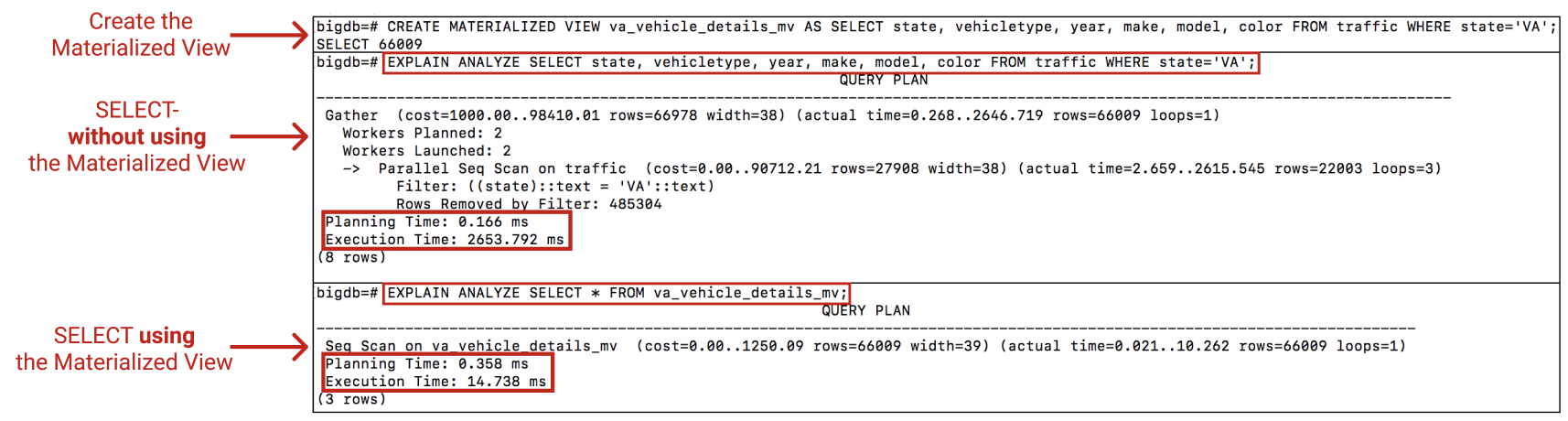
This query plan shows the materialized view being used as a table and being scanned. It also shows a significant difference in speed between the two methods.
Materialized views are generally most effective on computation-intensive views. Materializing a view has several benefits but also several drawbacks.
Pros:
- Faster — Aggregations and Joins are run beforehand
- Can be Indexed for even greater speed
- Does not update after each run: saves server’s time by preventing unnecessary refreshing
Cons:
- Takes more memory
- Does not update after each run: Must be refreshed so data may not be completely up to date
- Must be refreshed one of two ways:
- Manually:
- Completely Recalculate entire view (possibly expensive)
- Supports all SQL
- Incrementally:
- Does not support some functions and outer joins
- Only update specific rows
- Note: Not all SQL types support this. (e.g. can be done in Oracle and DBT, but not PostgreSQL.)
- Manually:
To create a materialized view, add the MATERIALIZED keyword:
To refresh the view manually use the following command:
Как создать представление VIEWS?
Теперь давайте поговорим о том, как создавать эти самые вьюшки. Во-первых, сразу скажу, что для этого необходимы знания SQL (для построения сложных запросов). Во-вторых, Вы за ранее должны определиться, что Вам необходимо вывести в результате того или иного запроса. Рассматривать процесс создания представления путем нажатия кнопок мы не будем, так это достаточно просто. Мы рассмотрим создание VIEWS с использованием языка SQL (хотя и это тоже просто).
Например, в PostgreSQL запрос создания представления будет выглядеть так:
- CREATE VIEW – команда создания представления;
- MyView – название Вашей будущей вьюшки;
- SELECT >Здесь мы использовали простой запрос на выборку, Вы в свою очередь можете писать любой запрос, даже с объединением нескольких таблиц и условий к ним.
Полный синтаксис команды CREATE VIEW (в PostgreSQL) выглядит следующим образом:
После того, как Вы создали представление, Вы можете к нему обращаться. А данные, которые будет выводить вьюшка, будут изменяться в зависимости от изменений данных в исходных таблицах, так как данные во вьюшке формируются при обращении к этому представлению. Исходя из этого, можно сделать вывод, что данные, которые выводит вьюшка, будут всегда актуальные.
У меня все, надеюсь, теперь у Вас есть представление о том, что такое VIEWS, пока!
ОБЛАСТЬ ПРИМЕНЕНИЯ:
APPLIES TO:
Представление — это виртуальная таблица, содержимое которой определяется запросом. A view is a virtual table whose contents are defined by a query. Как и таблица, представление состоит из ряда именованных столбцов и строк данных. Like a table, a view consists of a set of named columns and rows of data. Пока представление не будет проиндексировано, оно не существует в базе данных как хранимая совокупность значений. Unless indexed, a view does not exist as a stored set of data values in a database. Строки и столбцы данных извлекаются из таблиц, указанных в определяющем представление запросе и динамически создаваемых при обращениях к представлению. The rows and columns of data come from tables referenced in the query defining the view and are produced dynamically when the view is referenced.

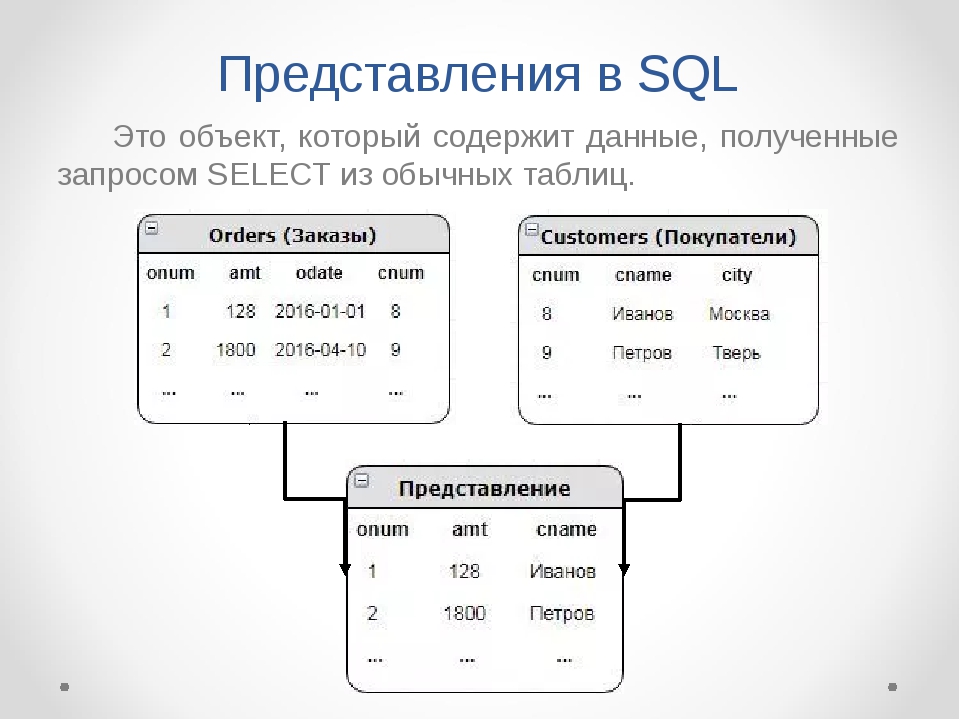
Представление выполняет функцию фильтра базовых таблиц, на которые оно ссылается. A view acts as a filter on the underlying tables referenced in the view. Определяющий представление запрос может быть инициирован в одной или нескольких таблицах или в других представлениях текущей или других баз данных. The query that defines the view can be from one or more tables or from other views in the current or other databases. Кроме того, для определения представлений с данными из нескольких разнородных источников можно использовать распределенные запросы. Distributed queries can also be used to define views that use data from multiple heterogeneous sources. Это полезно, например, если нужно объединить структурированные подобным образом данные, относящиеся к разным серверам, каждый из которых хранит данные конкретного отдела организации. This is useful, for example, if you want to combine similarly structured data from different servers, each of which stores data for a different region of your organization.
Представления обычно используются для направления, упрощения и настройки восприятия каждым пользователем информации базы данных. Views are generally used to focus, simplify, and customize the perception each user has of the database. Представления могут использоваться как механизмы безопасности, давая возможность пользователям обращаться к данным через представления, но не предоставляя им разрешений на непосредственный доступ к базовым таблицам, лежащим в основе представлений. Views can be used as security mechanisms by letting users access data through the view, without granting the users permissions to directly access the underlying base tables of the view. Представления могут использоваться для обеспечения интерфейса обратной совместимости, моделирующего таблицу, которая существует, но схема которой изменилась. Views can be used to provide a backward compatible interface to emulate a table that used to exist but whose schema has changed. Представления могут также использоваться при прямом и обратном копировании данных в SQL Server SQL Server для повышения производительности и секционирования данных. Views can also be used when you copy data to and from SQL Server SQL Server to improve performance and to partition data.
How Does an SQL View Work?
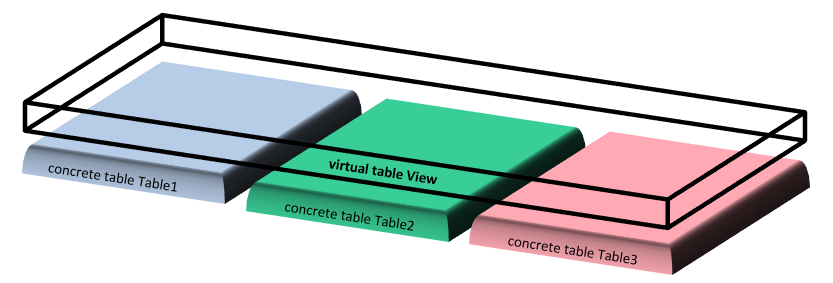
In the previous section, we learned that an SQL view can be treated like a normal table. However, under the hood, there is a difference between views and tables.
A table (concrete table) stores its data in columns and rows in the database. A view (virtual table) is built on top of the concrete table(s) it fetches data from and does not store any data of its own in the database. A view only contains the SQL query that is used to fetch the data.
To summarize, the result set of a view is not materialized on the disk, and the query stored by the view is run every time we call the view. Let’s look at the diagram below to understand the difference between concrete and virtual tables.
Работа с представлениями на T-SQL
Исходные данные
Сначала нам необходимо создать тестовые данные для наших примеров.
Допустим, у нас будет таблица Goods, которая хранит некую информацию о товарах, и таблица Categories, которая хранит данные о категориях товара.
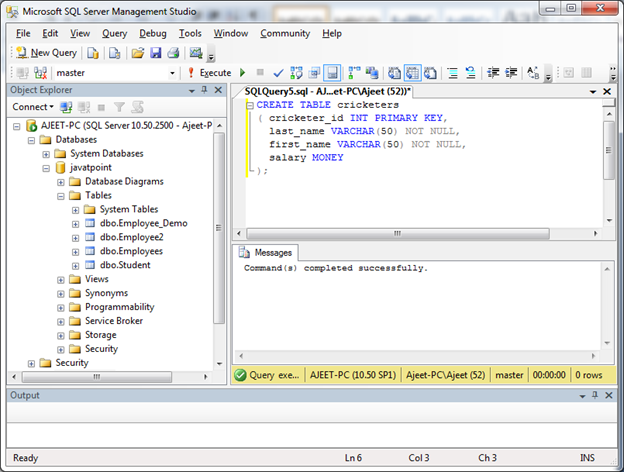
--Создание таблицы
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL,
Category INT NOT NULL,
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
--Добавление данных в таблицу
INSERT INTO Goods(Category, ProductName, Price)
VALUES (1, 'Клавиатура', 30),
(1, 'Монитор', 100),
(2, 'Смартфон', 200);
--Создание таблицы с категориями
CREATE TABLE Categories (
CategoryId INT IDENTITY(1,1) NOT NULL,
CategoryName VARCHAR(100) NOT NULL
);
--Добавление данных в таблицу с категориями
INSERT INTO Categories
VALUES ('Комплектующие компьютера'),
('Мобильные устройства');
SELECT * FROM Goods;
SELECT * FROM Categories;
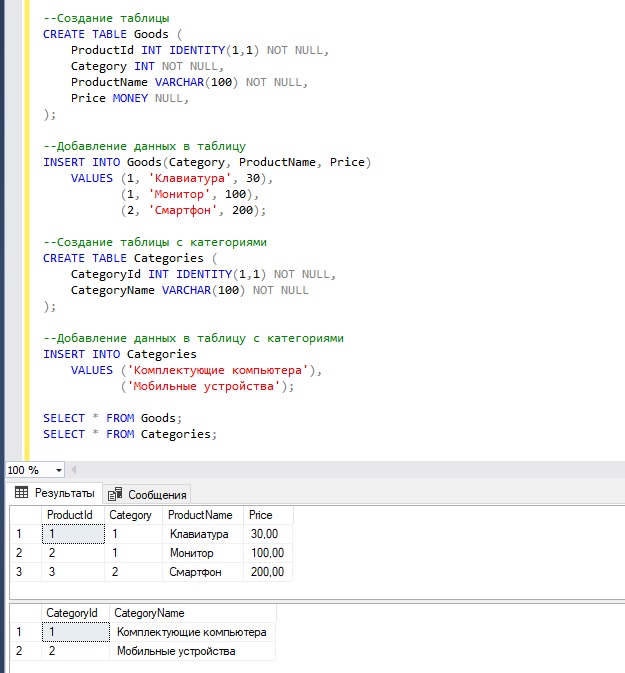
Создание представлений
Представим, что нам постоянно требуется знать, сколько товаров в той или иной категории, но писать каждый раз SQL запрос на получение таких данных нам не хочется и это не очень удобно. Поэтому мы приняли решения сохранить запрос на получение таких данных в виде представления и, когда нам потребуется узнать количество товаров в категории, мы просто будем обращаться к этому представлению.
Создается представление с помощью инструкции CREATE VIEW.
Для решения нашей задачи мы можем создать следующее представление.
CREATE VIEW CountProducts AS SELECT C.CategoryName AS CategoryName, COUNT(*) AS CntProducts FROM Goods G INNER JOIN Categories C ON Category = C.CategoryId GROUP BY C.CategoryName;
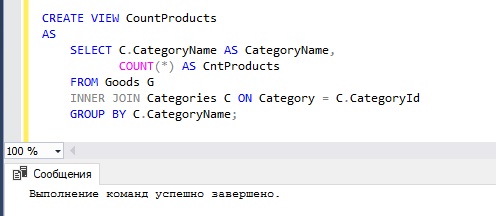
После инструкции CREATE VIEW мы указали название представления, затем мы указали ключевое слово AS и только после этого мы написали запрос, результирующий набор которого и будет содержать наше представление.
Теперь, для того чтобы получить данные о количестве товаров в категории, мы можем обратиться к этому представлению, например, как к обычной таблице.
SELECT * FROM CountProducts;
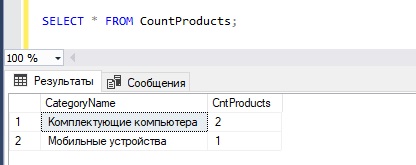
Изменение представлений
А сейчас давайте допустим, что нам нужно, чтобы это представление возвращало еще и идентификатор категории, если Вы обратили внимание, то в предыдущем примере таких данных нет. Для этого используем инструкцию ALTER VIEW, которая подразумевает изменение представления
ALTER VIEW CountProducts AS SELECT C.CategoryId, C.CategoryName AS CategoryName, COUNT(*) AS CntProducts FROM Goods G INNER JOIN Categories C ON Category = C.CategoryId GROUP BY C.CategoryId, C.CategoryName; GO SELECT * FROM CountProducts;
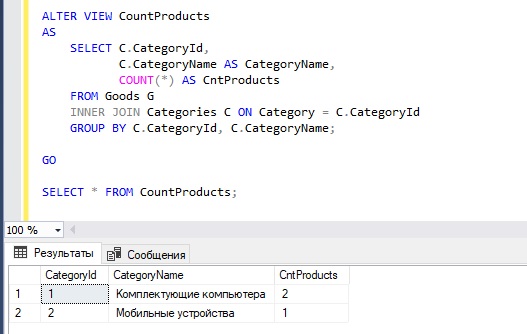
В данном случае мы написали инструкцию ALTER VIEW, которая говорит SQL серверу, что мы хотим изменить существующий объект, затем указали название представления, чтобы сервер мог определить, какое именно представление мы хотим изменить, после ключевого слова AS мы указали новое определение представления, т.е. измененный запрос SELECT.
Чтобы отделить инструкцию изменения представления от SQL запроса на выборку, мы написали команду GO.
Удаление представлений
Если Вам представление больше не требуется, т.е. Вы им больше не будете пользоваться, и оно не используется в других представлениях, функциях или процедурах, иными словами, на него никто не ссылается, то Вы его можете удалить, это делается с помощью инструкции DROP VIEW.
DROP VIEW CountProducts;
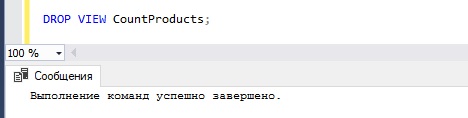
Теперь данного представления больше нет, и к нему Вы больше обратиться не сможете.
Dropping VIEWs
s, like tables, can be dropped from the schema. The T-SQL syntax for the statement is:
| 1 | DROPVIEW<tablenamelist>; |
The use of the <table name list> is dialect and it gives you a shorthand for repeating drop statements. The drop behavior depends on your vendor. The usual way of storing s was in a schema information table is to keep the name, the text of the , but dependencies. When you drop a , the engine usually removes the appropriate row from the schema information tables. You find out about dependencies when you try to use something that wants the dropped s. Dropping a base table could cause the same problem when the was accessed. But the primary key/foreign key dependencies among base tables will prevent dropping some base tables.
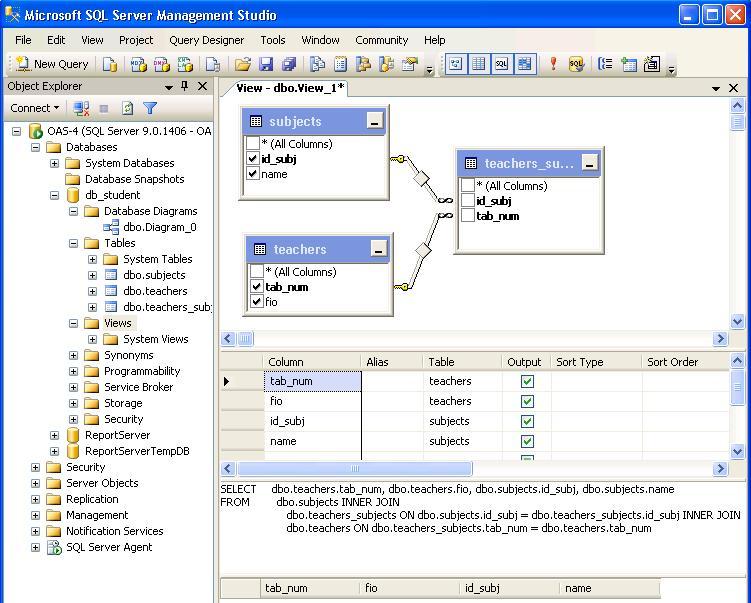
How to create a view in SQL via SSMS
SQL Server Management Studio AKA SSMS is the most popular and powerful tool to manage, configure, administer and do other uncountable operations in SQL Server. So, we can create a view through SSMS.
We will launch SSMS and login the database with any user who granted to create a view. Expand the database in which we want to create a view. Then right-click on the Views folder and choose the New
View option:
The Add Table dialog appears on the screen. On this screen, we will find and then select the
Product and ProductModel tables and click Add:
The relations between the tables are automatically detected and created by SSMS and at the same time, the view query
will be generated in the query tab automatically:
In this step, we will check in the necessary columns for the view. If we want to select all column names of the
table we can check in the * (All Columns) option. We will check in ProductId,
Name, ProductNumber columns in the Production table and
Name column in ProductModel table. We can observe the query changing when we check
in the names of the columns in tables:
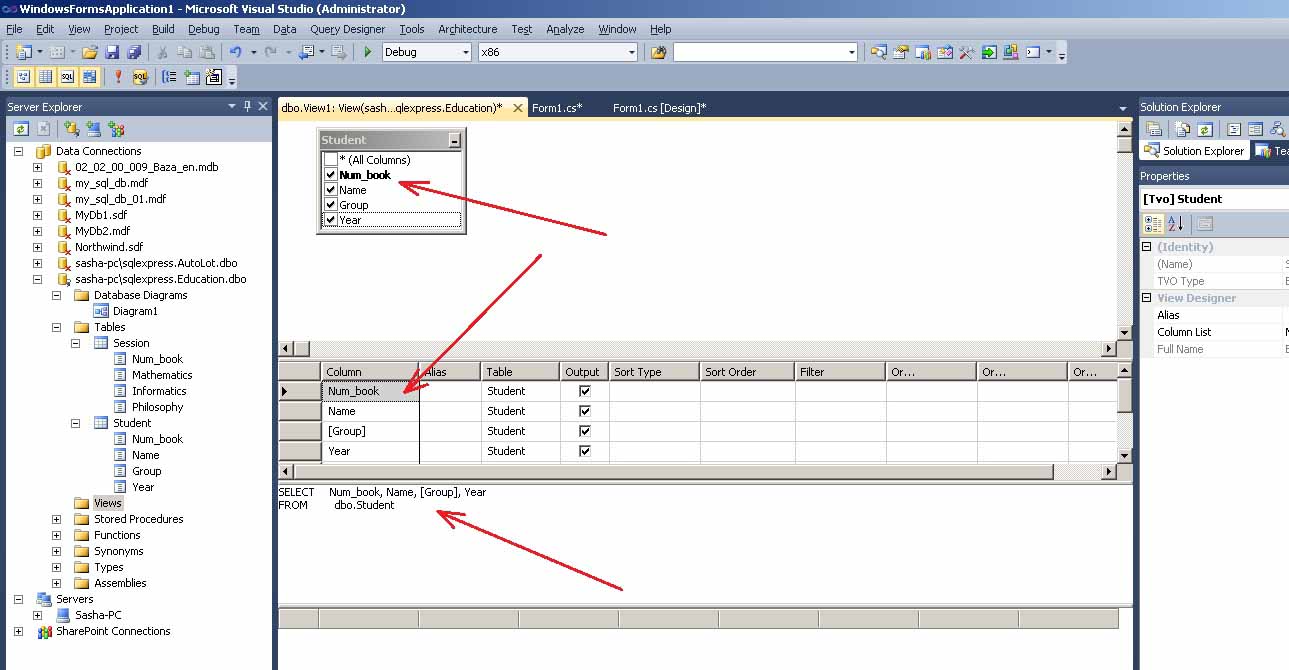
We will set aliases of the columns:
We will set the filter criteria and it will be automatically added into the WHERE condition of the query:
We can right-click in the table panel so that we can execute the view. The result data shows at the bottom of the
screen:
Finally, we will press CTRL+S keys in order to save the view and give a name to the view and click
OK:
The created view can be found under the Views folder:
Требования к созданию секционированных представлений
выборки.
В списке столбцов определения представления выберите все столбцы таблиц-элементов.
Столбцы, занимающие одну и ту же порядковую позицию в каждом , должны иметь одинаковый тип, включая параметры сортировки. Типы столбцов не просто должны поддерживать неявное преобразование друг в друга: в отличие от оператора UNION в данном случае этого недостаточно.
Кроме того, хотя бы один столбец (например, ) должен входить во все списки выбора в одной и той же порядковой позиции. Определите столбец таким образом, чтобы для таблиц-элементов в столбце были определены ограничения CHECK с идентификаторами соответственно.
Ограничение , определенное для таблицы , должно иметь следующий формат:
Ограничения должны быть такими, чтобы любое указанное значение могло удовлетворять не более чем одному из ограничений , т. е. они должны формировать совокупность неперекрывающихся интервалов. Столбец , для которого определены неперекрывающиеся ограничения, называется столбцом секционирования
Обратите внимание, что столбец секционирования может иметь другие имена в базовых таблицах. Чтобы ограничения соответствовали вышеуказанным требованиям столбца секционирования, они должны находиться во включенном и доверенном состоянии
Если ограничения отключены, включите проверку ограничений с помощью параметра CHECK CONSTRAINT constraint_name инструкции ALTER TABLE и проверьте их с использованием параметра WITH CHECK.
В следующем фрагменте продемонстрированы правильные наборы ограничений:
Один столбец не может быть указан в списке выбора несколько раз.
Столбец секционирования
Столбец секционирования является частью первичного ключа (PRIMARY KEY) таблицы.
Он не может быть вычисляемым столбцом, столбцом идентификаторов, столбцом по умолчанию или столбцом типа timestamp.
Если для одного столбца таблицы-элемента определено более одного ограничения, ядро СУБД пропускает все ограничения и не учитывает их при определении того, является ли представление секционированным. Чтобы выполнялись требования к секционированному представлению, со столбцом секционирования должно быть связано только одно ограничение секционирования.
На возможность обновления столбца секционирования никакие ограничения не распространяются.
Таблицы-элементы или базовые таблицы .
Эти таблицы могут быть или локальными таблицами, или таблицами с других компьютеров, на которых выполняется SQL Server. Во втором случае для ссылки на таблицу должно быть использовано или четырехкомпонентное имя, или имя в формате функции OPENDATASOURCE или OPENROWSET. Синтаксис функций OPENDATASOURCE и OPENROWSET позволяет указать имя таблицы, но не передаваемого запроса. Дополнительные сведения см. в разделе OPENDATASOURCE (Transact-SQL) и OPENROWSET (Transact-SQL).
Если хотя бы одна таблица-элемент является удаленной, представление называется распределенным секционированным представлением, и тогда вступают в силу дополнительные требования. Они описаны ниже в данном разделе.
Одна таблица не может быть указана два раза в наборе таблиц, объединяемых при помощи инструкции UNION ALL.
Таблицы-элементы не могут иметь индексы, созданные для вычисляемых столбцов в таблице.
Все ограничения первичного ключа (PRIMARY KEY), действующие в таблицах-элементах, должны быть связаны с одинаковым количеством столбцов.
Всем таблицам-элементам в представлении должно быть назначено одинаковое значение заполнения ANSI. Его можно задать либо при помощи аргумента user options процедуры sp_configure, либо при помощи инструкции SET.