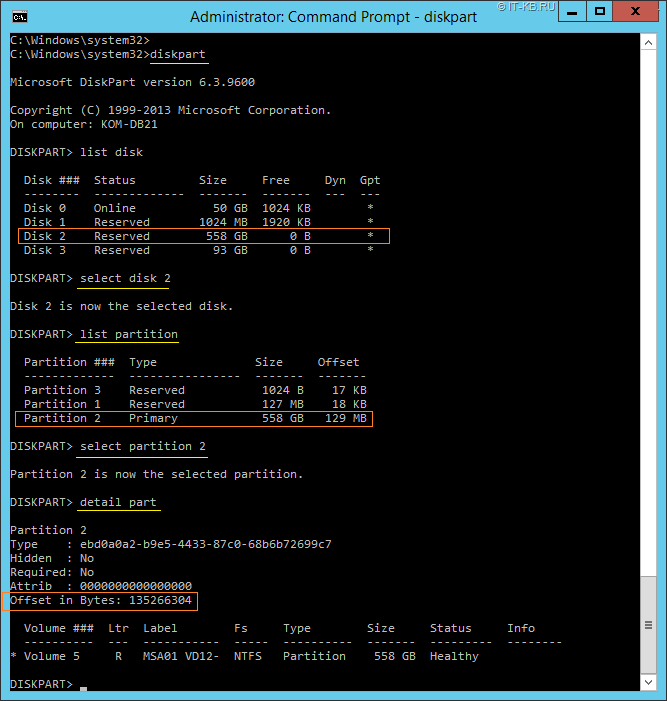
Чтобы не забыть и впоследствии освежить память
Чтобы изменить значение в поле в таблице БД необходимо выполнить запрос UPDATE.
Общий синтаксис запроса UPDATE
UPDATE заменит значения текущих полей таблицы на новые значения. SET устанавливает какие поля изменять и новые значения, которые нужно присвоить этим полям. WHERE (если необходимо) — условие на изменение определенных записей. Если WHERE не указан, изменены будут все записи. При указании параметра LOW_PRIORITY, выполнение UPDATE задержится пока другие клиенты читают таблицу.
Пример запроса на изменение всех записей поля «apple» таблицы «fruit» на определенное значение
Пример запроса с WHERE который изменяет определенную запись:
При изменении значения поля можно использовать его текущее значение. Пример запроса увеличивающего значение поля price в 2 раза:
SET в UPDATE вычисляет выражения слева направо. Пример запроса который удваивает цену (поле price), а потом уменьшает его на 10:
Запрос UPDATE возвратит количество полей, которые были изменены в этом запросе. Использование LIMIT позволит изменять заданное количество записей.
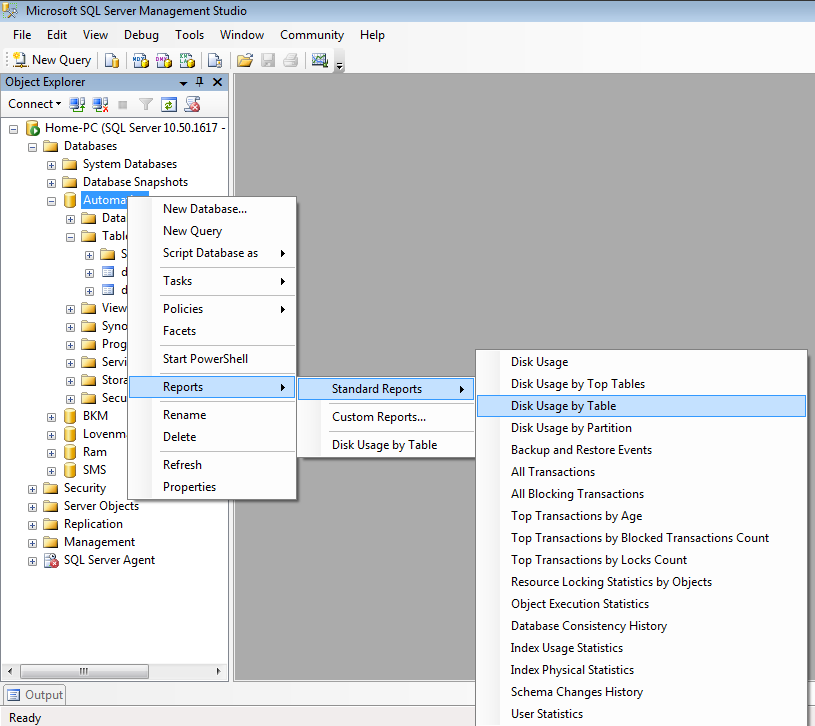
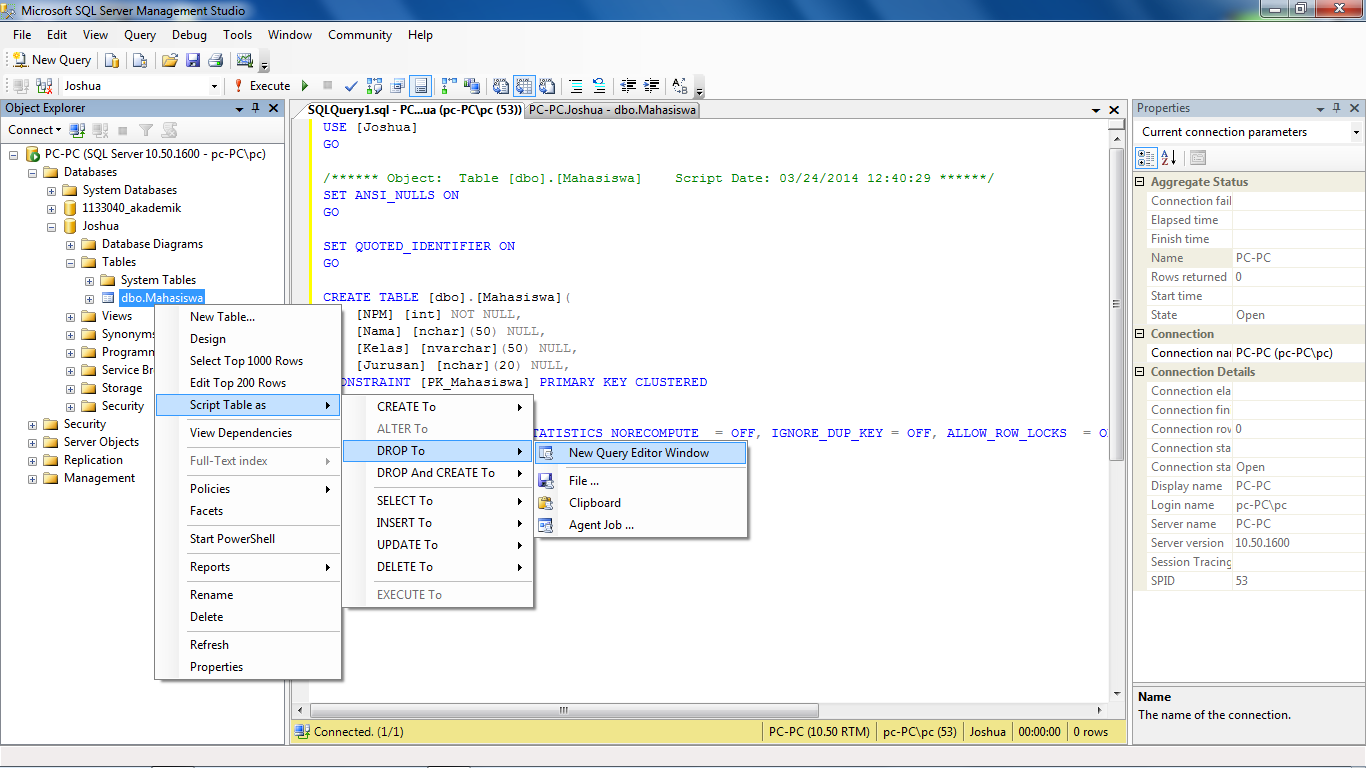
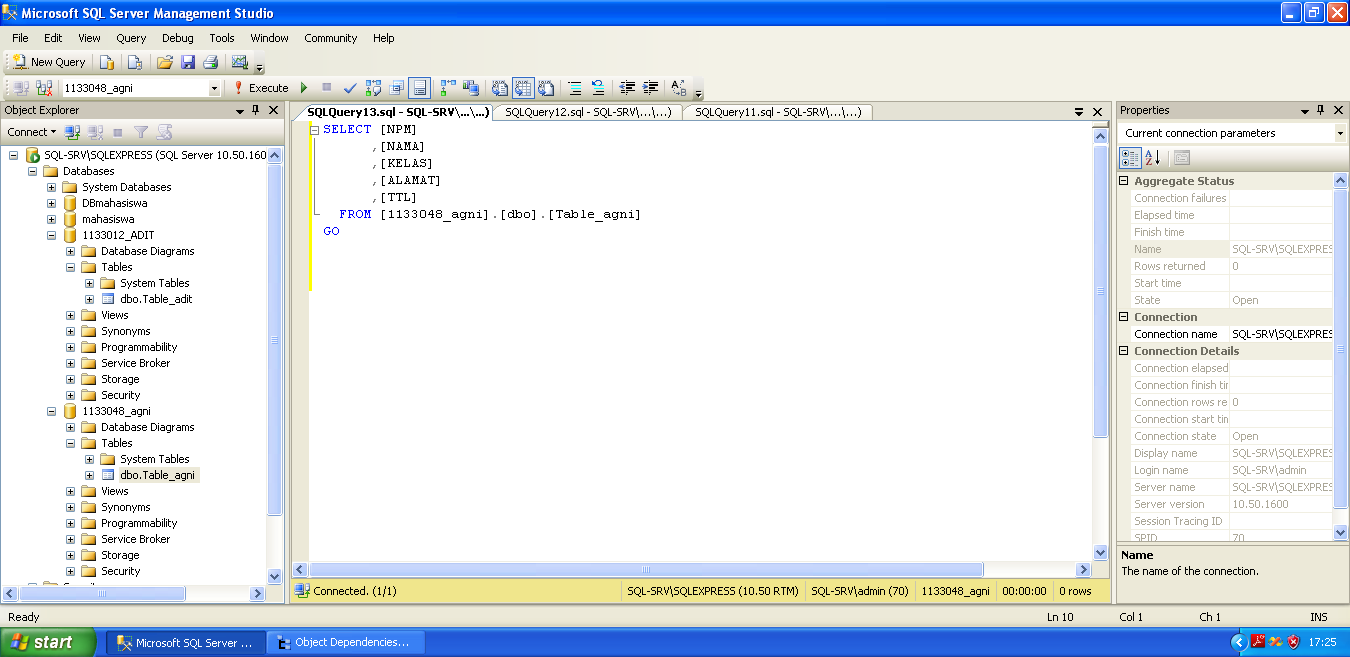
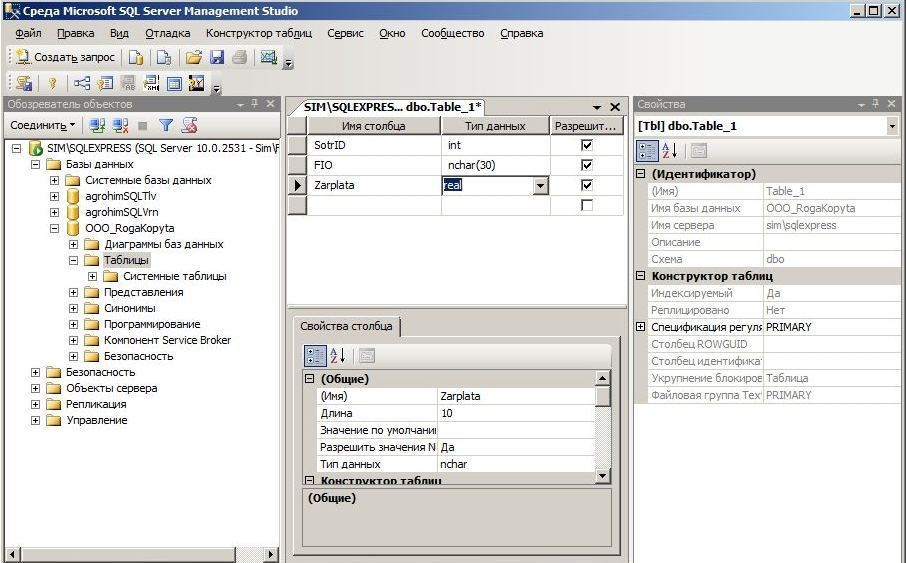
В этом материале я покажу, как вносятся изменения в таблицы в Microsoft SQL Server, под изменениями здесь подразумевается добавление новых столбцов, удаление или изменение характеристик уже существующих столбцов в таблице. По традиции я покажу, как это делается в графическом конструкторе среды SQL Server Management Studio и, конечно же, как это делается на языке T-SQL.

Напомню, в прошлых статьях я показывал, как создаются базы данных в Microsoft SQL Server, а также как создаются новые таблицы. Сегодня Вы узнаете, как изменить уже существующие таблицы в Microsoft SQL Server, при этом, как было уже отмечено, будет рассмотрено два способа изменения таблиц: первый – с помощью SQL Server Management Studio (SSMS), и второй – с помощью T-SQL.
Также я расскажу о некоторых нюансах и проблемах, которые могут возникнуть в процессе изменения таблиц, что, на самом деле, характерно для большинства случаев.
Точность, масштаб и длина (Transact-SQL)
Точность представляет собой количество цифр в числе. Масштаб представляет собой количество цифр справа от десятичной запятой в числе. Например: число 123,45 имеет точность 5 и масштаб 2.
В среде SQL Server максимальная точность типов данных numeric и decimal по умолчанию составляет 38 разрядов. В более ранних версиях SQL Server максимум по умолчанию составляет 28.
Длиной для числовых типов данных является количество байт, используемых для хранения числа. Длина символьной строки или данных в Юникоде равняется количеству символов. Длина для типов данных binary, varbinary и image равна количеству байт. Например, тип данных int может содержать 10 разрядов, храниться в 4 байтах и не должен содержать десятичный разделитель. Тип данных int имеет точность 10, длину 4 и масштаб 0.
При сцеплении двух выражений типа char, varchar, binary или varbinary длина результирующего выражения является суммой длин двух исходных выражений, но не превышает 8 000 символов.
При сцеплении двух выражений типа nchar или nvarchar длина результирующего выражения является суммой длин двух исходных выражений, но не превышает 4 000 символов.
Если два выражения одного и того же типа данных, но разной длины, сравниваются с помощью предложения UNION, EXCEPT или INTERSECT, длина результата будет равняться длине максимального из двух выражений.
Точность и масштаб числовых типов данных, кроме decimal, фиксированы. Если арифметический оператор объединяет два выражения одного и того же типа, результат будет иметь тот же тип данных с точностью и масштабом, определенными для этого типа. Если оператор объединяет два выражения с различными числовыми типами данных, тип данных результата будет определяться правилами старшинства типов данных. Результат имеет точность и масштаб, определенные для этого типа данных.
Следующая таблица определяет, как вычисляется точность и масштаб результата, если результат операции имеет тип decimal. Результат имеет тип decimal, если одно из следующих утверждений является истиной:
- Оба выражения имеют тип decimal.
- Одно выражение имеет тип decimal, а другое имеет тип данных со старшинством меньше, чем decimal.
Выражения операндов обозначены как выражение e1 с точностью p1 и масштабом s1 и выражение e2 с точностью p2 и масштабом s2. Точность и масштаб для любого выражения, отличного от decimal, соответствуют типу данных этого выражения
| Операция | Точность результата | Масштаб результата * |
|---|---|---|
| e1 + e2 | max(s1, s2) + max(p1-s1, p2-s2) + 1 | max(s1, s2) |
| e1 — e2 | max(s1, s2) + max(p1-s1, p2-s2) + 1 | max(s1, s2) |
| e1 * e2 | p1 + p2 + 1 | s1 + s2 |
| e1 / e2 | p1 — s1 + s2 + max(6, s1 + p2 + 1) | max(6, s1 + p2 + 1) |
| e1 { UNION | EXCEPT | INTERSECT } e2 | max(s1, s2) + max(p1-s1, p2-s2) | max(s1, s2) |
| e1 % e2 | min(p1-s1, p2 -s2) + max( s1,s2 ) | max(s1, s2) |
* Точность и масштаб результата имеют абсолютный максимум, равный 38. Если значение точности превышает 38, то соответствующее значение масштаба уменьшается, чтобы по возможности предотвратить усечение целой части результата.
Example 3 – Create a Table that Uses the Alias
In this example I create a table that uses my newly created data type alias in one of its column definitions.
USE Test;
CREATE TABLE Client
(
ClientCode clientcode PRIMARY KEY,
FirstName varchar(50),
LastName varchar(50)
);
We can take a quick look at the columns in the table:
SELECT c.name, c.system_type_id, c.user_type_id, c.max_length, c.is_nullable FROM sys.columns c INNER JOIN sys.tables t ON t.object_id = c.object_id WHERE t.name = 'Client';
Results:
+------------+------------------+----------------+--------------+---------------+ | name | system_type_id | user_type_id | max_length | is_nullable | |------------+------------------+----------------+--------------+---------------| | ClientCode | 167 | 257 | 8 | 0 | | FirstName | 167 | 167 | 50 | 1 | | LastName | 167 | 167 | 50 | 1 | +------------+------------------+----------------+--------------+---------------+
There are many more columns of data but I’ve narrowed it down to just some that are relevant to this article.
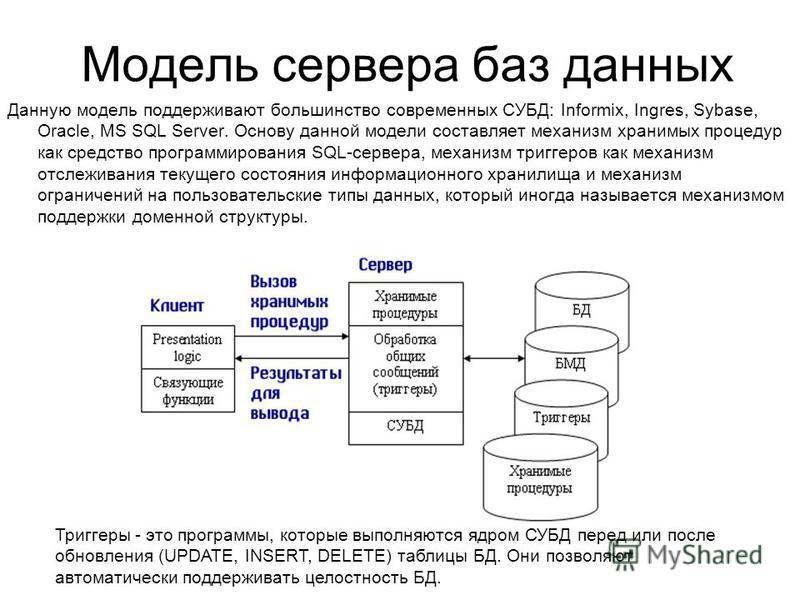
Файловые группы
- Эта файловая группа содержит первичный файл данных и все вторичные файлы, не входящие в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, , и могут быть созданы на трех дисках соответственно и отнесены к файловой группе . В этом случае можно создать таблицу на основе файловой группы . Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
| Файловая группа | Описание |
|---|---|
| Первичная | Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. |
| Данные, оптимизированные для памяти | В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. |
| Файловый поток | |
| Определяемые пользователем маршруты | Любая файловая группа, созданная пользователем при создании или изменении базы данных. |
Файловая группа по умолчанию (первичная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Файловая группа данных, оптимизированных для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Файловая группа файлового потока
Дополнительные сведения о файловых группах файлового потока см. в статьях и Создание базы данных с поддержкой FILESTREAM.
Пример файлов и файловых групп
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Инструкция ALTER DATABASE придает пользовательской файловой группе статус файловой группы по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к , чтобы не указывать версию SQL Server.)
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).
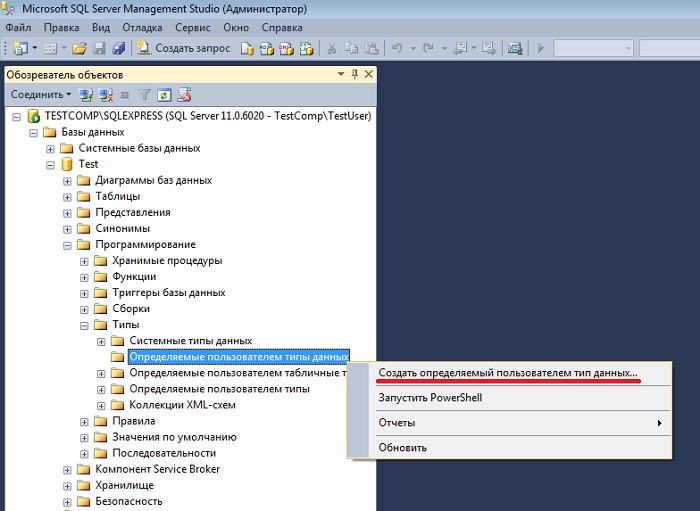
Создание пользовательского типа данных
В системе SQL-сервера имеется поддержка пользовательских типов данных. Они могут использоваться при определении какого-либо специфического или часто употребляемого формата.
Создание пользовательского типа данных осуществляется выполнением системной процедуры:
sp_addtype type, system_data_type ’null_type’]
Тип данныхsystem_data_type выбирается из следующей таблицы.
| image | smalldatetime | decimal | bit |
| text | real | ‘decimal)]’ | ‘binary(n)’ |
| uniqueidentifier | datetime | numeric | ‘char(n)’ |
| smallint | float | ‘numeric)]’ | ‘nvarchar(n)’ |
| int | ‘float(n)’ | ‘varbinary(n)’ | |
| ntext | ‘varchar(n)’ | ‘nchar(n)’ |
EXEC sp_addtype bir, DATETIME, ‘NULL’ или EXEC sp_addtype bir, DATETIME, ‘NOT NULL’2.1. Создание пользовательского типа данных bir.CREATE TABLE tab (id_n INT IDENTITY(1,1) PRIMARY KEY, names VARCHAR(40), birthday BIR)2.2. Использование пользовательского типа данных bir при создании таблицы.


Удаление пользовательского типа данных происходит в результате выполнения процедуры sp_droptype type: EXEC sp_droptype ‘bir’
Получение информации о типах данных
Получить список всех типов данных, включая пользовательские, можно из системной таблицы systypes:
SELECT * FROM systypes
Преобразование типов
Нередко требуется конвертировать значения одного типа в значения другого. Наиболее часто выполняется конвертирование чисел в символьные данные и наоборот, для этого используется специализированная функция STR. Для выполнения других преобразований SQL Server предлагает универсальные функции CONVERT и CAST, с помощью которых значения одного типа преобразовываются в значения другого типа, если такие изменения вообще возможны. CONVERT и CAST примерно одинаковы и могут быть взаимозаменяемыми.
CAST(выражение AS тип_данных) CONVERT(тип_данных, выражение )
С помощью аргумента стиль можно управлять стилем представления значений следующих типов данных: дата/время, денежный или нецелочисленный.
DECLARE @d DATETIME DECLARE @s CHAR(8) SET @s=’29.10.01’ SET @d=CAST(@s AS DATETIME)2.3. Преобразование данных символьного типа к данным типа дата/время.
Наряду с типами данных основополагающими понятиями при работе с языком SQL в среде MS SQL Server являются выражения, операторы, переменные, управляющие конструкции.
Что такое Laravel UUID?
В UUID (Универсально уникальный идентификатор) — это идентификатор, который можно присвоить строкам таблицы, чтобы идентифицировать их более удобным способом, чем последовательный идентификатор таблицы.
Безопасны ли UUID? «уникальный» означает никогда не сталкиваться. Если у него и есть потенциал столкнуться, то он не уникален. Поэтому по определению UUID не уникален, и безопасно, только если вы готовы к возможным столкновениям независимо от вероятности столкновений. В противном случае ваша программа просто неверна.
Для чего используются GUID?
(Globally Unique IDentifier) Реализация универсального уникального идентификатора (см. UUID), который вычисляется Windows и приложениями Windows. Используя псевдослучайное 128-битное число, идентификаторы GUID используются для идентифицировать учетные записи пользователей, документы, программное обеспечение, оборудование, программные интерфейсы, сеансы, ключи базы данных и другие элементы.
Как вы генерируете GUID? Сопоставление компонентов с GUID
- Преобразуйте имя в байты. …
- Преобразуйте пространство имен в байты. …
- Объедините их и хэш, используя правильный метод хеширования. …
- Разбейте хеш на основные компоненты: GUID, временную метку, тактовую последовательность и идентификатор узла. …
- Вставьте компонент timestamp в GUID: 2ed6657de927468b.
Как глобально уникальны идентификаторы GUID?
Глобальные уникальные идентификаторы (GUID, иногда называемые универсальными уникальными идентификаторами или UUID) 128-битные числа, используемые для идентификации цифровой информации, помогая однозначно ссылаться на них. Случайный: Генератор случайных чисел создает 128-битное число. … На основе времени: на основе текущего времени.
Что такое значение GUID? Тип данных глобального уникального идентификатора (GUID) в SQL Server представлен типом данных uniqueidentifier, в котором хранится 16-байтовое двоичное значение. GUID — это двоичное число, и его основное использование идентификатор, который должен быть уникальным в сети, в которой много компьютеров на многих сайтов.
Всегда ли идентификаторы GUID имеют одинаковую длину?
Так что ответ «да», всегда будет одинаковая длина. Что касается 4, то это номер версии (согласно http://en.wikipedia.org/wiki/Uuid). Каждый GUID, который вы создаете с помощью этого алгоритма, будет иметь 4 в этой позиции, но более старые GUID будут иметь 1, 2 или 3.
1.5.1. DEFAULT
Ограничение DEFAULT помещает значение в колонку, когда оно не было указано в операторе INSERT. Оно относится только к оператору добавления записи (INSERT) и не срабатывает во время изменения полей (оператор UPDATE). Таким образом, данное ограничение не гарантирует, что поле содержит значение. Пользователь может добавить строку и потом с помощью UPDATE обнулить содержимое поле со значением по умолчанию.
Таким образом, DEFAUL является самым простым и быстрым по скорости выполнения методом обеспечения целостности, но не является гарантом. Необходимы дополнительные средства, например, ограничение на диапазон вводимых значений или триггер. Например, в листинге 1.10, помимо значения DEFAULT мы создаем ограничение, которое не позволяет записывать в поле нулевые значения, что защитит нас от возможности записи в поле NULL даже при обновлении данных:
Листинг 1.10. Создание таблицы с ограничением DEFAULT и CHECK
-- Создание таблицы CREATE TABLE TestTable ( iID int DEFAULT 1, CONSTRAINT check_iID CHECK (iID is NOT NULL) ) -- Добавление записи с числом 10 в колонке iID INSERT INTO TestTable VALUES (10) -- Обновление существующих записей, в поле iID -- записывается нулевое значение UPDATE TestTable SET iID=NULL
В данном примере мы устанавливаем сразу два ограничения на поле «iID» таблицы TestTable. Первое DEFAULT устанавливает значение по умолчанию, если во время добавления записи для поля «iID» не было указано значения. Вторая проверка CHECK не позволит сделать поле нулевым с помощью операции обновления записей.
После этого в листинге показаны примеры добавления и обновления записи. Во время обновления мы пытаемся записать в поле значение NULL. В ответ на это сервер вернет нам ошибку и сообщит, что сработало ограничение check_iID.
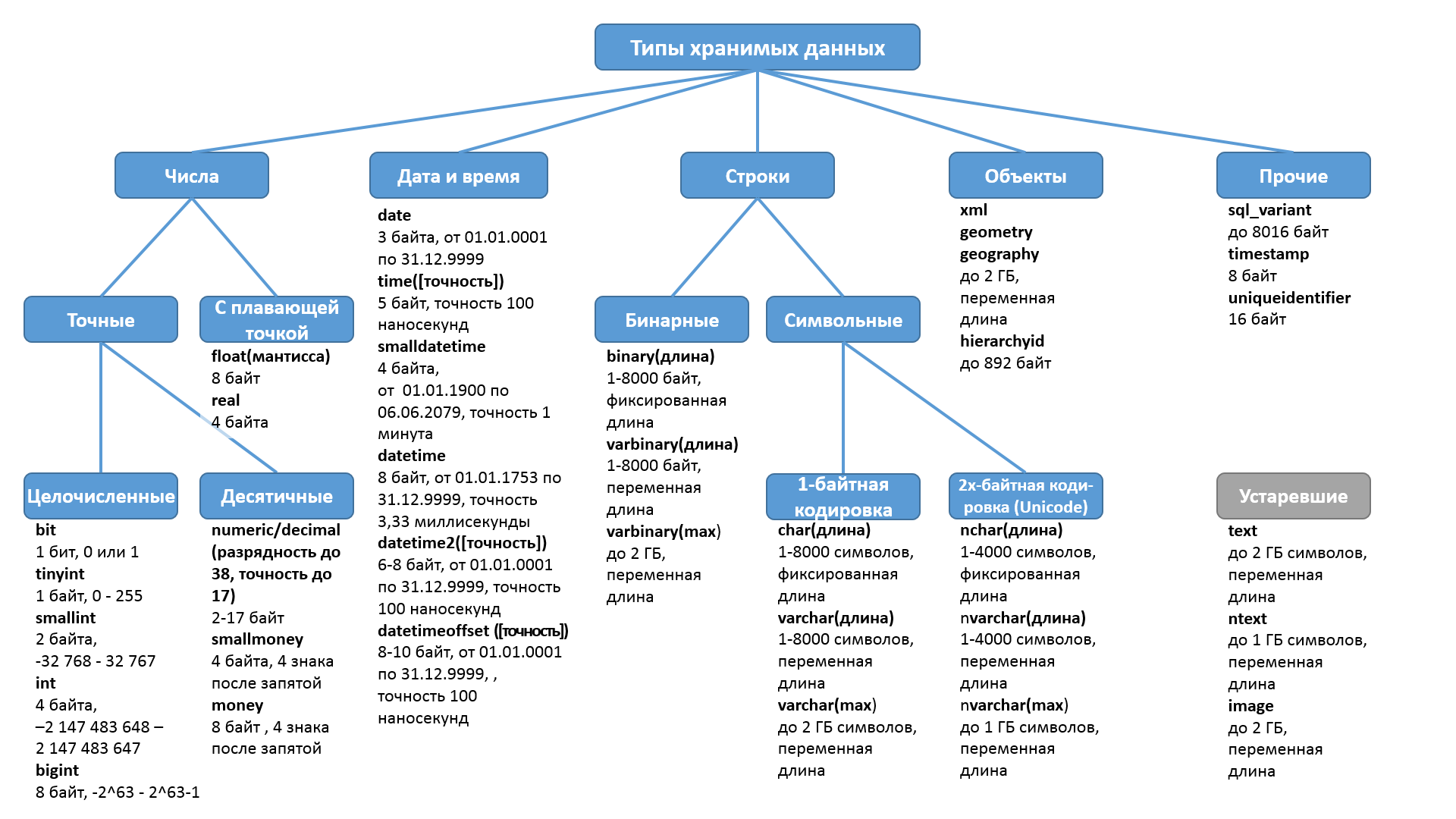
Что такое тип данных в SQL Server?
Тип данных – это характеристика, определяющая, какого рода данные будут храниться в объекте. Например: целые числа, числовые данные с плавающей запятой, данные денежного типа, дата, время, текст, двоичные данные и так далее. У каждого столбца, выражения, переменной или параметра есть определенный тип данных. В Microsoft SQL Server существует набор системных типов данных, который и определяет все доступные по умолчанию типы данных для использования. У разработчиков также существует возможность создавать псевдонимы типов данных основанные на системных типах, а также собственные пользовательские типы данных, о том, как реализовать псевдоним типа данных, мы разговаривали в материале – «Создание псевдонима типа данных в Microsoft SQL Server на T-SQL».
Типы данных в MS SQL Server делятся на следующие категории:
- Точные числа;
- Приблизительные числа;
- Символьные строки;
- Символьные строки в Юникоде;
- Дата и время;
- Двоичные данные;
- Прочие типы данных.
Условный оператор WHERE
Ситуация, когда требуется сделать выборку по определенному условию, встречается очень часто. Для этого в операторе SELECT существует параметр WHERE, после которого следует условие для ограничения строк. Если запись удовлетворяет этому условию, то попадает в результат, иначе отбрасывается.
Общая структура запроса с оператором WHERE
SELECT поля_таблиц FROM список_таблиц WHERE условия_на_ограничения_строк ;
В описанной структуре запроса необязательные параметры указаны в квадратных скобках.
В условном операторе применяются операторы сравнения, специальные и логические операторы.
Операторы сравнения
Операторы сравнения служат для сравнения 2 выражений, их результатом может являться ИСТИНА (1), ЛОЖЬ (0) и NULL.
| Оператор | Описание |
|---|---|
| = | Оператор равенство |
| <=> | Оператор эквивалентностьАналогичный оператору равенства, с одним лишь исключением: в отличие от него, оператор эквивалентности вернет ИСТИНУ при сравнении NULL <=> NULL |
| <>или!= | Оператор неравенство |
| < | Оператор меньше |
| <= | Оператор меньше или равно |
| > | Оператор больше |
| >= | Оператор больше или равно |
Специальные операторы
-
— позволяет узнать равно ли проверяемое значение NULL.
Для примера выведем всех членов семьи, у которых статус в семье не равен NULL:
SELECT * FROM FamilyMembers WHERE status IS NOT NULL; -
— позволяет узнать расположено ли проверяемое значение столбца в интервале между min и max.
Выведем все данные о покупках с ценой от 100 до 500 рублей из таблицы Payments:
SELECT * FROM Payments WHERE unit_price BETWEEN 100 AND 500; -
— позволяет узнать входит ли проверяемое значение столбца в список определённых значений.
Выведем имена членов семьи, чей статус равен «father» или «mother»:
SELECT member_name FROM FamilyMembers WHERE status IN ('father', 'mother'); -
— позволяет узнать соответствует ли строка определённому шаблону.
Например, выведем всех людей с фамилией «Quincey»:
SELECT member_name FROM FamilyMembers WHERE member_name LIKE '% Quincey';
Трафаретные символы
В шаблоне разрешается использовать два трафаретных символа:
- символ подчеркивания (_), который можно применять вместо любого единичного символа в проверяемом значении
- символ процента (%) заменяет последовательность любых символов (число символов в последовательности может быть от 0 и более) в проверяемом значении.
| Шаблон | Описание |
|---|---|
| never% | Сопоставляется любым строкам, начинающимся на «never». |
| %ing | Сопоставляется любым строкам, заканчивающимся на «ing». |
| _ing | Сопоставляется строкам, имеющим длину 4 символа, при этом 3 последних обязательно должны быть «ing». Например, слова «sing» и «wing». |
ESCAPE-символ
ESCAPE-символ используется для экранирования трафаретных символов. В случае если вам нужно найти строки, содержащие проценты (а процент — это зарезервированный символ), вы можете использовать ESCAPE-символ.


Например, вы хотите получить идентификаторы задач, прогресс которых равен 3%:
SELECT
job_id
FROM
Jobs
WHERE
progress LIKE '3!%'
ESCAPE '!';
Если бы мы не экранировали трафаретный символ, то в выборку попало бы всё, что начинается на 3.
Логические операторы
Логические операторы необходимы для связывания нескольких условий ограничения строк.
- Оператор NOT — меняет значение специального оператора на противоположный
- Оператор OR — общее значение выражения истинно, если хотя бы одно из них истинно
- Оператор AND — общее значение выражения истинно, если они оба истинны
- Оператор XOR — общее значение выражения истинно, если один и только один аргумент является истинным
Выведем все полёты, которые были совершены на самолёте «Boeing», но, при этом, вылет был не из Лондона:
SELECT
*
FROM
Trip
WHERE
plane = 'Boeing' AND NOT town_from = 'London';
Пример псевдоним для имени таблицы
Когда вы создаете псевдоним таблицы, это происходит потому, что вы планируете перечислить одно и то же имя таблицы более одного раза в FROM, или вы хотите сократить имя таблицы, чтобы сделать SQL оператор короче и проще для чтения.
Давайте рассмотрим пример псевдонима имени таблицы в SQL.
В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
И таблица с именем categories со следующими данными:
| category_id | category_name |
|---|---|
| 25 | Deli |
| 50 | Produce |
| 75 | Bakery |
| 100 | General Merchandise |
| 125 | Technology |
Теперь давайте объединим эти 2 таблицы и псевдонимы каждого из имен таблиц. Введите следующий SQL оператор:
PgSQL
SELECT p.product_name, c.category_name
FROM products AS p
INNER JOIN categories AS c
ON p.category_id = c.category_id
WHERE p.product_name <> ‘Pear’;
|
1 |
SELECTp.product_name,c.category_name FROMproductsASp INNER JOINcategoriesASc ONp.category_id=c.category_id WHEREp.product_name<>’Pear’; |
Будет выбрано 5 записей. Вот результаты, которые вы получите:
| product_name | category_name |
|---|---|
| Banana | Produce |
| Orange | Produce |
| Apple | Produce |
| Bread | Bakery |
| Sliced Ham | Deli |
В этом примере мы создали псевдоним для таблицы products и псевдоним для таблицы category. Теперь в рамках этого SQL оператора мы можем ссылаться на таблицу products как p, а на таблицу category — как c.
При создании псевдонимов таблиц нет необходимости создавать псевдонимы для всех таблиц, перечисленных в предложении FROM. Вы можете создать псевдонимы для любой или всех таблиц.
Рекомендации по созданию и использованию рекурсивных обобщенных табличных выражений
Следующие рекомендации применимы к определению рекурсивных обобщенных табличных выражений.
Определение рекурсивного обобщенного табличного выражения должно содержать по крайней мере два определения обобщенного табличного выражения запросов — закрепленный элемент и рекурсивный элемент. Может быть определено несколько закрепленных элементов и рекурсивных элементов, однако все определения запросов закрепленного элемента должны быть поставлены перед первым определением рекурсивного элемента. Все определения обобщенных табличных выражений запросов (ОТВ) являются закрепленными элементами, если только они не ссылаются на само ОТВ.
Закрепленные элементы должны объединяться одним из следующих операторов над множествами: UNION ALL, UNION, INTERSECT или EXCEPT. UNION ALL является единственным оператором над множествами, который может находиться между последним закрепленным элементом и первым рекурсивным элементом, а также может применяться при объединении нескольких рекурсивных элементов.
Количество столбцов членов указателя и рекурсивных элементов должно совпадать.
Тип данных столбца в рекурсивном элементе должен совпадать с типом данных соответствующего столбца в закрепленном элементе.
Предложение FROM рекурсивного элемента должно ссылаться на обобщенное табличное выражение expression_name только один раз.
Следующие элементы недопустимы в определении CTE_query_definition рекурсивного элемента:
PIVOT (Если уровень совместимости базы данных имеет значение 110 или больше. См. раздел Критические изменения в функциях компонента ядра СУБД в SQL Server 2016).
LEFT , RIGHT , OUTER JOIN ( INNER JOIN допускается)
Указание, применимое к рекурсивной ссылке на обобщенное табличное выражение в определении CTE_query_definition.
Следующие рекомендации применимы к использованию рекурсивных обобщенных табличных выражений.
Все столбцы, возвращаемые рекурсивным обобщенным табличным выражением, могут содержать значения NULL, независимо от того, могут ли иметь значения NULL столбцы, возвращаемые участвующими инструкциями SELECT .
Неправильно составленное рекурсивное ОТВ может привести к бесконечному циклу. Например, если определение запроса рекурсивного элемента возвращает одинаковые значения как для родительского, так и для дочернего столбца, то образуется бесконечный цикл. Для предотвращения бесконечного цикла можно ограничить количество уровней рекурсии, допустимых для определенной инструкции, при помощи указания MAXRECURSION и значения в диапазоне от 0 до 32 767 в предложении OPTION инструкции INSERT , UPDATE , DELETE или SELECT . Это дает возможность контролировать выполнение инструкции до тех пор, пока не будет разрешена проблема с кодом, из-за которой происходит зацикливание программы. Серверное значение по умолчанию равно 100. Если указано значение 0, ограничения не применяются. В одной инструкции может быть указан только одно значение MAXRECURSION . Дополнительные сведения см. в разделе Указания запросов (Transact-SQL).
Представление, содержащее рекурсивное обобщенное табличное выражение, не может использоваться для обновления данных.
Курсоры могут определяться на запросах при помощи обобщенных табличных выражений. Обобщенное табличное выражение является аргументом select_statement, который определяет результирующий набор курсора. Для рекурсивных обобщенных табличных выражений допустимы только однонаправленные и статические курсоры (курсоры моментального снимка). Если в рекурсивном обобщенном табличном выражении указан курсор другого типа, тип курсора преобразуется в статический.
В обобщенном табличном выражении могут быть ссылки на таблицы, находящиеся на удаленных серверах. Если на удаленный сервер имеются ссылки в рекурсивном элементе обобщенного табличного выражения, создается буфер для каждой удаленной таблицы, так что к таблицам может многократно осуществляться локальный доступ. Если это запрос обобщенного табличного выражения, Index Spool/Lazy Spools отображается в плане запроса и будет иметь дополнительный предикат WITH STACK . Это один из способов подтверждения надлежащей рекурсии.
Аналитические и агрегатные функции в рекурсивной части обобщенных табличных выражений применяются для задания текущего уровня рекурсии, а не для задания обобщенных табличных выражений. Такие функции, как ROW_NUMBER , работают только с подмножествами данных, которые передаются им текущим уровнем рекурсии, но не со всем множеством данных, которые передаются в рекурсивную часть обобщенного табличного выражения. Дополнительные сведения см. в примере «Л. Использование аналитических функций в рекурсивном ОТВ» ниже.
Системы реляционных баз данных
Компонент Database Engine сервера Microsoft SQL Server является системой реляционных баз данных. Понятие систем реляционных баз данных было впервые введено в 1970 г. Эдгаром Ф. Коддом в статье «A Relational Model of Data for Large Shared Data Banks». В отличие от предшествующих систем баз данных (сетевых и иерархических), реляционные системы баз данных основаны на реляционной модели данных, обладающей мощной математической теорией.
Модель данных — это набор концепций, взаимосвязей между ними и их ограничений, которые используются для представления данных в реальной задаче. Центральным понятием реляционной модели данных является таблица. Поэтому, с точки зрения пользователя, реляционная база данных содержит только таблицы и ничего больше. Таблицы состоят из столбцов (одного или нескольких) и строк (ни одной или нескольких). Каждое пресечение строки и столбца таблицы всегда содержит ровно одно значение данных.
Работа с демонстрационной базой данных в последующих статьях
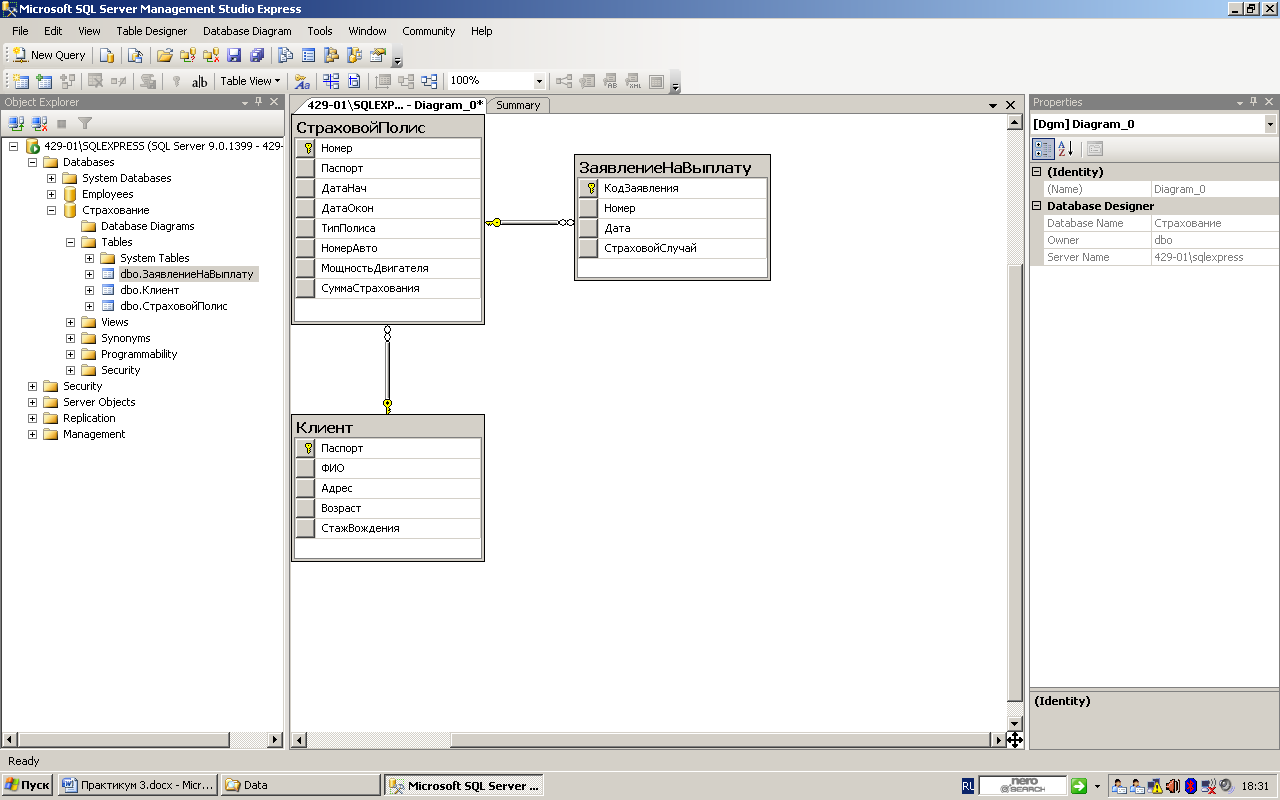
Используемая в наших статьях база данных SampleDb представляет некую компанию, состоящую из отделов (department) и сотрудников (employee). Каждый сотрудник принадлежит только одному отделу, а отдел может содержать одного или нескольких сотрудников. Сотрудники работают над проектами (project): в любое время каждый сотрудник занят одновременно в одном или нескольких проектах, а над каждым проектом может работать один или несколько сотрудников.
Эта информация представлена в базе данных SampleDb (находится в исходниках) посредством четырех таблиц:
Department Employee Project Works_on
Организация этих таблиц показана на рисунках ниже. Таблица Department представляет все отделы компании. Каждый отдел обладает следующими атрибутами (столбцами):
Department (Number, DepartmentName, Location)
Атрибут Number представляет однозначный номер каждого отдела, атрибут DepartmentName — его название, а атрибут Location — расположение. Таблица Employee представляет всех работающих в компании сотрудников. Каждый сотрудник обладает следующими атрибутами (столбцами):
Employee (Id, FirstName, LastName, DepartmentNumber)
Атрибут Id представляет однозначный табельный номер каждого сотрудника, атрибуты FirstName и LastName — имя и фамилию сотрудника соответственно, а атрибут DepartmentNumber — номер отдела, в котором работает сотрудник.
Все проекты компании представлены в таблице проектов Project, состоящей из следующих столбцов (атрибутов):
Project (ProjectNumber, ProjectName, Budget)
В столбце ProjectNumber указывается однозначный номер проекта, а в столбцах ProjectName и Budget — название и бюджет проекта соответственно.
В таблице Works_on указывается связь между сотрудниками и проектами:
Works_on (EmpId, ProjectNumber, Job, EnterDate)
В столбце EmpId указывается табельный номер сотрудника, а в столбце ProjectNumber — номер проекта, в котором он принимает участие. Комбинация значений этих двух столбцов всегда однозначна. В столбцах Job и EnterDate указывается должность и начало работы сотрудника в данном проекте соответственно.
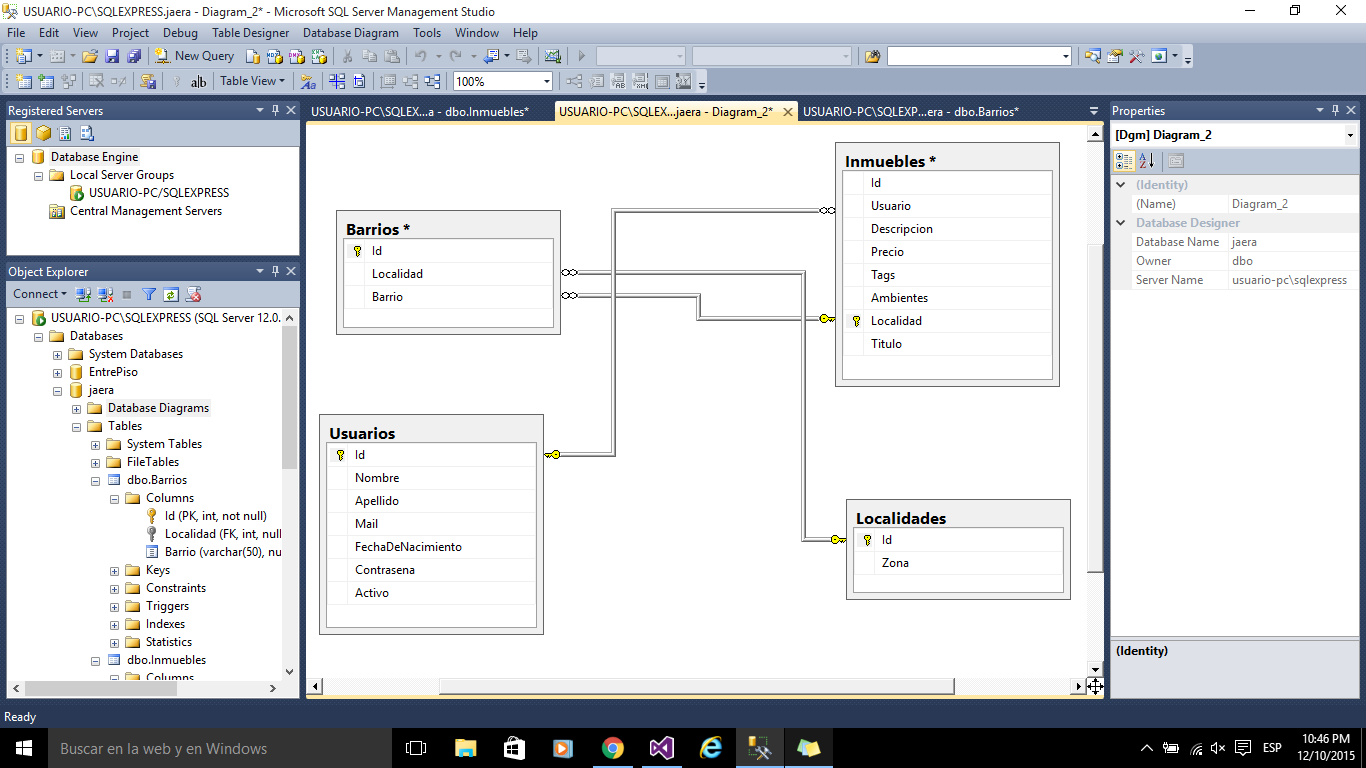

На примере базы данных SampleDb можно описать некоторые основные свойства реляционных систем баз данных:
-
Строки таблицы не организованы в каком-либо определенном порядке.
-
Также не организованы в каком-либо определенном порядке столбцы таблицы.
-
Каждый столбец таблицы должен иметь однозначное имя в любой данной таблице. Но разные таблицы могут содержать столбцы с одним и тем же именем. Например, таблица Department содержит столбец Number и столбец с таким же именем имеется в таблице Project.
-
Каждый элемент данных таблицы должен содержать одно значение. Это означает, что любая ячейка на пересечении строк и столбцов таблицы никогда не содержит какого-либо набора значений.
-
Каждая таблица содержит, по крайней мере, один столбец, значения которого определяют такое свойство, что никакие две строки не содержат одинаковой комбинации значений для всех столбцов таблицы. В реляционной модели данных такой столбец называться потенциальным ключом (candidate key). Если таблица содержит несколько потенциальных ключей, разработчик указывает один из них, как первичный ключ (primary key) данной таблицы. Например, первичным ключом таблицы Department будет столбец Number, а первичными ключами таблиц Employee будет Id. Наконец, первичным ключом таблицы Works_on будет комбинация столбцов EmpId и ProjectNumber.
-
Таблица никогда не содержит одинаковых строк. Но это свойство существует только в теории, т.к. компонент Database Engine и все другие реляционные системы баз данных допускают существование в таблице одинаковых строк.
Тип данных CHAR
Тип данных определяет строку фиксированной длины. При объявлении такой строки необходимо задать ее максимальную длину в диапазоне от 1 до 32 767 байт. Длина может задаваться как в байтах, так и в символах. Например, следующие два объявления создают строки длиной 100 байт и 100 символов соответственно:
feature_name CHAR(100 BYTE); feature_name CHAR(100 CHAR);
Реальный размер 100-символьной строки в байтах зависит от текущего набора символов базы данных. Если используется набор символов с переменной длиной кодировки, PL/SQL выделяет для строки столько места, сколько необходимо для представления заданного количества символов с максимальным количеством байтов. Например, в наборе UTF-8, где символы имеют длину от 1 до 4 байт, PL/SQL при создании строки для хранения 100 символов зарезервирует 300 байт (3 байта ? 100 символов).
Мы уже знаем, что при отсутствии спецификатора или результат будет зависеть от параметра . При компиляции программы эта настройка сохраняется вместе с ней и может использоваться повторно или заменяться при последующей перекомпиляции. С настройкой по умолчанию для следующего объявления будет создана строка длиной 100 байт:
feature_name CHAR(100);
Если длина строки не указана, PL/SQL объявит строку длиной 1 байт. Предположим, переменная объявляется так:
feature_name CHAR;
Как только этой переменной присваивается строка длиной более одного символа, PL/SQL инициирует универсальное исключение . Но при этом не указывается, где именно возникла проблема. Если эта ошибка была получена при объявлении новых переменных или констант, проверьте свои объявления на небрежное использование . Чтобы избежать проблем и облегчить работу программистов, которые придут вам на смену, всегда указывайте длину строки типа . Несколько примеров:
yes_or_no CHAR (1) DEFAULT 'Y'; line_of_text CHAR (80 CHAR); ----- Всегда все 80 символов! whole_paragraph CHAR (10000 BYTE); -- Подумайте обо всех этих пробелах...
Поскольку строка типа имеет фиксированную длину, PL/SQL при необходимости дополняет справа присвоенное значение пробелами, чтобы фактическая длина соответствовала максимальной, указанной в объявлении.
До выхода версии 12c максимальная длина типа данных в SQL была равна 2000; в 12c она была увеличена до максимума PL/SQL: 32 767 байт. Однако следует учитывать, что SQL поддерживает этот максимум только в том случае, если параметру инициализации задано значение .
О каких сравнениях идет речь?
Представление данных в СУБД сказывается на тех сравнениях, которые выполняются средствами СУБД. Среди них:
все операции сравнения, группировки и упорядочивания, используемые в запросах. В приведенном примере раздел ПО содержит сравнение двух полей на равенство, исполнение которого будет зависеть от типа реквизита «Ответственный» документа » ЗарплатаКВыплате «:
ВЫБРАТЬ ВЫРАЗИТЬ(ЗарплатаКВыплате.Ответственный КАК Справочник.Пользователи).Представление ИЗ Документ.ЗарплатаКВыплате КАК ЗарплатаКВыплате
операции сравнения в SQL-запросах, порождаемых различными объектами, встроенными в 1С:Предприятие. Приведенный пример в явном виде запросов не содержит, однако исполнение этого оператора приведет к построению и исполнению SQL-запроса к базе данных, содержащего операции сравнения.
ВыборкаФильтров = Справочники.ФильтрыДляЭлектронныхПисем.Выбрать(,
УчетнаяЗапись, Новый Структура("Использование", Истина), "Порядок ВОЗР");
Сравнение значений во встроенном языке 1С:Предприятия не вызывает обращений к СУБД и не зависит от представления в СУБД участвующих в них данных.