1.5.5. Отключение ограничений
Для повышения производительности, иногда разумно отключить ограничения. Для примера, более эффективно позволить выполнить большую операцию обновления или вставки данных, без ограничений.
Когда вы определяете ограничение на таблицу, которая уже содержит данные, MS SQL Server проверяет данные автоматически, гарантируя, что после создания ограничения, существующие данные соответствуют требованиям.
Отключать можно только ограничения CHECK и FOREIGN KEY. Другие ограничения должны быть удалены и потом снова добавлены.
Для отключения проверки, когда вы добавляете ограничения CHECK и FOREIGN KEY на таблицу с существующими данными, включите опцию WITH NOCHECK в оператор ALTER TABLE.
В следующем примере, мы добавляем ограничение FOREING KEY. Ограничение не проверяет существующие данные на момент добавления ограничения:
ALTER TABLE TestTable WITH NOCHECK ADD CONSTRAINT FK_TestTable FOREIGN KEY (Field1) REFERENCES PrimaryTable(Field2)
Вы можете отключить проверку ограничений на существующие ограничения CHECK и FOREIGN KEY так, что любые данные, которые вы изменяете или добавляете в таблицу, не проверяются с ограничением. Вы можете захотеть отключить проверку ограничений когда:
- вы уже убедились, что данные соответствуют требованиям;
- вы хотите загрузить данные, которые не соответствуют ограничению. Позже, вы можете выполнить запрос для изменения данных и включить ограничение.
Включение ограничения, которое было отключено, требует выполнения другого оператора ALTER TABLE, которое содержит опцию CHECK или CHECK ALL.
ALTER TABLE имя таблицы
{CHECK | NOCHECK} CONSTRAINT
{ALL | ограничение }
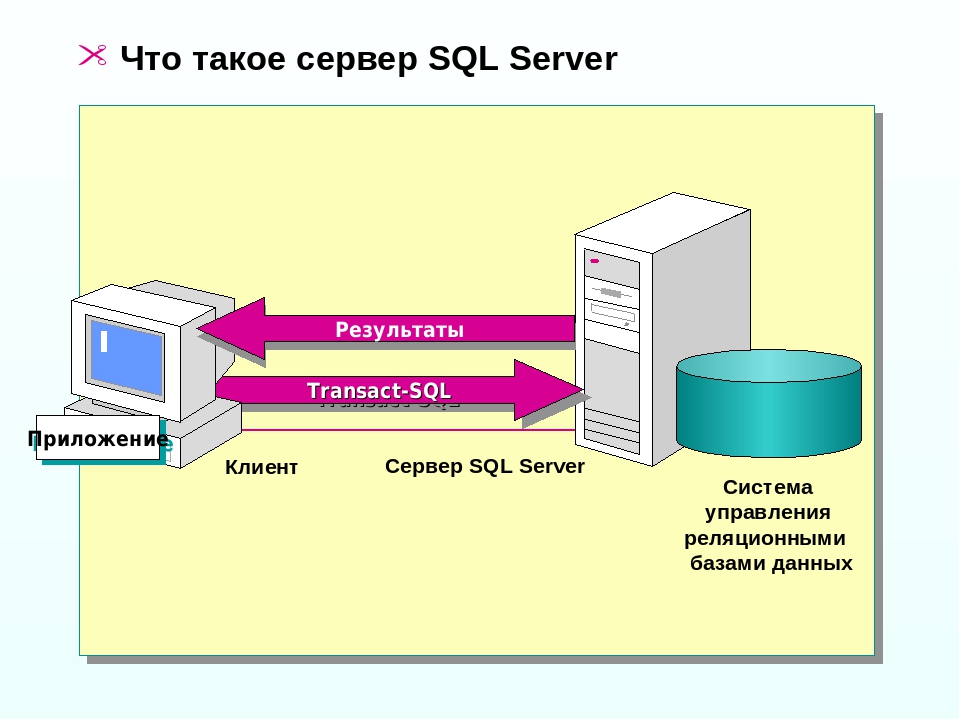
Подключение базы данных
Когда подключение удобнее и даже выгоднее резервирования? Недавно я столкнулся с такой проблемой, что настройки репликации не попадают в резервную копию. Это оказалось серьезной проблемой. У меня на работе есть два офиса, который находятся в разных концах города и не соединены через Интернет. Чтобы производить репликацию, базу данных удаленного офиса нужно перевозить в главный офис, но через резервную копию этого не получилось. База данных восстанавливается, как будто никаких настроек репликации не было.
Первое, что приходит в голову после такого разочарования – таскать жесткий диск или весь системный блок для репликации в основной офис. Это, конечно же, не очень удачный выход. И вот однажды мы попытались отключить базу данных на удаленном сервере, привести в центральный офис и подключить. Настройки репликации сохранились!
Для отключения базы данных используется системная процедура sp_detach_db. С процедурами мы пока еще не знакомы и это тема 3-й главы, поэтому пока просто выполните следующую команду для отключения:
EXEC sp_detach_db 'TestDatabase', 'true'
Про отключение баз данных мы поговорим в разделе 4.12. Там же процедура sp_detach_db будет рассмотрена более подробно.
Посмотрим, как можно подключить файл базы данных к серверу с помощью оператора CREATE DATABASE:
CREATE DATABASE DatabaseName ON PRIMARY (FILENAME = 'c:\data\filename.mdf') FOR ATTACH
В первой строке указаны ключевые слова CREATE DATABASE, после которых указывается имя подключаемой базы данных. Ключевое слово ON PRIMARY означает создание в основной файловой группе. После этого в круглых скобках указывается путь к существующему файлу данных. И в последней строке указываем FOR ATTACH, то есть для подключения.
Обратите внимание, что имя подключаемой базы отличается от имени базы, которую мы отключали. Раньше имя было TestDatabase, а после подключения оно превратилось в Archive
Таким образом, мы смогли переименовать уже существующую базу данных. С помощью оператора ALTER DATABASE, который используется для редактирования параметров (см. разд. 1.3) базы переименование невозможно.
Важность SQL
Давайте рассмотрим несколько важных моментов, которые сделали SQL таким популярным языком запросов.
1. Это повсеместно принято
Когда дело доходит до обработки и организации данных, эксперты и профессионалы обращаются к SQL, не задумываясь. Все популярные базы данных с открытым исходным кодом и бесплатные базы данных поддерживают SQL для запроса информации.
2. Легко научиться
Синтаксис SQL похож на простой естественный язык, и его довольно легко изучить по сравнению со сложным синтаксисом других языков программирования, таких как Java, C ++ и т. Д.
3. Он может обрабатывать большие наборы данных.
По сравнению с Excel и электронными таблицами, SQL может легко обрабатывать большие наборы данных с минимальными усилиями, необходимыми для управления ими.
4. Это дает лучшее представление о наборах данных.
Чтобы извлечь полезную информацию из данных, вам необходимо лучше разбираться в них. SQL позволяет использовать команды для получения взаимосвязей между наборами данных, чтобы лучше понять их.
5. Это стандарт
SQL — это язык запросов, стандартизированный как ISO, так и ANSI. Он довольно стабилен, без больших обновлений синтаксиса, и как только вы его изучите, вам не нужно особо сосредотачиваться на новых выпусках.
6. Это горячий навык
Неважно, хотите ли вы работать в области науки о данных, машинного обучения, управления базами данных, анализа данных и т. Д., SQL — это распространенный навык, который пользуется большим спросом на рынке труда
Модели восстановления
Перед тем как браться за настройку резервного копирования, следует выбрать модель восстановления. Для оптимального выбора следует оценить требования к восстановлению и критичность потери данных, сопоставив их с накладными расходами на реализацию той или иной модели.
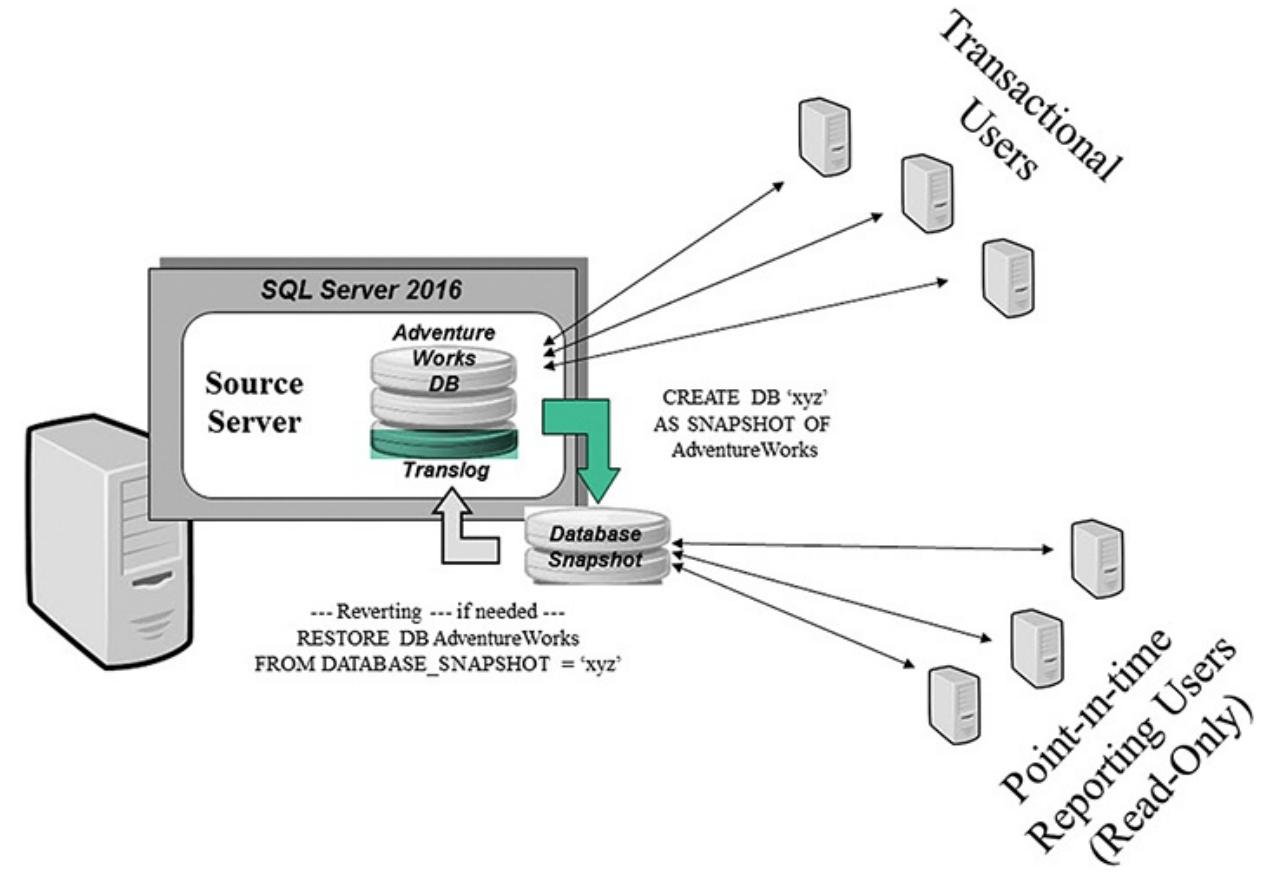
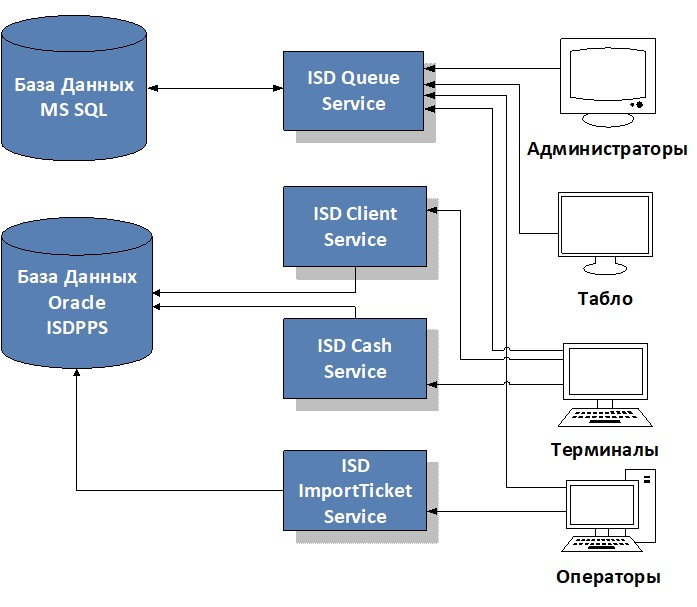
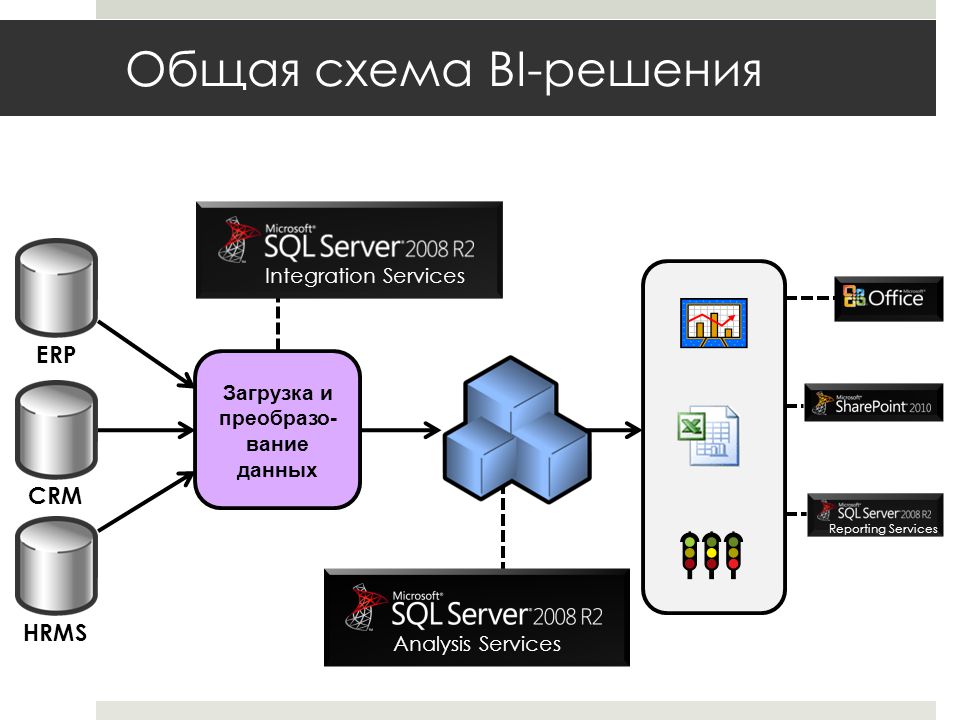
Как известно, база данных MS SQL состоит из двух частей: собственно, базы данных и лога транзакций к ней. База данных содержит пользовательские и служебные данные на текущий момент времени, лог транзакций включает в себя историю всех изменений базы данных за определенный период, располагая логом транзакций мы можем откатить состояние базы на любой произвольный момент времени.
Для использования в производственных средах предлагается две модели восстановления: простая и полная. Существует также модель с неполным протоколированием, но она рекомендуется только как дополнение к полной модели на период крупномасштабных массовых операций, когда нет необходимости восстановления базы на определенный момент времени.
Простая модель предусматривает резервное копирование только базы данных, соответственно восстановить состояние БД мы можем только на момент создания резервной копии, все изменения в промежуток времени между созданием последней резервной копии и сбоем будут потеряны. В тоже время простая схема имеет небольшие накладные расходы: вам необходимо хранить только копии базы данных, лог транзакций при этом автоматически усекается и не растет в размерах. Также процесс восстановления наиболее прост и не занимает много времени.
Полная модель позволяет восстановить базу на любой произвольный момент времени, но требует, кроме резервных копий базы, хранить копии лога транзакций за весь период, для которого может потребоваться восстановление. При активной работе с базой размер лога транзакций, а, следовательно, и размер архивов, могут достигать больших размеров. Процесс восстановления также гораздо более сложен и продолжителен по времени.
При выборе модели восстановления следует сравнить затраты на восстановление с затратами на хранение резервных копий, также следует принять во внимание наличие и квалификацию персонала, который будет выполнять восстановление. Восстановление при полной модели требует от персонала определенной квалификации и знаний, тогда как при простой схеме достаточно будет следовать инструкции
Для баз с небольшим объемом добавления информации может быть выгоднее использовать простую модель с большой частотой копий, которая позволит быстро восстановиться и продолжить работу, введя потерянные данные вручную. Полная модель в первую очередь должна использоваться там, где потеря данных недопустима, а их возможное восстановление сопряжено со значительными затратами.
Файлы моментального снимка базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. Эти команды включают DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC и DBCC CHECKFILEGROUP. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
Подготовка дисковой подсистемы под файлы БД SQL Server
Прежде чем размещать файлы баз данных SQL Server на дисковой подсистеме, нужно специальным образом подготовить соответствующие разделы NTFS, учитывая пару правил:
В случае использования ОС Windows Server 2003 желательно произвести выравнивание (смещение) начального сектора (Partition Offset / Starting Offset) на уровень 1024KB. Выравнивание может быть выполнено только на этапе создания дискового раздела NFTS и невозможно для уже существующих разделов без из пересоздания. Для ОС Windows Server 2008 и выше выравнивание проводить не требуется, так как все вновь создаваемые разделы NTFS уже смещены на число байт, кратное размеру кластера (Bytes Per Cluster / Allocation unit size). Для системного тома в ОС Windows Server 2008 и выше смещение первого раздела в конфигурации по умолчанию составляет 1024KB.
При форматировании дискового раздела NTFS желательно выбирать рекомендуемый размер кластера в 64KB (по умолчанию используется размер в 4KB).
При проверке смещения разделов, на которых планируется размещение файлов БД, можно руководствоваться правилом:
Размер смещения Partition Offset в байтах, делённый на размер кластера, которым отформатирован раздел (Allocation unit size или Bytes Per Cluster) в байтах = любое целое число.
В случае, если в результате деления получается дробное число, считается, что выравнивание диска выполнено неправильно.
Чтобы проверить смещение разделов, на которых планируется расположить файлы БД, можно воспользоваться утилитой diskpart, введя примерно следующую последовательность команд:
diskpart list disk select disk 2 list partition select partition 2 detail part
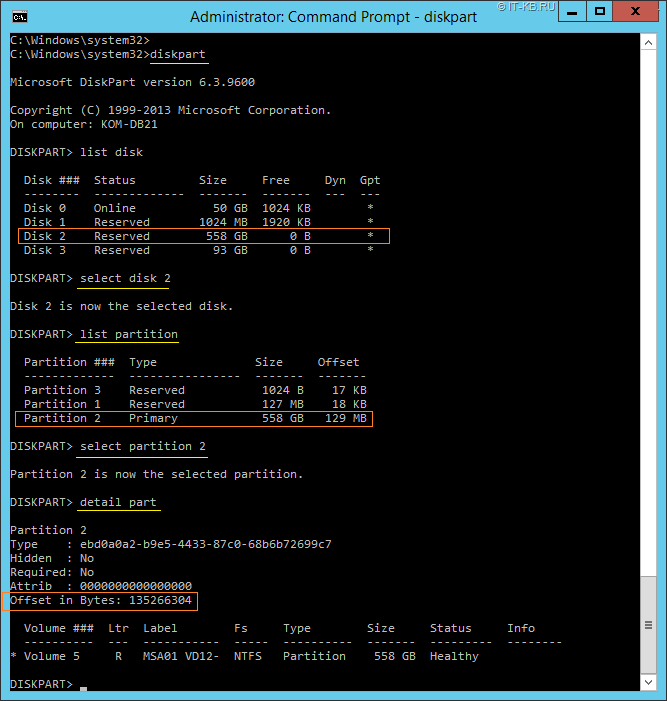
В нашем примере диск Disk 2 является кластерным GPT-диском, на котором разделы Partition 1 и Partition 3 являются скрытыми служебными разделами. Раздел Partition 2 является тем видимым в оснастке Disk Management разделом, который был нами создан под файлы БД SQL Server. Его смещение мы и будем проверять.
Смещение раздела Partition 2 имеет значение 135266304 байт (129MB), а сам раздел при этом отформатирован кластерами по 65536 байт (64KB). Проверяем: 135266304/65536 = 2064. Мы получили целое число, то есть в нашем случае смещение раздела сделано правильно и выравнивание раздела не требуется.
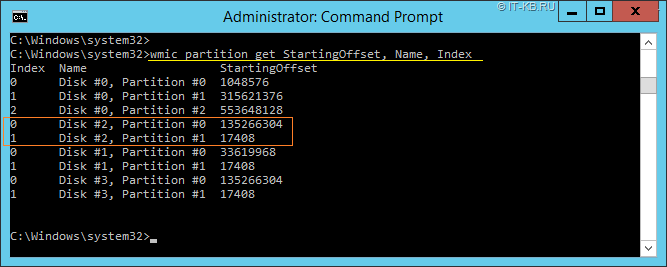
В разных источниках можно встретить рекомендацию проверять смещение разделов с помощью команды типа:
wmic partition get StartingOffset, Name, Index
Однако, исходя из практики, могу сказать, что в случае использования GPT-дисков эта команда может выдавать результаты, сбивающие с толку. Например, неверно могут быть указаны номера разделов на диске (даже по значению смещения понятно, что раздел #1 на самом деле расположен на диске раньше раздела #0). Также не виден один из скрытых разделов GPT (на самом деле на диске не два, а три раздела):
Такая информация может внести некоторую сумятицу, поэтому для более внятного определения смещения раздела лучше использовать утилиту diskpart.
Что же касается размера кластеров, которыми должен быть отформатирован NTFS раздел (Allocation unit size или Bytes Per Cluster) под файлы БД SQL Server, то его можно определить на этапе форматирования раздела.
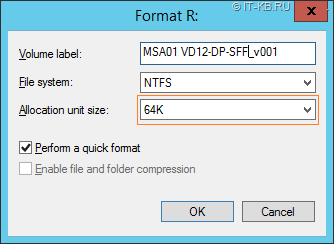
Без явного указания размера кластера, если выбрано значение Default, раздел форматируется более мелкими 4KB кластерами.
Проверить размер кластера уже отформатировано ранее раздела можно с помощью утилиты fsutil
fsutil fsinfo ntfsinfo R:
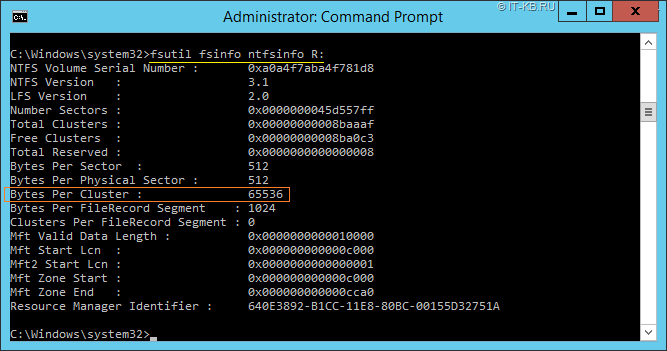
В нашем примере видно, что диск отформатирован кластерами по 64KB.
Для систем на базе Windows Server 2003 пример создания раздела со смещением в 1024KB на MBR-диске и форматирования этого раздела в NFTS с размером кластера 64KB может выглядеть следующим образом:
diskpart list disk select disk 1 create partition primary align=1024 assign letter=V format fs=ntfs unit=64K label="SQL DB Files Disk" nowait
Дополнительные источники информации:
SQLCAT Articles — Disk Partition Alignment Best Practices for SQL Server
Проверено на следующих конфигурациях:
| Версия ОС |
|---|
| Microsoft Windows Server 2012 R2 Standard EN (6.3.9600) |
Автор первичной редакции:Алексей Максимов
Время публикации: 10.02.2019 17:30
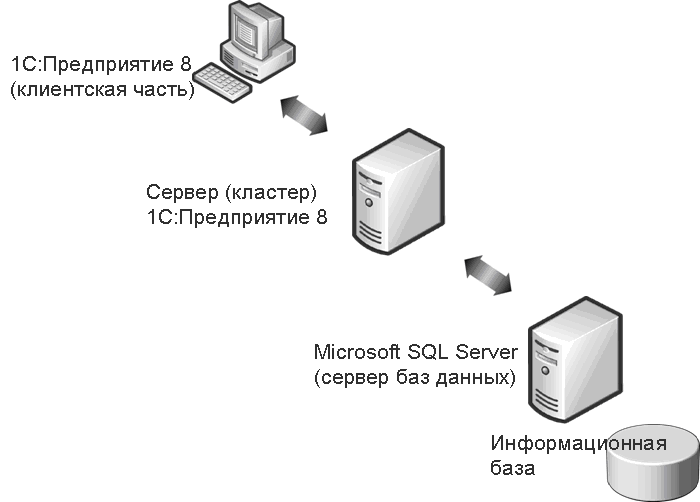
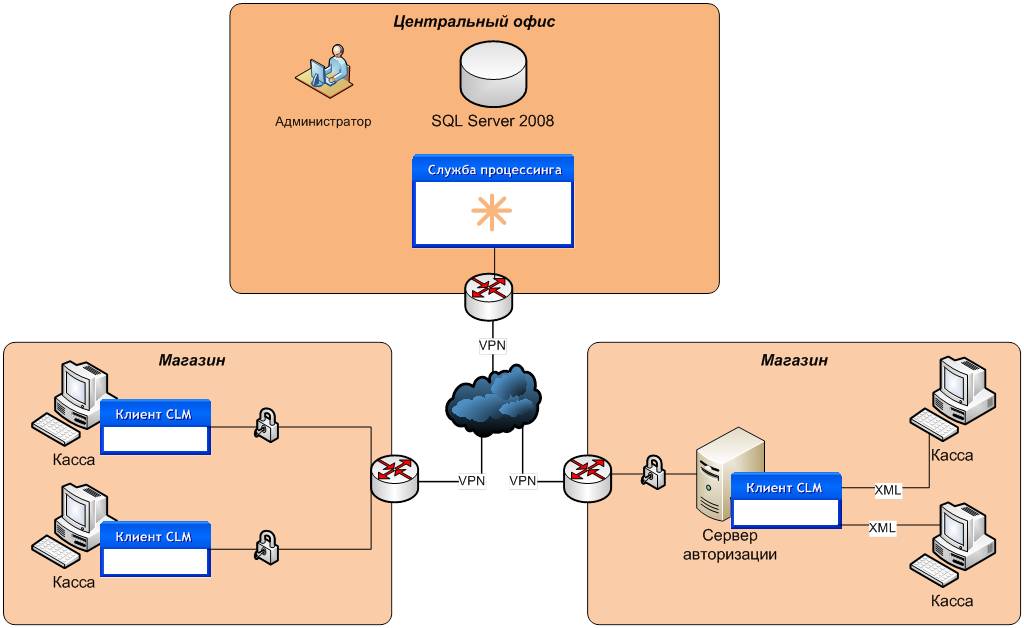
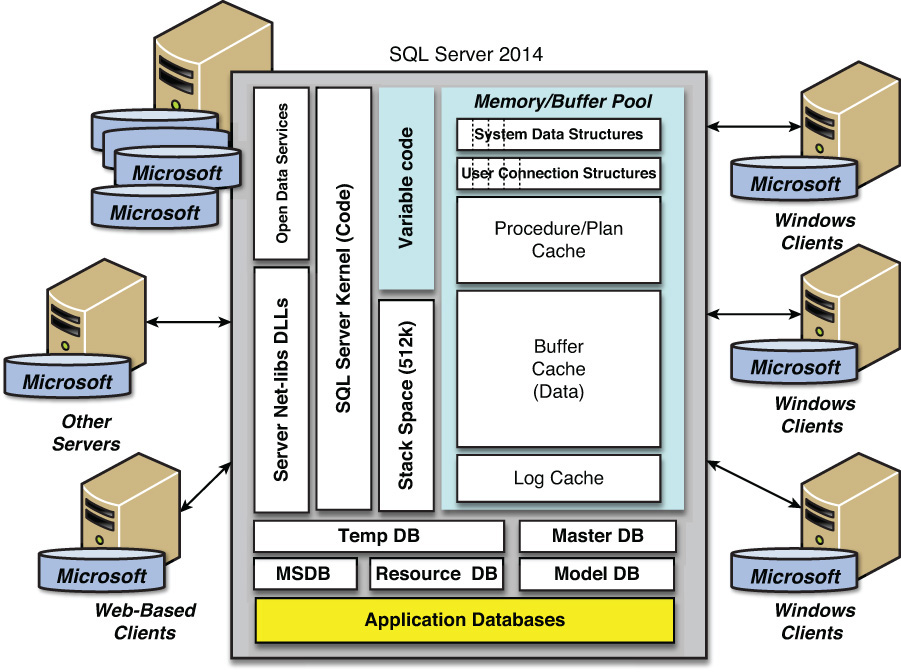

Карьера в SQL
В организациях, ориентированных на данные, существует множество профессий и профессий, требующих использования SQL как навыка. Эти организации ищут специалистов по SQL, которые могут применить свое аналитическое мышление с помощью SQL, чтобы лучше понять огромные блоки данных, которые у них есть. Если вы кандидат, который умеет работать с данными и манипулировать ими, вам определенно следует искать карьеру в программировании SQL. Рынок вакансий, связанных с SQL, можно найти как в облачных организациях, так и в тех, кто использует базы данных локально.
Требуется образование
- Квалификация, которую рекрутеры ищут у специалиста по SQL, может варьироваться от компании к компании. Это во многом зависит от рентабельности инвестиций, требований клиентов, типа работы и т. Д.
- Базовая образовательная квалификация включает степень бакалавра или магистра в области компьютерных наук, информационных технологий или даже курсы специализации в области информационных технологий.
- Дополнительные сертификаты, такие как разработчик баз данных, администратор, дизайнер, архитектор и т. Д., Добавят цвета вашему портфолио и предоставят вам преимущество над тысячами других кандидатов.
- Было бы полезно иметь опыт работы с PL / SQL, ETL и т. Д.
Должности
- SQL Server является третьим по популярности сервером баз данных, и миллионы профессионалов в настоящее время работают над различными ролями, которые прямо или косвенно требуют SQL как навыка.
- Основные направления карьеры в SQL: администратор баз данных, специалисты по бизнес-аналитике, специалисты по данным, разработчики баз данных, тестировщики баз данных, разработчики ETL, разработчики приложений бизнес-аналитики, эксперты по большим данным, инженеры облачных баз данных, инженеры по миграции баз данных и т. д.
Оплата труда
- Средняя зарплата специалиста по SQL во многом зависит от выбранной им карьеры. Обычно профессионалы с опытом работы с SQL более 5 лет имеют более высокую среднюю зарплату по сравнению с новичками.
- Согласно отчету payscale за 2018 год, средняя заработная плата разработчиков SQL в США составляет около 65 тыс. Долларов США, для старших разработчиков SQL — 85 тыс. Долларов США, для старших администраторов баз данных — около 100 тыс. Долларов, для производственных администраторов баз данных средняя зарплата может достигать 130 тысяч долларов.
IDE для SQL
IDE или интегрированная среда разработки — это графический инструмент, который позволяет вам управлять всеми файлами, связанными с вашим приложением, и работать с такими инструментами, как полезные пакеты, функции автозаполнения, подсветка синтаксиса и т. Д., Чтобы улучшить ваш опыт разработки.
Хотя это правда, что вы можете создавать базы данных и таблицы и управлять ими прямо из самой командной строки, однако использование IDE всегда будет полезно для получения обзора всех баз данных, запросов, таблиц и других компонентов с высоты птичьего полета. Фактически, есть IDE, в которых есть раздел справки, в котором объясняются основные команды и их использование. Вы можете просто заполнить текстовые поля, выбрать различные предварительно отформатированные команды, нажать кнопку «ОК», и ваша работа будет выполнена. Это так просто. Более того, существуют IDE, которые также позволяют создавать резервные копии и восстанавливать базы данных и таблицы.
Следовательно, всегда разумно выбрать среду IDE, которая удовлетворяет ваши требования, прежде чем вы запачкаете руки SQL. Вот список лучших IDE, которые вы можете использовать для составления сложных SQL-запросов.
1. DBeaver
DBeaver— это среда разработки баз данных на основе Java с открытым исходным кодом. Его можно использовать бесплатно, и в нем есть мощные функции, которые обеспечат бесперебойную разработку.
Функции —
- Он позволяет экспортировать таблицы в файлы CSV и дамп, а также восстанавливать таблицы.
- Он позволяет сохранять наиболее часто используемые команды SQL. Вы можете загрузить эти сохраненные команды позже для других проектов.
- Также есть несколько цветовых тем.
- Он имеет инструмент управления сеансом.
- Он позволяет сравнивать две таблицы БД и их структуры.
- Выполненные запросы эстетично отображаются в отдельном интерфейсе.
- Он позволяет графически редактировать ячейки таблиц базы данных и фиксировать их.
2. PHPMyAdmin
PHPMyAdmin — это многофункциональный инструмент с открытым исходным кодом на основе HTML, который вы можете использовать для управления своими базами данных.
Функции —
- Это позволяет вам управлять пользователями и разрешениями.
- Он может поддерживать множество языков.
- Это позволяет создавать и редактировать запросы и столбцы результирующих строк.
- Вы можете сохранить свои запросы на более позднее время.
- IDE обладает широкими возможностями настройки для скрытия или отображения таблиц, комментариев, кодировок, временных меток и т. Д.
- Вы можете создавать резервные копии баз данных, конвертировать их в файлы CSV, импортировать дампы SQL и т. Д.
- Это позволяет вам управлять несколькими серверами.
- Вы можете использовать QBE для создания сложных запросов.
3. Adminer
Adminer можно использовать как альтернативу PHPMyAdmin. Он основан на веб-интерфейсе, поддерживает множество плагинов, позволяет работать с несколькими базами данных, такими как Oracle, SQLite и т. Д.
Особенности —
- Подключайтесь к базам данных, создавайте новые и т. Д.
- Вы можете распечатать схемы баз данных, даже если они связаны внешними ключами.
- Вы можете устанавливать и управлять разрешениями и правами пользователей и даже изменять их как администратор.
- Раздел справки неплохой, можно отображать переменные, у которых есть реферальные ссылки на документацию.
- Вы можете легко управлять разделами таблиц и событий.
Где хранятся данные mysql?
По аналогии с остальными настройками (php, apache, nginx), предвкушал долгие поиски и не ошибся. В итоге выяснил, что хранятся они в файле /etc/mysql/conf. d/bvat.
Как просмотреть базу данных MySQL?
Чтобы получить список таблиц в базе данных MySQL, используйте клиентский инструмент mysql для подключения к серверу MySQL и выполните команду SHOW TABLES. Необязательный модификатор FULL покажет тип таблицы в качестве второго выходного столбца.
Где найти базу данных сайта?
По умолчанию сама БД сайта находится в каталоге data на веб-сервере интернет-проекта. К примеру, если БД имеет название bd, то все ее значения находятся в data/bd. Как правило, на хостинге доступ к файлам БД закрыт, их следует “вытягивать” посредством запросов SQL через консоль.
Куда сохраняется база данных SQL Server?
По умолчанию и файлы баз данных, и файлы журналов помещаются в каталог С:\Program Files\Microsoft SQL Server\MSSQL. X\MSSQL\Data (где X — номер экземпляра SQL Server 2005).
Где Битрикс хранит подключения к базе данных?
- u77777_dbuser — пользователь, от имени которого сайт подключается к базе данных;
- password — пароль, с которым сайт подключается к базе данных;
- u77777_database — база данных, которую использует сайт.
Как посмотреть список пользователей MySQL?
MySQL список пользователей
Теперь мы можем вывести список пользователей, созданных в MySQL, с помощью следующей команды: mysql> SELECT user FROM mysql. user; В результате мы сможем посмотреть всех пользователей, которые были созданы в MySQL.
Как скопировать базу данных с сайта?
Для переноса базы данных необходимо сначала создать ее дамп, то есть разместить содержимое в отдельный sql-файл. Делается это в меню phpMyAdmin на хостинге, откуда вы переносите сайт. Зайдите в phpMyAdmin, выделите слева базу данных, которую необходимо перенести, и нажмите на кнопку «Экспорт» в верхнем меню.
Что можно делать с базами данных?
База данных (БД) — это программа, которая позволяет хранить и обрабатывать информацию в структурированном виде. БД это отдельная независимая программа, которая не входит в состав языка программирования. В базе данных можно сохранять любую информацию, чтобы позже получать к ней доступ.
Как узнать имя сервера базы данных MySQL?
Запустите классическое приложение Windows “Службы” на вашем компьютере и найдите в списке служб объект SQL Server. В скобках будет указано имя экземпляра. В этом же меню можно остановить, запустить и перезапустить экземпляр установленного Microsoft SQL Server.
Где находится SQL Server Management Studio?
На панели задач нажмите кнопку Пуск, выберите Все программы, Microsoft SQL Server SQL Server 2008, а затем щелкните SQL Server Management Studio.
Будьте внимательны с выбором фрагмента секционирования
- Большинство клиентов используют для секционирования месяц, квартал или год.
- Для эффективного удаления необходимо удалять по одной полной секции за один раз.
- Загрузка происходит быстрее, если за один раз загружается полная секция.
- Привлекательным вариантом может оказаться создание ежедневных секций для ежедневной нагрузки.
- Однако следует помнить, что таблица может содержать не более 1000 секций.
- Выбор степени секционирования влияет на параллелизм запросов.
- Для SQL Server 2005:
- Для запросов, затрагивающих одну секцию, параллелизм может достигать значения MAXDOP (максимальной степени параллелизма).
- В запросах, затрагивающих несколько секций, используется один поток на секцию, вплоть до значения MAXDOP.
- Для SQL Server 2008:
- Для SQL Server 2005:
- Если необходимо добиться степени параллелизма, соответствующей MAXDOP, рекомендуется избегать таких схем секционирования, при которых запросы часто затрагивают лишь 2 или 3 секции (предполагается, что MAXDOP равно или больше 4).
Загружайте исходные данные эффективным образом
- Во время начальной загрузки данных используйте модели восстановления SIMPLE или BULK LOGGED.
- Создайте секционированную таблицу фактов с кластеризованным индексом.
- Создайте неиндексированные промежуточные таблицы для каждой из секций и разделите файлы исходных данных, предназначенные для заполнения каждой из секций.
- Заполняйте промежуточные таблицы параллельно.
- Используйте несколько инструкций BULK INSERT, программу BCP или задачи служб SSIS.
- Если подсистема ввода-вывода не является «узким местом», создайте столько параллельно выполняющихся сценариев загрузки, сколько в системе установлено процессоров. Если пропускная способность ввода-вывода ограничена, используйте одновременно меньшее число скриптов.
- Установите нулевой размер пакета для загрузки.
- Установите нулевой размер фиксации для загрузки.
- Используйте TABLOCK.
- Если источником данных служат расположенные на одном сервере «плоские» файлы, используйте инструкцию BULK INSERT. Если данные принудительно отправляются с удаленных компьютеров, используйте программу BCP или службы SSIS.
- Используйте несколько инструкций BULK INSERT, программу BCP или задачи служб SSIS.
- Постройте кластеризованный индекс для каждой промежуточной таблицы, а затем создайте соответствующие ограничения CHECK.
- Переключите все секции в секционированную таблицу с помощью инструкции SWITCH.
- Постройте для секционированной таблицы некластеризованные индексы.
- На 64-процессорном сервере 1 ТБ данных можно загрузить менее чем за с хранилищем SAN с пропускной способностью 14 ГБ/с (для неиндексированной таблицы). Дополнительные сведения см. в записи блога SQLCAT http://blogs.msdn.com/sqlcat/archive/2006/05/19/602142.aspx.
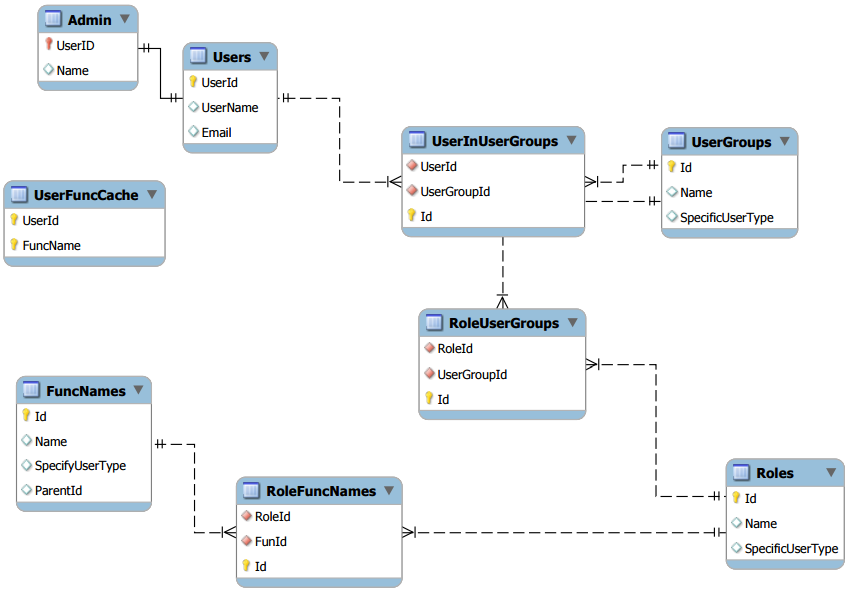
Приложение. Структура данных
Таблица Speciality (специальность)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| Name | Название | varchar(60) | Нет |
Таблица Course (курс)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | нет |
| Name | Название специальности | varchar(60) | нет |
| YearEntry | Год поступления | int | нет |
| YearFinal | Год выпуска | int | да |
| Speciality | Специальность (внешний ключ ссылается на первичный ключ таблицы Speciality) | int | нет |
Таблица Group (группа)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | нет |
| Name | Название специальности | varchar(60) | нет |
| Course | Курс (внешний ключ ссылается на первичный ключ таблицы Course ) | int | нет |
Таблица Discipline (дисциплина)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| Name | Название (возможные значения: программирование, алгебра…) | varchar(60) | Нет |
Таблица Account (тип отчетности)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| Name | Название (возможные значения: экзамен, зачет, дифференцированный зачет…) | varchar(30) | Нет |
Таблица Mark (отметка)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| Name | Название (возможные значения: зачтено, не зачтено, отлично, хорошо…) | varchar(30) | Нет |
| Value | Значение (возможные значения: 0, 1, …, 5) | int | Нет |
Таблица Status (академический статус студента)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| Name | Название (возможные значения: обучается, отчислен, в академическом отпуске, в отпуске по уходу за ребенком) | varchar(60) | Нет |
Таблица Position (должность)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| Name | Название (возможные значения: ассистент, старший преподаватель, доцент…) | varchar(60) | Нет |
Таблица People (люди)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| LastName | Фамилия | varchar(30) | Нет |
| FirstName | Имя | varchar(30) | Нет |
| MiddleName | Отчество | varchar(30) | Да |
| Male | Пол | char(1) | Нет |
| BrthDate | День рождения | datetime | Да |
| Addr | Адрес | varchar(100) | Да |
Таблица Student (студент)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| People | Человек (внешний ключ ссылается на первичный ключ таблицы People) | int | Нет |
| Group | Группа (внешний ключ ссылается на первичный ключ таблицы Group) | int | Нет |
| StudNum | Номер студенческого билета | varchar(30) | Нет |
| Status | Академический статус студента (внешний ключ ссылается на первичный ключ таблицы Status) | int | Нет |
Таблица Teacher (преподаватель)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ (табельный номер сотрудника) | int | Нет |
| People | Человек (внешний ключ ссылается на первичный ключ таблицы People) | int | Нет |
| Position | Должность (внешний ключ ссылается на первичный ключ таблицы Position) | int | Нет |
Таблица SemesterResults (результаты сессии)
| Имя поля (столбца) | Тип данных | Возможность содержать NULL | |
|---|---|---|---|
| Num | Первичный ключ | int | Нет |
| Student | Студент (внешний ключ ссылается на первичный ключ таблицы Student) | int | Нет |
| Semester | Порядковый номер семестра | int | Нет |
| Account | Тип отчетности (внешний ключ ссылается на первичный ключ таблицы Account) | int | Нет |
| Discipline | Дисциплина (внешний ключ ссылается на первичный ключ таблицы Discipline) | int | Нет |
| Teacher | Преподаватель (внешний ключ ссылается на первичный ключ таблицы Teacher) | int | Нет |
| Mark | Отметка (внешний ключ ссылается на первичный ключ таблицы Mark) | int | Нет |
| Date | Дата сдачи отчетности | DateTime | Нет |
![Подготовка дисковой подсистемы под файлы бд sql server [вики it-kb]](https://wudgleyd.ru/wp-content/uploads/7/3/1/731fda6bf76efd74bcf62ffaf47cd849.jpeg)