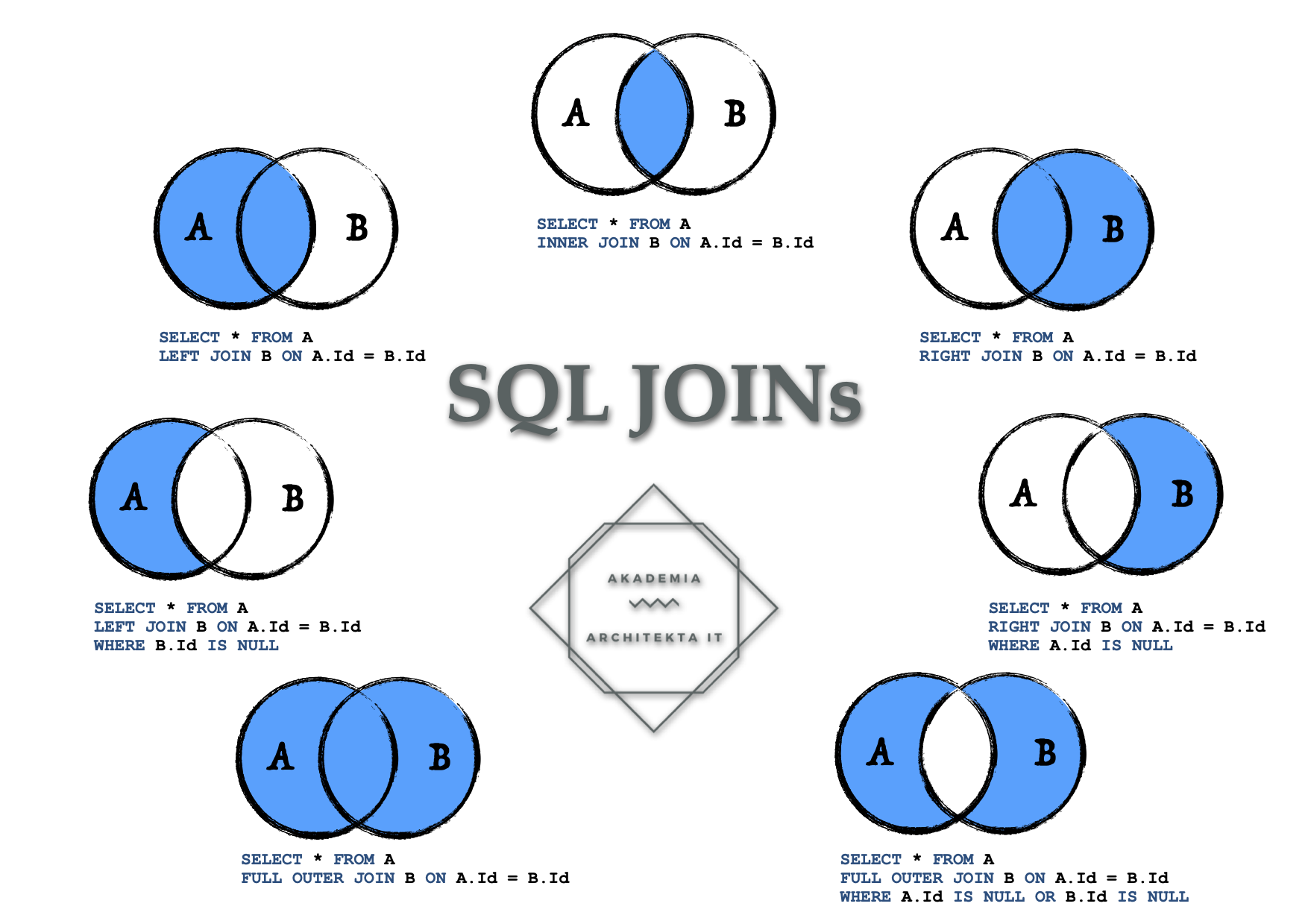
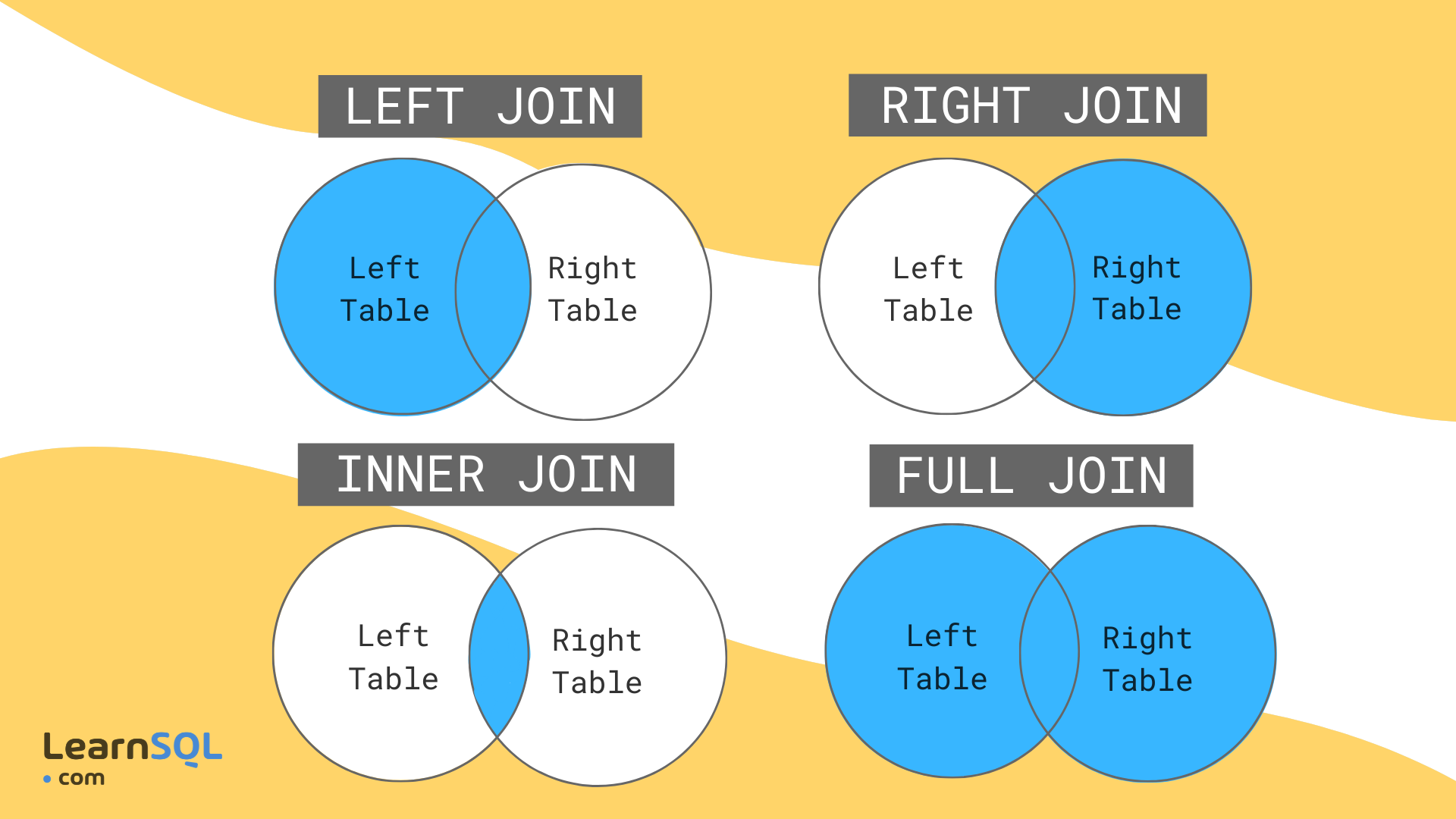
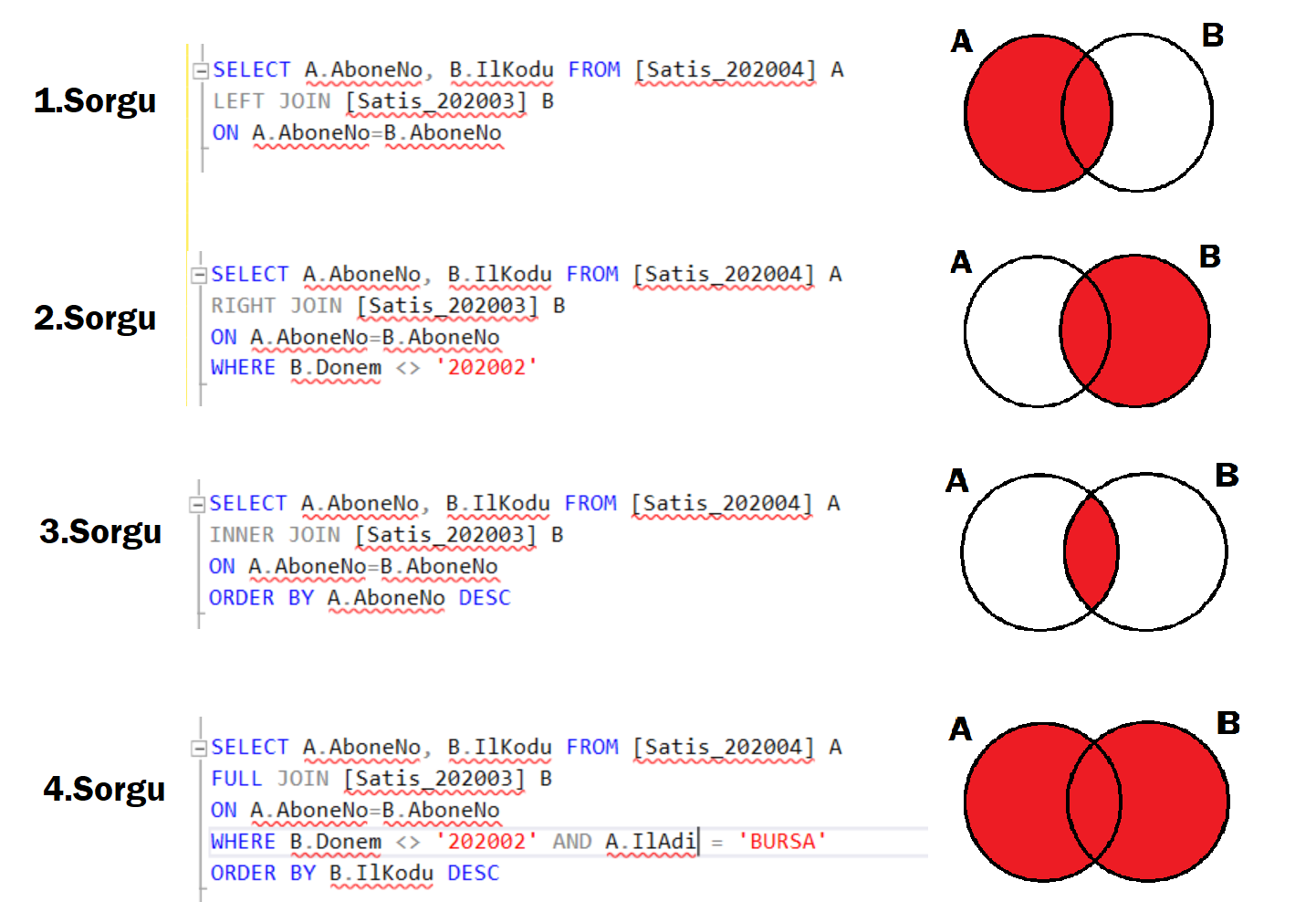
Чем полезен план выполнения запроса разработчику T-SQL
Что такое план выполнения запроса в Microsoft SQL Server и как он формируется, мы рассмотрели, но кто-то может спросить – «это все хорошо, но зачем нам, как разработчикам (или администраторам), это нужно знать?».
Все дело в том, что, посмотрев на план запроса и проанализировав его, мы можем предпринять те или иные действия для увеличения быстродействия запроса.
Иными словами, план выполнения запроса в основном нам требуется для решения проблем с производительностью наших SQL инструкций.
Например, SQL запрос выполняется долго, и чтобы определить, в чем конкретная причина его долгой работы, мы можем посмотреть на план запроса, где мы можем увидеть, что у нас не используется тот или иной индекс, или подходящего индекса просто не существует, или индекс используется, но мы все равно дополнительно обращаемся в кластеризованный индекс, т.е. у нас не покрывающий индекс.
Также в плане запроса мы можем увидеть, что у нас от оператора к оператору идет достаточно большой поток данных, хотя, допустим, в результирующем наборе у нас данных не так много, поэтому мы можем сделать рефакторинг SQL кода, чтобы выполнить необходимую фильтрацию данных как можно раньше, например, предварительно сохранив их во временную таблицу.
В плане выполнения запроса дополнительно отображается информация о так называемой стоимости того или иного оператора, т.е. для каждой операции в плане запроса есть оценка ее нагрузки относительно всего запроса. Иными словами, с помощью плана запроса мы можем сразу увидеть, какие из операторов и, соответственно, операций, самые высоконагруженные в данном запросе. Хотя стоит учитывать то, что это всего лишь предварительная оценка стоимости, и иногда она не соответствует действительности (за счет действий, которые в плане запроса могут не отображаться)
Но в любом случае, если какой-нибудь оператор в плане запроса занимает 99% нагрузки, то на него определенно стоит обратить внимание
Кроме этого, в плане выполнения запроса мы можем найти и много других причин, по которым может тормозить SQL запрос и, как следствие, мы можем предпринять определенные действия, чтобы каким-то образом повлиять на выполнение запроса и, тем самым, увеличить его быстродействие.
Таким образом, с помощью плана выполнения запроса мы можем узнать, как именно выполняется наш SQL запрос, т.е. какие именно операции совершаются, и вся эта информация нужна нам для того, чтобы в случае необходимости мы могли тем или иным образом повлиять на выполнение этого запроса.
На сегодня это все, в следующем материале мы поговорим о том, как посмотреть тот или иной план выполнения запроса в среде SQL Server Management Studio.
Источник
Stream Aggregate
Статистическое выражение потока. Группирует строки в один или несколько столбцов и вычисляет одно или несколько агрегатных выражений (пример: COUNT, MIN, MAX, SUM и AVG), возвращенных запросом. Выход этого оператора может быть использован последующими операторами запроса, возвращен клиенту или то и другое. Оператору Stream Aggregate необходимы входные данные, упорядоченные по группируемым столбцам. Оптимизатор использует перед этим оператором оператор Sort, если данные не были ранее отсортированы оператором Sort или используется упорядоченный поиск или просмотр в индексе.
Hash Match Join
Операция используется всегда, когда невозможно применить другие виды соединения. Она выбираются оптимизатором запросов по одной из двух причин:
- Соединяемые наборы данных настолько велики, что они могут быть обработаны только с помощью Hash Match Join.
- Наборы данных не упорядочены по столбцам соединения, и SQL Server думает, что вычисление хэшей и цикл по ним будет быстрей, чем сортировка данных.
При первом сценарии трудно оптимизировать выполнение запроса, если только не найти способа соединять меньшие объемы данных.
При втором же сценарии, если есть некоторый способ получить данные в упорядоченном виде до соединения, типа предопределенного порядка сортировки в индексе, то возможно, что SQL Server выберет вместо этой операции более быстрый алгоритм соединения.
Операторы Hash Match Join достаточно эффективны тогда, когда не сбрасывают данные в tempdb.
Предоставлять, отзывать и запрещать разрешения для базы данных
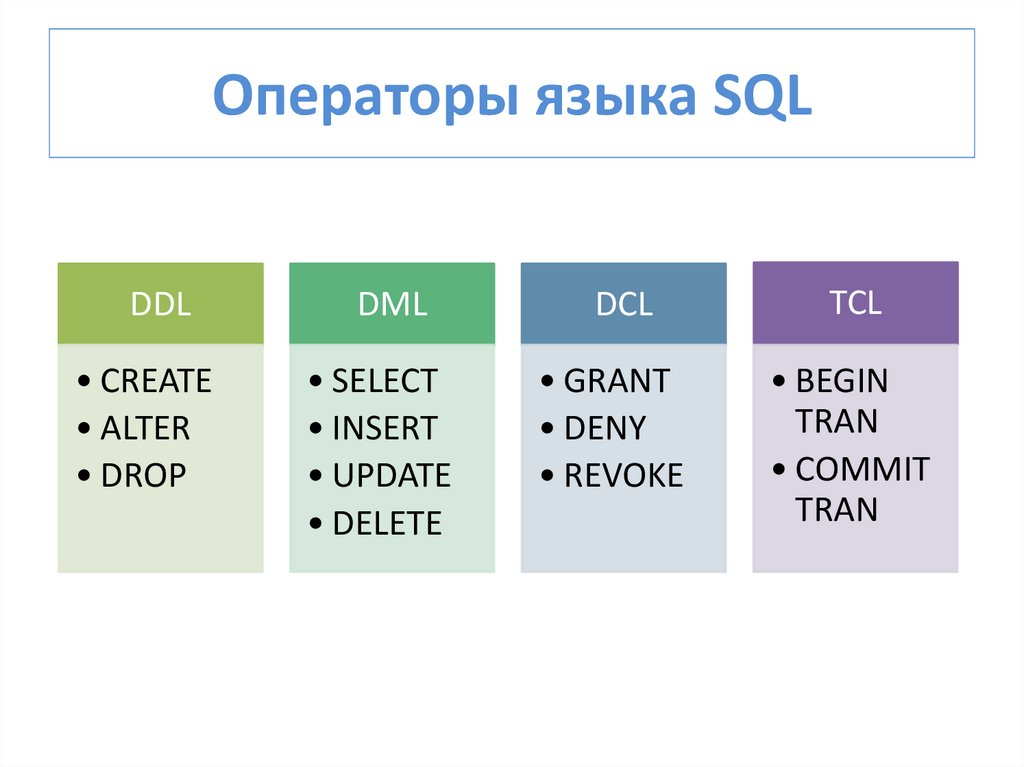
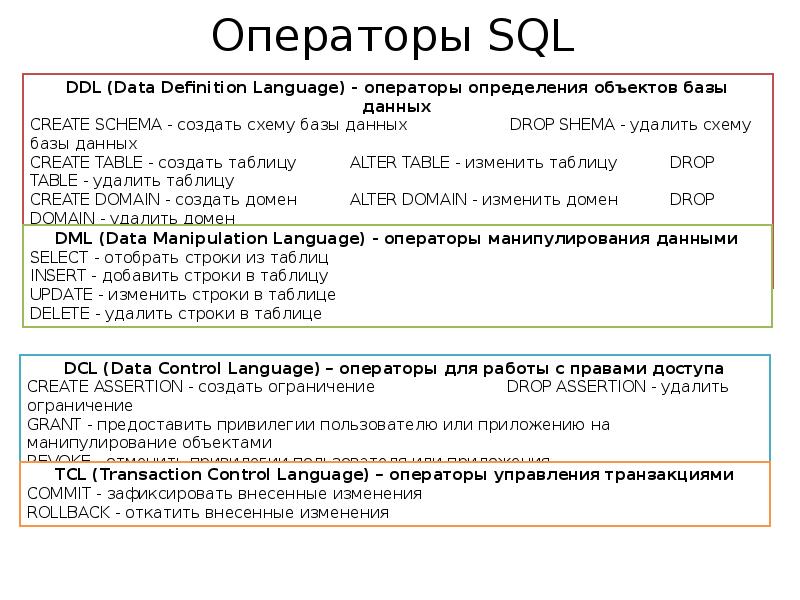
Язык управления данными (DCL) является подмножеством языка структурированных запросов (SQL) и позволяет администраторам баз данных настраивать безопасный доступ к реляционным базам данных. Он дополняет язык определения данных (DDL), который используется для добавления и удаления объектов базы данных, и язык манипулирования данными (DML), используемый для извлечения, вставки и изменения содержимого базы данных.
DCL является самым простым из подмножеств SQL, поскольку он состоит только из трех команд: GRANT, REVOKE и DENY. В совокупности эти три команды предоставляют администраторам возможность гибко устанавливать и удалять разрешения для базы данных.
Добавление разрешений с помощью команды GRANT
Команда GRANT используется администраторами для добавления новых разрешений пользователю базы данных. У него очень простой синтаксис, определенный следующим образом:
GRANT ON TO
Вот краткое описание каждого из параметров, которые вы можете указать с помощью этой команды:
Привилегия – может быть ключевым словом ALL (для предоставления широкого спектра разрешений) или определенным разрешением базы данных или набором разрешений. Примеры включают CREATE DATABASE, SELECT, INSERT, UPDATE, DELETE, EXECUTE и CREATE VIEW.
Объект – может быть любым объектом базы данных. Допустимые параметры привилегий зависят от типа объекта базы данных, который вы включаете в это предложение. Как правило, объект будет либо базой данных, функцией, хранимой процедурой, таблицей или представлением.
Пользователь – может быть любым пользователем базы данных. Вы также можете заменить роль для пользователя в этом пункте, если хотите использовать безопасность баз данных на основе ролей.
Если вы добавите необязательное условие WITH GRANT OPTION в конце команды GRANT, вы не только предоставите указанному пользователю разрешения, определенные в операторе SQL, но и дадите пользователю возможность предоставить те же разрешения. другим пользователям базы данных
По этой причине используйте этот пункт с осторожностью.
Например, предположим, что вы хотите предоставить пользователю Джо возможность извлекать информацию из таблицы сотрудников в базе данных под названием HR. Вы можете использовать следующую команду SQL:
ВЫБРАТЬ ГРАНТ НА HR.employees TO Джо
Теперь у Джо будет возможность извлекать информацию из таблицы сотрудников. Однако он не сможет предоставить другим пользователям разрешение на извлечение информации из этой таблицы, поскольку вы не включили условие WITH GRANT OPTION в оператор GRANT.
Отмена доступа к базе данных
Команда REVOKE используется для удаления доступа к базе данных у пользователя, ранее предоставившего такой доступ. Синтаксис этой команды определяется следующим образом:
REVOKE ON FROM
Вот краткое описание параметров команды REVOKE:
- Разрешение – указывает разрешения для базы данных, которые необходимо удалить для указанного пользователя. Команда отменяет оба утверждения GRANT и DENY, ранее сделанные для указанного разрешения.
- Объект – может быть любым объектом базы данных. Допустимые параметры привилегий зависят от типа объекта базы данных, который вы включаете в это предложение. Как правило, объект будет либо базой данных, функцией, хранимой процедурой, таблицей или представлением.
- Пользователь – может быть любым пользователем базы данных. Вы также можете заменить роль для пользователя в этом пункте, если хотите использовать безопасность баз данных на основе ролей.
- Предложение GRANT OPTION FOR устраняет возможность указанного пользователя предоставлять указанное разрешение другим пользователям. Примечание . Если вы включите условие GRANT OPTION FOR в оператор REVOKE, основное разрешение будет не отменено. Этот пункт отменяет только возможность предоставления.
- Параметр CASCADE также отменяет указанное разрешение у всех пользователей, которым указанный пользователь предоставил разрешение.
Например, следующая команда отзывает разрешение, предоставленное Джо в предыдущем примере:
ОТМЕНИТЬ ВЫБРАТЬ НА HR.employees ОТ Джо
Явный отказ в доступе к базе данных
Команда DENY используется для явного запрета пользователю получать определенное разрешение. Это полезно, когда пользователь является участником роли или группы, которой предоставлено разрешение, и вы хотите запретить этому отдельному пользователю наследовать разрешение путем создания исключения. Синтаксис этой команды следующий:
DENY ON TO
Параметры для команды DENY идентичны параметрам, используемым для команды GRANT.Например, если вы хотите, чтобы Мэтью никогда не получал возможность удалять информацию из таблицы сотрудников, введите следующую команду:
УДАЛЕНИЕ ДЕНИ НА HR.employees TO Matthew
Подсистема «Показатели объектов»
Если вашим пользователям нужно вывести в динамический список разные показатели, которые нельзя напрямую получить из таблиц ссылочных объектов, и вы не хотите изменять структуру справочников или документов — тогда эта подсистема для вас. С помощью нее вы сможете в пользовательском режиме создать свой показатель, который будет рассчитываться по формуле или с помощью запроса. Этот показатель вы сможете вывести в динамический список, как любую другую характеристику объекта. Также можно будет настроить отбор или условное оформление с использованием созданного показателя.
2 стартмани
06.03.2021
12843
7
pila86
16
29
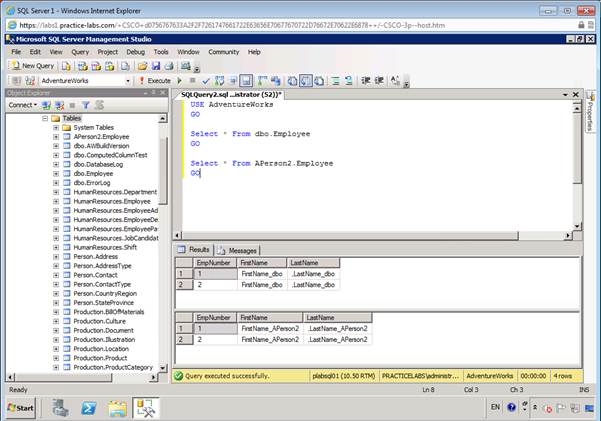
Создание таблицы с таким же именем в другой схеме
Шаг 1
Выполните
следующий
код с окне
запросов:
USE
AdventureWorks
GO
CREATE
TABLE dbo.Employee
(EmpNumber
INT,
FirstName
NVARCHAR (40),
LastName
NVARCHAR (40))
GO

Шаг 2
Вставьте
новые записи
в таблицу
Employee
, что
находится в
схемах
dboиAPerson2
USE
AdventureWorks
GO
INSERT
INTO dbo.Employee (EmpNumber, FirstName,LastName )
VALUES
(1,
‘FirstName_dbo’,’,LastName_dbo’),
(2,
‘FirstName_dbo’,’,LastName_dbo’)
GO
INSERT
INTO APerson2.Employee (EmpNumber, FirstName,LastName )
VALUES
(1,
‘FirstName_APerson2′,’,LastName_APerson2′),
(2,
‘FirstName_APerson2′,’,LastName_APerson2′)
GO

Step 3
Напишите
запрос к
таблице, что
расположены
в двух разных
схемах
USE
AdventureWorks
GO
Select
* From dbo.Employee
GO
Select
* From APerson2.Employee
GO
Общие сведения
Одной из часто встречающихся причин неоптимальной работы системы является неправильное или несвоевременное выполнение регламентных операций на уровне СУБД
Особенно важно выполнять эти регламентные процедуры в крупных информационных системах, которые работают под значительной нагрузкой и обслуживают одновременно большое количество пользователей. Специфика таких систем в том, что обычных действий, выполняемых СУБД автоматически (на основании настроек) оказывает недостаточно для эффективной работы
Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Выполнение регламентных процедур должно быть автоматизировано. Для автоматизации этих операций рекомендуется использовать встроенное средства MS SQL Server: Maintenance Plan. Существуют так же другие способы автоматизации выполнения этих процедур. В настоящей статье для каждой регламентной процедуры дан пример ее настройки при помощи Maintenance Plan для MS SQL Server 2005.



Для MS SQL Server рекомендуется выполнять следующие регламентные операции:
Рекомендуется своевременность и правильность выполнения данных регламентных процедур.
метод 4-Проверка кэша запросов
если вы не можете запустить запрос напрямую, а также не можете захватить трассировку профилировщика, вы все равно можете получить оценочный план, проверив кэш плана запроса SQL.
мы осматриваем планирование кэша путем запроса SQL Server DMVs. Ниже приведен базовый запрос, в котором будут перечислены все кэшированные планы запросов (как xml) вместе с их текстом SQL. В большинстве баз данных вам также нужно будет добавить дополнительные предложения фильтрации, чтобы отфильтровать результаты только до планов, которые вас интересуют.
выполнить этот запрос и нажмите на план XML, чтобы открыть план в новом окне-щелкните правой кнопкой мыши и выберите » Сохранить план выполнения как…»чтобы сохранить план в файл формат XML.
Примечания:
потому что есть так много факторов, участвующих (начиная от таблицы и схемы индекса до сохраненных данных и статистики таблицы), вы должны всегда попробуйте получить план выполнения из интересующей вас базы данных (обычно это та, которая испытывает проблемы с производительностью).
вы не можете создать план выполнения для зашифрованных хранимых процедур.
Фактический план выполнения SQL
Фактический план выполнения SQL генерируется оптимизатором при выполнении SQL-запроса. Если статистика таблицы базы данных точна, фактический план не должен существенно отличаться от расчетного.
УСТАНОВИТЕ СТАТИСТИКУ ВВОДА-ВЫВОДА, ВРЕМЯ, ПРОФИЛЬ НА
Чтобы получить фактический план выполнения на SQL Server, вам необходимо включить параметры, как показано в следующей команде SQL:
SET STATISTICS IO, TIME, PROFILE ON
Теперь при выполнении предыдущего запроса SQL Server создаст следующий план выполнения:
| Rows | Executes | NodeId | Parent | LogicalOp | EstimateRows | EstimateIO | EstimateCPU | AvgRowSize | TotalSubtreeCost | |------|----------|--------|--------|----------------------|--------------|-------------|-------------|------------|------------------| | 10 | 1 | 1 | 0 | NULL | 10 | NULL | NULL | NULL | 0.03338978 | | 10 | 1 | 2 | 1 | Top | 1.00E+01 | 0 | 3.00E-06 | 15 | 0.03338978 | | 30 | 1 | 4 | 2 | Distinct Sort | 30 | 0.01126126 | 0.000478783 | 146 | 0.03338679 | | 41 | 1 | 5 | 4 | Inner Join | 44.362 | 0 | 0.00017138 | 146 | 0.02164674 | | 41 | 1 | 6 | 5 | Clustered Index Scan | 41 | 0.004606482 | 0.0007521 | 31 | 0.005358581 | | 41 | 41 | 7 | 5 | Clustered Index Seek | 1 | 0.003125 | 0.0001581 | 146 | 0.0158571 | SQL Server parse and compile time: CPU time = 8 ms, elapsed time = 8 ms. (10 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'post'. Scan count 0, logical reads 116, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'post_comment'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (6 row(s) affected) SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms.
После выполнения запроса, который нас интересует, чтобы получить фактический план выполнения, вам необходимо отключить настройках, подобных этому:
SET STATISTICS IO, TIME, PROFILE OFF
Фактический план среды SQL Server Management Studio
В приложении SQL Server Management Studio вы можете легко получить расчетный план выполнения для любого SQL-запроса, нажав сочетание клавиш .
Spool
Спулы бывают разных типов, но большинство из них можно сформулировать как операторы, которые сохраняют промежуточную таблицу результатов в tempdb.
SQL Server часто использует спул для обработки сложных запросов, преобразуя данные во временную таблицу в базе tempdb для использования её данных в последующих операциях. Побочным эффектом здесь является необходимость записи данных на диск.
Для ускорения выполнения запроса можно попытаться найти способ его перезаписи таким образом, чтобы избежать спула. Если это не получается, использую метод «разделяй и властвуй» для временных таблиц, который может также заменить спул, обеспечивая больший контроль по сравнению с тем, как SQL Server записывает и индексирует данные в tempdb.
Тонкая настройка SQL
С учетом плана и временной сложности выполнения запроса, вы можете выполнить более тонкую настройку своего SQL-запроса
Вы можете начать с того, что уделите особе внимание следующим моментам:
- Заменить ненужное полное сканирование больших таблиц на сканирование индексовэ
- Убедиться, что применяется оптимальный порядок соединения таблиц.
- Убедиться, что индексы используются оптимально, а также в том, что
- Небольшие таблицы кэшированы и используются полностью индексированные таблицы.
Поздравляем! Вы дошли до конца этого сообщения в нашем блоге, получив небольшой обзор по теме производительности SQL-запросов. Надеюсь, вы получили больше информации о об анти-шаблонах, оптимизаторе запросов и инструментах, которые можно использовать для просмотра, оценки и интерпретации сложности плана ваших запросов. Однако это только малая часть знаний! Если вы хотите узнать больше, рекомендуем вам прочитать книгу «Системы управления базами данных», написанную Р. Рамакришнаном и Дж. Герке.
Наконец, приведу цитату от пользователя StackOver-flow
Начать работу с SQL вам может помочь вводный курс Data-Camp по SQL для науки о данных!
Перевод статьи Karlijn WillemsSQL Tutorial: How To Write Better Queries
Важность SQL
Давайте рассмотрим несколько важных моментов, которые сделали SQL таким популярным языком запросов.
1. Это повсеместно принято
Когда дело доходит до обработки и организации данных, эксперты и профессионалы обращаются к SQL, не задумываясь. Все популярные базы данных с открытым исходным кодом и бесплатные базы данных поддерживают SQL для запроса информации.
2. Легко научиться
Синтаксис SQL похож на простой естественный язык, и его довольно легко изучить по сравнению со сложным синтаксисом других языков программирования, таких как Java, C ++ и т. Д.
3. Он может обрабатывать большие наборы данных.
По сравнению с Excel и электронными таблицами, SQL может легко обрабатывать большие наборы данных с минимальными усилиями, необходимыми для управления ими.
4. Это дает лучшее представление о наборах данных.
Чтобы извлечь полезную информацию из данных, вам необходимо лучше разбираться в них. SQL позволяет использовать команды для получения взаимосвязей между наборами данных, чтобы лучше понять их.
5. Это стандарт
SQL — это язык запросов, стандартизированный как ISO, так и ANSI. Он довольно стабилен, без больших обновлений синтаксиса, и как только вы его изучите, вам не нужно особо сосредотачиваться на новых выпусках.
6. Это горячий навык
Неважно, хотите ли вы работать в области науки о данных, машинного обучения, управления базами данных, анализа данных и т. Д., SQL — это распространенный навык, который пользуется большим спросом на рынке труда
Создайте такое же вычисляемое поле используя SSMS
Шаг 1
В
SQL Server Management Studio
откройте
Object explorer
слева (можетбытьужеоткрыт).
Раскройте
Databases
и
AdventureWorks, прав
ый клик
на объекте
Tables
в
базе данных
AdventureWorks
, и
затем
выберите
New
Table
что бы
создать
новую
таблицу.
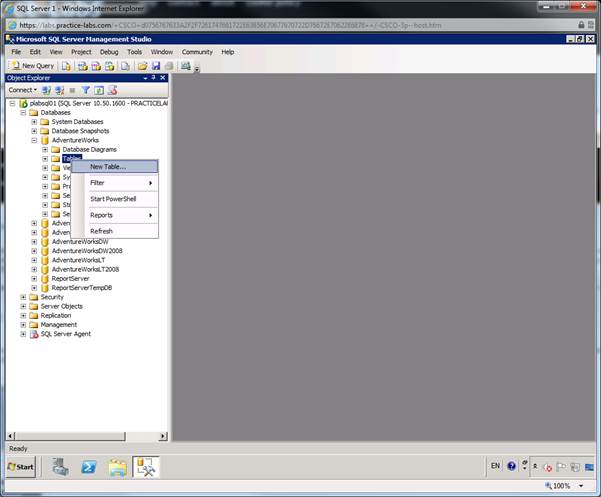
Шаг 2
Создайте
такую
структуру
базы данных:
Название
поля —
EmpNumber
Тип
данных-
Int
Название
поля —
DOBirth
Тип
данных —
Datetime
Поле
DORetirement
будет нашим
вычисляемым
полем,
раскройте
Column
Properties
внизу
страницы, и откройте
Computed
Column
Specification
под
секцией
Table
Designer
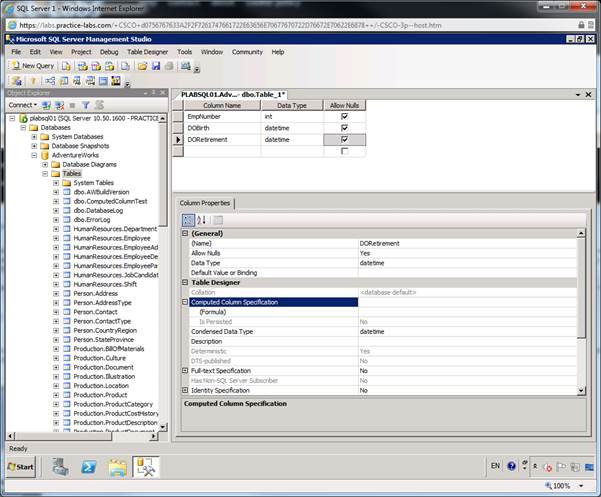
В
спецификации
напишите:
(
dateadd
(
year
,(60),[
DOBirth
])-(1))
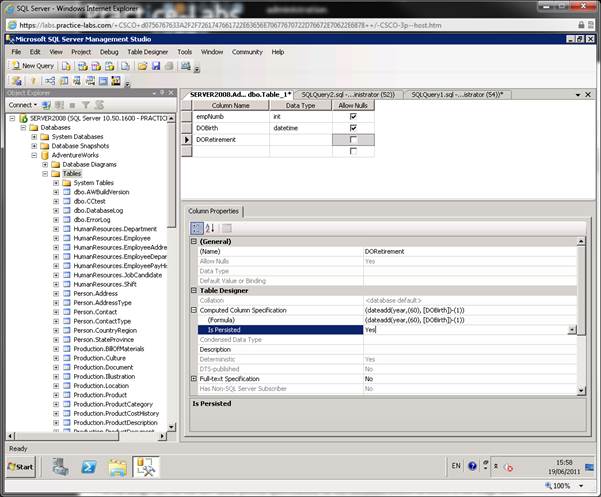
Так же
как и ранее,
вы можете
создать постоянное
поле выбрав
Persisted
Yes
в постоянном
поле:
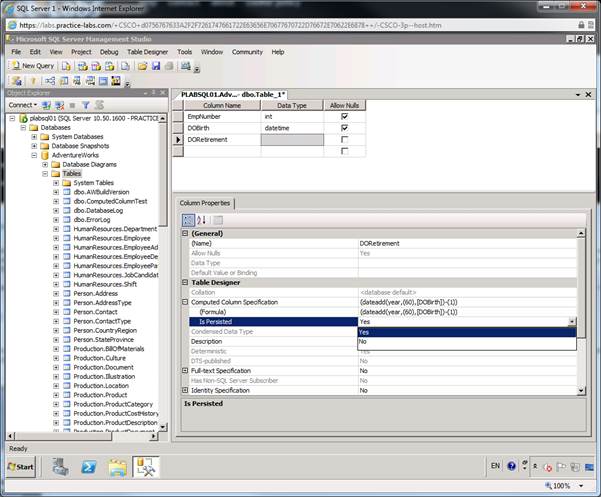
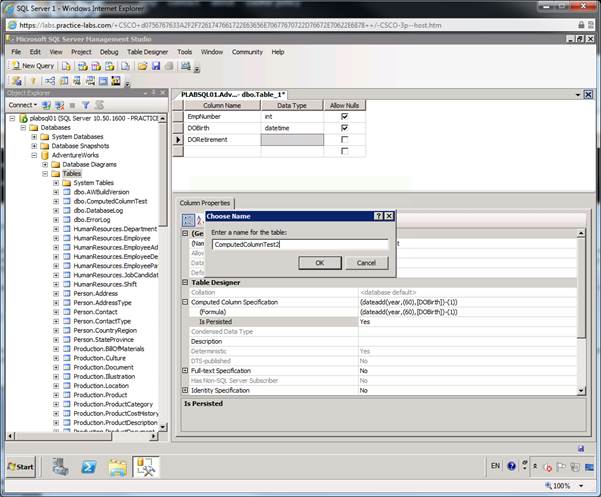
Закройте
и сохраните
таблицу как
ComputedColumnTest
2
нажав на
кнопку
Закрыть(
X
) сверху
справа
дизайнера
таблиц.
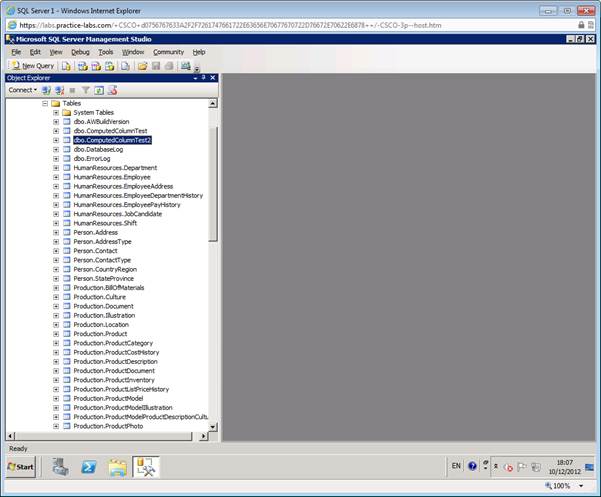
Обратите
внимание, что
ваша таблица
будет сверху
в папке с
таблицами
пока вы не
нажмете
кнопку
обновить в
инспекторе
объектов и
выполнится сортировка
по имени.
Operator costs
Each operator in a SQL Server execution plan is associated with a cost. The operator cost is relative to other costs in the execution plan. Usually, we need to concentrate on the costly operator and tuning the query around it.







In the event of a complicated execution plan, it might be challenging to identify the costly operator. In this case, you can use SET SHOWPLAN_ALL ON, and it will provide information in a tabular format.
You can also use the to break down the execution plan at each operator and statement level.
SQL Server Management Studio (SSMS) also gives the flexibility to find an operator based on search criteria. To do this, right-click on the execution plan and select Find Node. This will open a window with various search conditions. Specify your requirement, and it will point to the particular node, as shown below.
Alternatively, you can use Azure Data Studio and navigate to Run Current Query with Actual Plan under the Command palette. This gives an actual execution plan in a compact form, along with the Top operations to quickly identify costly operators.
Создание полного бэкапа базы.
В обозревателе объектов переходим к пункту «Управление \ Планы обслуживания». В контекстном меню выбираем «Создать план обслуживания».
В этом основном плане обслуживания будем создавать вложенные планы полного бэкапа, промежуточного (разностного) бэкапа, перестроение индекса и обновление статистики.
В созданном плане нажимаем кнопку «Добавление вложенного плана»
Вводим название «Полный бэкап» и описание. Задаем расписание для выполнения задания: Раз в неделю в воскресенье в 2:00.
Добавляем в созданный план задание. Для этого с панели элементов перетаскиваем в поле заданий вложенного плана элемент с названием Задача «Резервное копирование базы данных».
Открываем задание на редактирование: правой клавишей мыши по заданию, выбираем пункт «Изменить».
- Тип резервной копии: Полное;
- Базы данных: если выбрать «Все пользовательские базы данных», то будет выполняться бэкап всех созданных вами баз данных, но есть возможность указать на конкретные базы;
- Создать файл резервной копии для каждой базы данных: отмечаем пункт «Создавать вложенный каталог для каждой базы данных», чтобы удобнее было ориентироваться в бэкапах и указываем путь как папке, в которой будут храниться резервные копии;
- Отмечаем пункт «Проверять целостнойсть резервной копии»;
- Устанавливаем параметр «Сжимать резервные копии».
Метод 3-использование SQL Server Профайлер
если вы не можете запустить свой запрос напрямую (или ваш запрос не запускается медленно, когда вы выполняете его напрямую — помните, что мы хотим, чтобы план запроса выполнялся плохо), то вы можете захватить план с помощью трассировки профилировщика SQL Server. Идея состоит в том, чтобы запустить запрос во время выполнения трассировки, которая захватывает одно из событий «Showplan».
обратите внимание, что в зависимости от нагрузки можете использовать этот метод в производственной среде, однако вы должны очевидно, будьте осторожны. Механизмы профилирования SQL Server предназначены для минимизации влияния на базу данных, но это не означает, что не будет любой влияние на производительность
При интенсивном использовании базы данных могут возникнуть проблемы с фильтрацией и определением правильного плана трассировки. Вы должны, очевидно, проверить с вашим DBA, чтобы увидеть, если они счастливы с вами делать это на их драгоценной базе данных!
- откройте профилировщик SQL Server и создайте новая трассировка, соединяющаяся с нужной базой данных, в которую требуется записать трассировку.
- на вкладке » выбор событий «установите флажок» Показать все события», проверьте строку» производительность «- > «Showplan XML» и запустите трассировку.
- пока трассировка запущена, сделайте все, что вам нужно сделать, чтобы запустить медленный запрос.
- дождитесь завершения запроса и остановите трассировку.
- для сохранения трассировки щелкните правой кнопкой мыши на XML-плане в SQL Server Profiler и выберите » извлечь данные события…»чтобы сохранить план в файл в формате XML.
полученный план эквивалентен параметру «включить фактический план выполнения» в среде SQL Server Management Studio.
Управление базой данных
Большинство авторов, начинают рассматривать SQL, начиная с операторов получения данных из базы данных. Именно с этого начинается рассмотрение SQL-92, но у нас еще нет баз данных и не откуда брать данные. Мы же начнем с самого начала, т.е. с создания базы данных, создания таблиц и изменения их структуры. Когда у нас будет готова тестовая база данных, мы заполним ее данными и тогда уже научимся работать с этими данными.
Итак, в этой главе нам предстоит узнать:
- Как создавать базу данных с помощью SQL запросов;
- Как изменять параметры базы данных;
- Как создавать таблицы;
- Как изменять параметры таблицы.
Я рекомендую выполнять все задания, которые будут описаны в книге в этой главе, потому что созданная нами структура будет использоваться в последующих главах. Если вы хотите перейти к рассмотрению следующих глав, то рекомендую последовательно выполнить все сценарии из директории Chapter1 на компакт диске. Это позволит вам иметь готовую структуру базы данных, на которой можно будет тестировать запросы из следующих глав.
Большинство из описываемых в данной главе операторов SQL в равной степени будут работать на большинстве баз данных. Но в некоторых случаях могут быть отличие. Например, в MS Access нельзя создавать базу данных, потому что здесь база данных это файл, который создается с помощью одноименной программы. В других базах данных операторы создания баз данных и таблиц имеют точно такой же синтаксис, но может быть отличие в поддерживаемых параметрах из-за большего или меньшего количества возможностей.
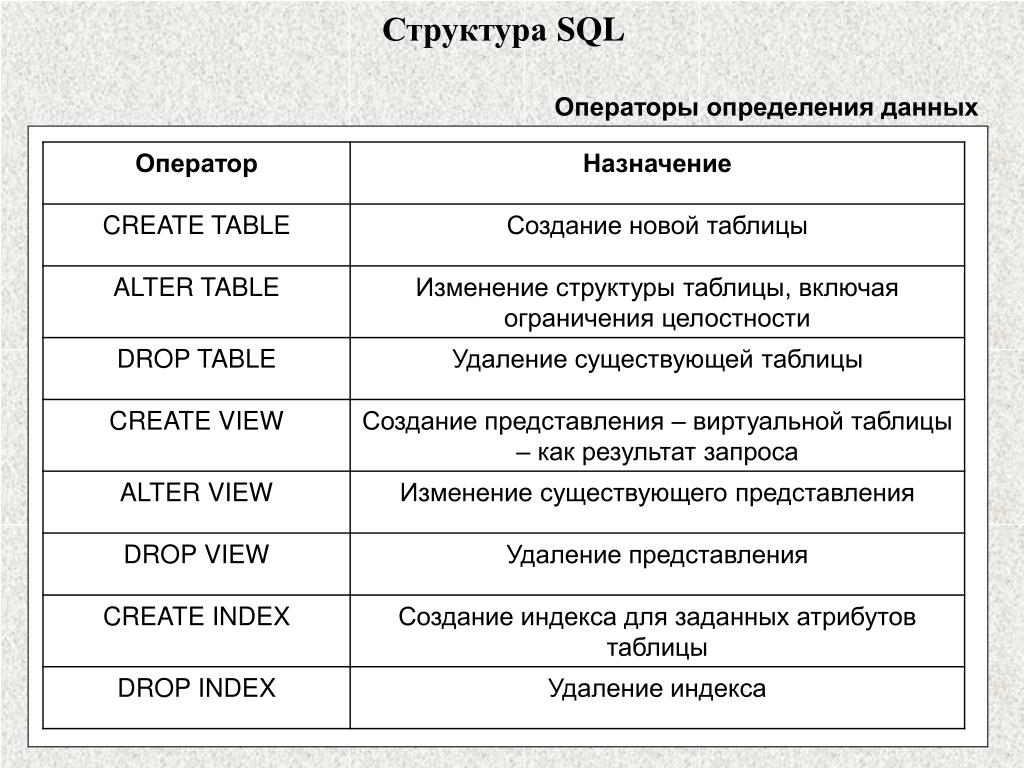
Операторы по описанию объектов базы данных выделают в отдельный язык (подязык SQL) — DDL (Data Definition Language, Язык Объявления Данных). Именно этот язык будет рассматриваться в этой главе, ведь нам предстоит научиться описывать данные таблицы.
Вставка значений в вычисляемое поле
Шаг 1
Вставьте
значения в
ранее
созданную
таблицу
используя
инструкцию
INSERTINTO
как
показано
ниже в коде.
Выполните
кодвновомокнезапросаNew
Query
вMicrosoftSQLServerManagementStudio:
USE
AdventureWorks
GO
INSERT
INTO ComputedColumnTest (EmpNumber, DOBirth)
VALUES
(1,
‘1977-12-23’),
(2,
‘1980-01-01’),
(3,
‘1968-03-23’),
(4,
‘1988-12-12’),
(5,
‘1975-06-15’)
GO

Нажмите
кнопку
Execute
чтобы
выполнить
SQL код.
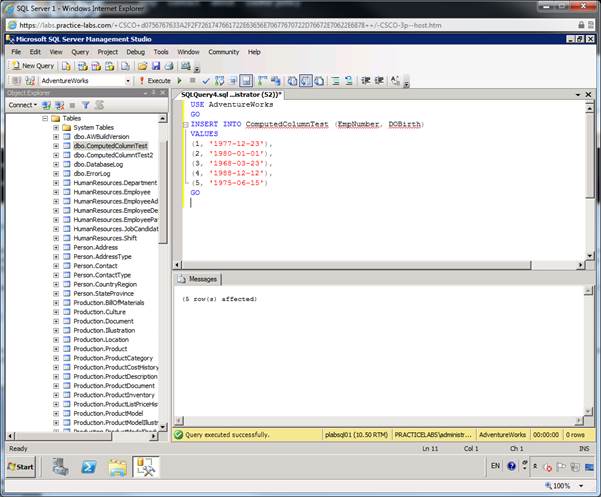
Примечание:
Поскольку
поле
DORetirement
является
вычисляемым,
в него не
нужно вставлять
значения.
Шаг 2
Вы
можете
увидеть
вычисленные
значении для
поля
DORetirement
используя
предложение
SELECT
SELECT
*
FROM
dbo
.
ComputedColumnTest
GO
Когда
напечатаете
SQL
инструкции,
опят нажмите
кнопку
Execute
.