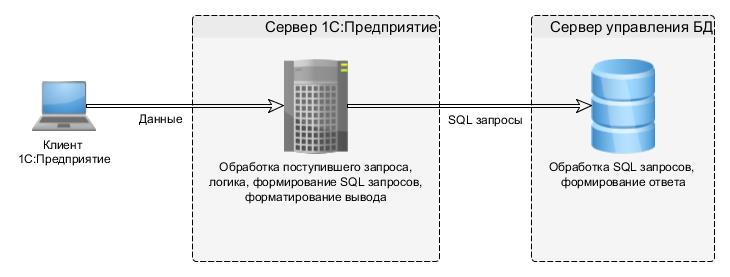
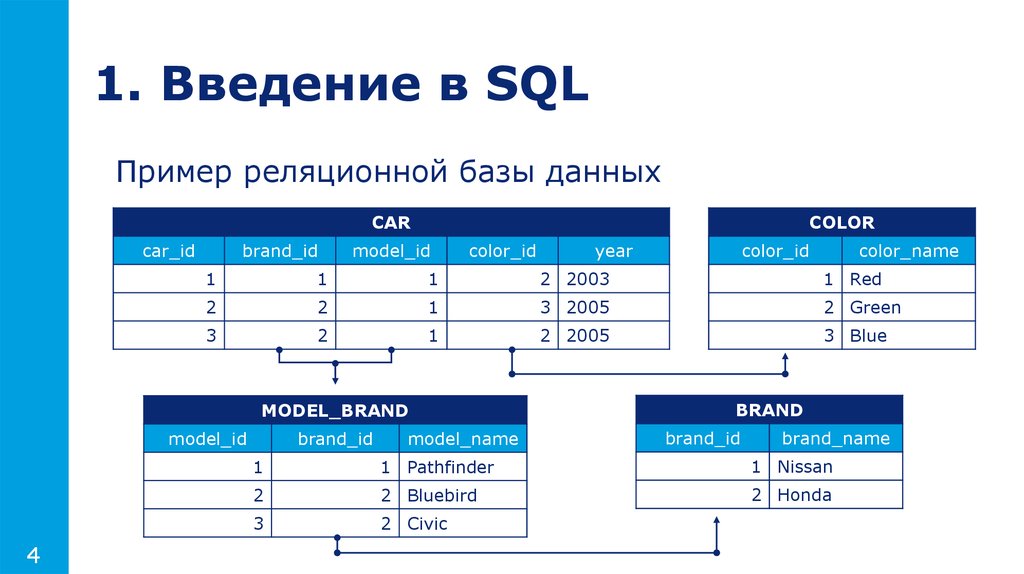
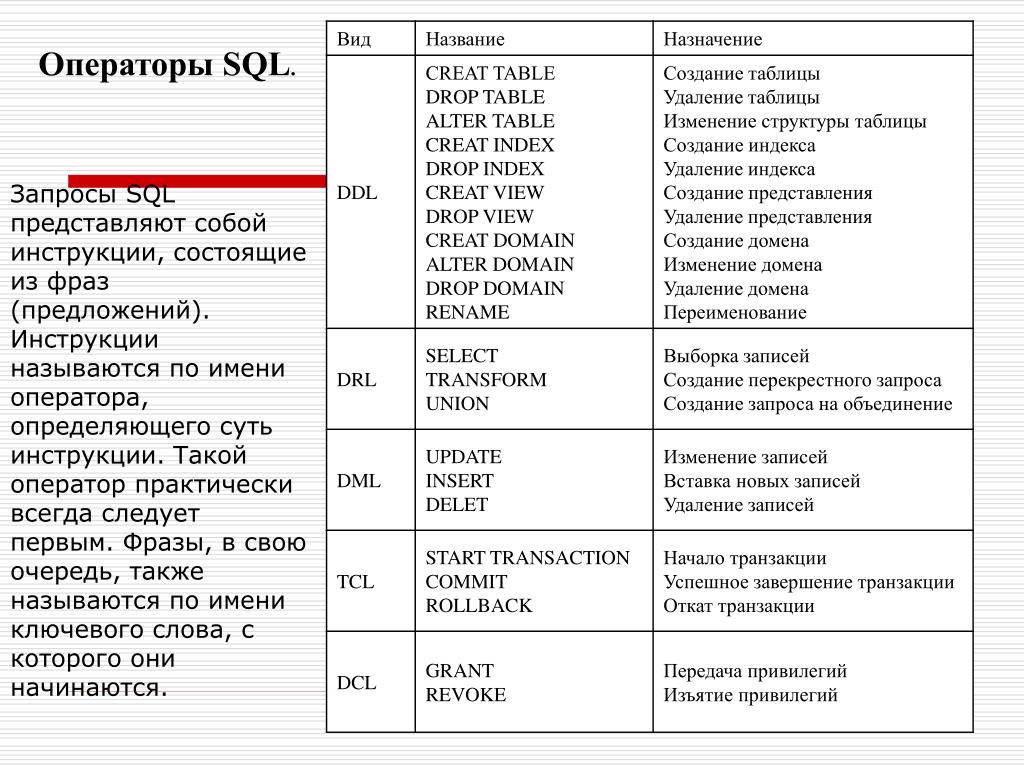
Создание схемы базы данных
В этом разделе описывается создание схемы в SQL Server с помощью среды SQL Server Management Studio или Transact-SQL.
Перед началом
Ограничения
Новая схема принадлежит одному из следующих участников уровня базы данных: пользователю базы данных, роли базы данных или роли приложения. Объекты, создаваемые в схеме, принадлежат владельцу схемы и имеют значение NULL для principal_id в sys.objects. Владение объектами, содержащимися в схеме, можно передать любому участнику уровня базы данных, однако у владельца схемы всегда остается разрешение CONTROL на объекты в схеме.
Если при создании объекта базы данных указать допустимый субъект домена (пользователя или группу) в качестве владельца объекта, то этот субъект добавляется в базу данных в качестве схемы. Новая схема принадлежит этому субъекту домена.
безопасность
Permissions
Требует разрешения CREATE SCHEMA в базе данных.
Чтобы назначить другого пользователя владельцем создаваемой схемы, у участника должно быть разрешение IMPERSONATE на этого пользователя. Если роль базы данных указана в качестве владельца, то вызывающий объект должен входить в роль или иметь на нее разрешение ALTER.
Использование среды SQL Server Management Studio
Создание схемы
В обозревателе объектов раскройте папку Базы данных .
Разверните базу данных, в которой создается новая схема базы данных.
Щелкните правой кнопкой мыши папку Безопасность , укажите на пункт Создать и выберите Схема.
В диалоговом окне Схема — создать на странице Общие введите имя новой схемы в поле Имя схемы .
В поле Владелец схемы введите имя пользователя или роли базы данных, которые будут владельцем схемы. Также можно нажать кнопку Поиск , чтобы открыть диалоговое окно Поиск ролей и пользователей .
Нажмите кнопку ОК.
Диалоговое окно не будет отображаться, если вы создаете схему с помощью SSMS для Базы данных SQL Azure или Azure Synapse Analytics. Потребуется создать схему шаблона T-SQL.
Дополнительные параметры
Диалоговое окно Схема — создать также содержит параметры на двух дополнительных страницах: Разрешения и Расширенные свойства.
На странице Разрешения перечислены все возможные защищаемые объекты и разрешения на эти объекты, которые могут быть предоставлены для имени входа.
Страница Расширенные свойства позволяет добавлять пользовательские свойства пользователям базы данных.
Использование Transact-SQL
Создание схемы
В обозревателе объектов подключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
В следующем примере создается схема Chains , а затем таблица Sizes .
Дополнительные операции могут быть выполнены в рамках одной инструкции. В следующем примере создается принадлежащая Annik схема Sprockets , которая содержит таблицу NineProngs . Инструкция предоставляет разрешение SELECT для Mandar и запрещает SELECT для Prasanna.
Чтобы просмотреть схемы в этой базе данных, выполните следующую инструкцию.
Dropping a schema
You can drop a schema in a SQL Server database, but the schema should not hold any objects. For example, if I try to drop the schema, it gives an error that you cannot drop the schema because the object GetEmpData is referencing it.

Therefore, you can either transfer the object to a different schema or drop the objects first. For example, let us drop GetEmpData stored procedures and then try to drop the schema. We again got an error because we have in the schema.
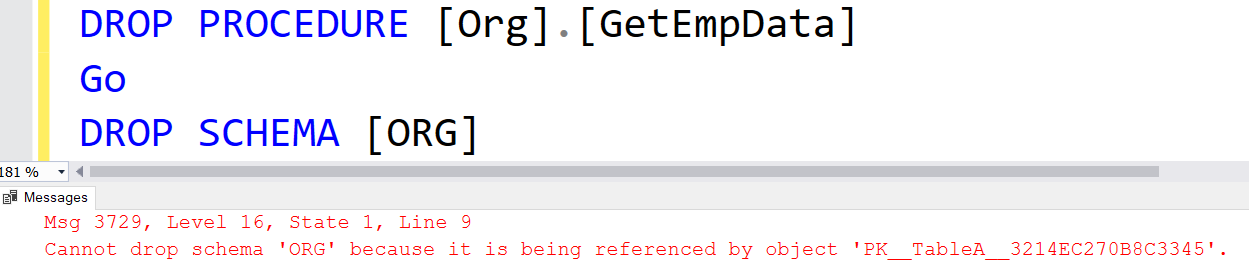
Once we dropped or moved all objects in the database schema, you can then drop the schema.

Note: You cannot drop system schemas such as dbo, information_schema, sys.
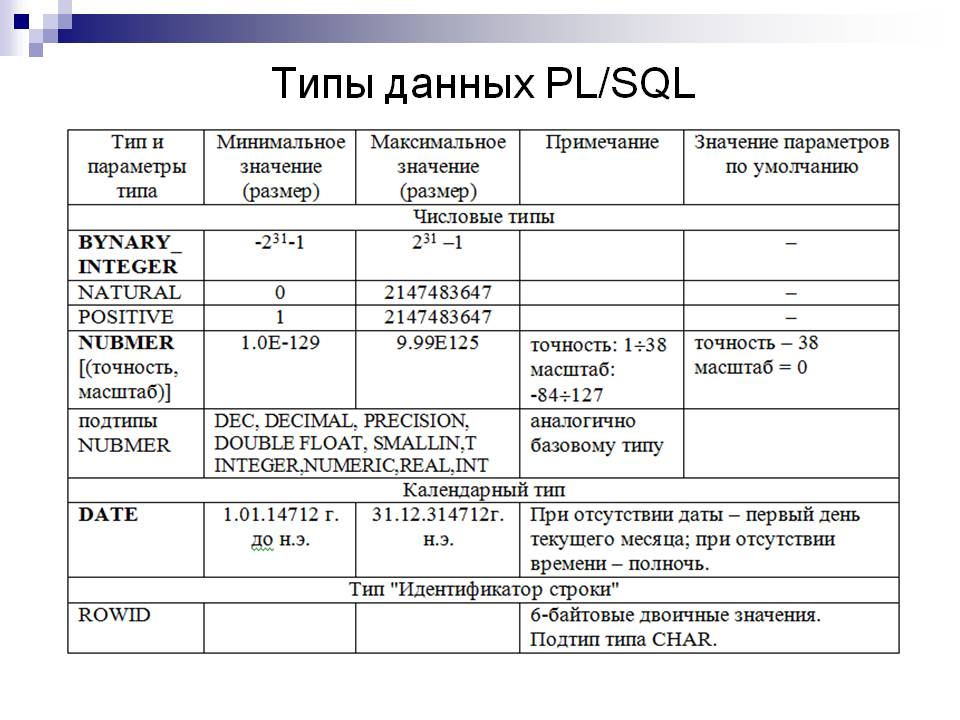
TYPE_ID (Transact-SQL)
Возвращает идентификатор для указанного имени типа данных.
Синтаксис
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
type_name Имя типа данных. Аргумент type_name имеет тип nvarchar. Аргумент type_name может иметь системный или определяемый пользователем тип данных.
Исключения
Возвращает значение NULL в случае ошибки или если участник не имеет разрешений для просмотра объекта.
В SQL Server пользователь может просматривать только метаданные защищаемых объектов, которыми он владеет или на которые ему были предоставлены разрешения. Это означает, что встроенные функции, создающие метаданные, такие как TYPE_ID могут вернуть значение NULL в случае, если пользователь не имеет разрешений на объект. Дополнительные сведения см. в разделе Metadata Visibility Configuration.
Комментарии
Функция TYPE_ID возвращает NULL, если имя типа неверно или если вызывающий не имеет необходимых разрешений на использование этого типа.
Примеры
Б. Поиск значения функции TYPE ID для системного типа данных
SQL Server schemas
SQL Server provides the following built-in logical schemas:
- dbo
- sys
- guest
- INFORMATION_SCHEMA
Every SQL Server schema must have a database user as a schema owner. The schema owner has full control over the schema. You can also change the schema owner or move objects from one schema to another.
SQL Server schemas provide the following benefits:
- Provides more flexibility and control for managing database objects in logical groups
- Allows you to move objects among different schemas quickly
- Enables you to manage object security on the schema level
- Allows users to manage logical groups of objects within a database
- Allows users to transfer ownership among various schemas
Suppose for your organization’s database, you want to group objects based on departments. For example, the tables and stored procedures for the HR department should be logically grouped in the schema. Similarly, finance department tables should be in the schema. Each schema (logical group) contains SQL Server objects such as tables, stored procedures, views, functions, indexes, types and synonyms.
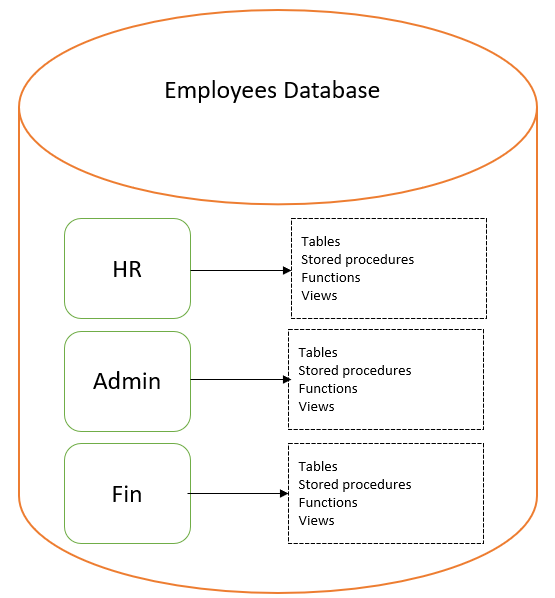
Note: The schema is a database-scoped entity. You can have the same schema in different databases of a SQL Server instance.
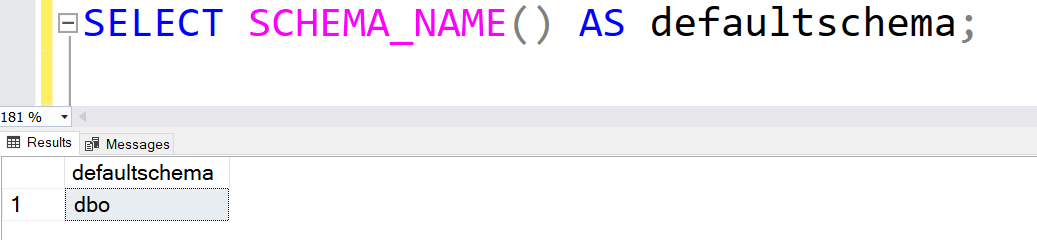
By default, SQL Server uses schema for all objects in a database. We can query SCHEMA_NAME() to get the default schema for the connected user.
SELECT SCHEMA_NAME() AS defaultschema;
INFORMATION_SCHEMA и Oracle
Информационная схема ( INFORMATION_SCHEMA ) является стандартным представлением метаданных в языке SQL. Исторически каждый производитель реляционных СУБД предоставлял системные таблицы, которые содержали мета-информацию — имена таблиц, столбцов, ограничений, типы данных столбцов и т.д. Структура и состав системных таблиц могут меняться в разных версиях продукта, однако поддержка информационной схемы дает возможность менять структуру системных таблиц без изменения способа доступа к метаданным. Другим преимуществом применения INFORMATION_SCHEMA является то, что запросы к метаданным не зависят от используемой СУБД.
Из ведущих производителей, пожалуй, только Oracle не поддерживает INFORMATION_SCHEMA. Справедливости ради следует сказать, что Oracle предоставляет возможность использовать системные представления вместо непосредственного обращения к системным таблицам, что также позволяет безопасно изменять структуру системных таблиц.
Приведем ряд типичных запросов в стандартном варианте и для Oracle.
Что такое СУБД
Чтобы понять, что такое СУБД, нужно сначала узнать, что такое база данных (БД).
База данных — это набор упорядоченных и структурированных данных, которые хранятся на определённом компьютере. Проще всего представить её как большую Excel-таблицу, где у каждого элемента (строки) есть определённые свойства (столбцы).
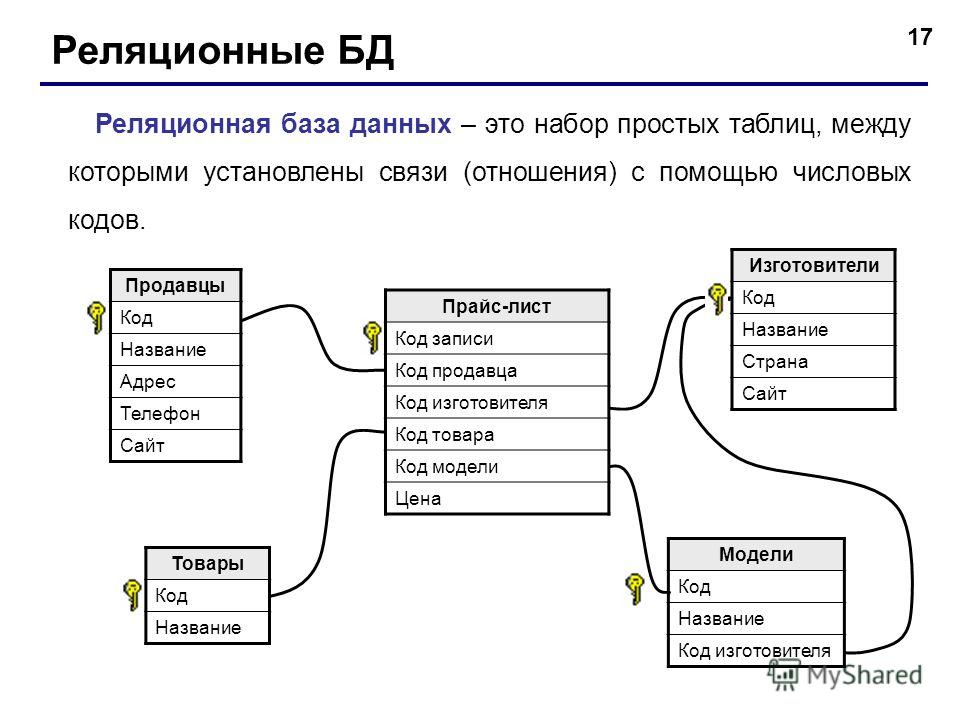
Если создать базу данных для магазина продуктов, то у каждого товара — например, жвачки, шоколадки и бутылки воды, — будут свойства: цена, количество штук в наличии и срок годности.
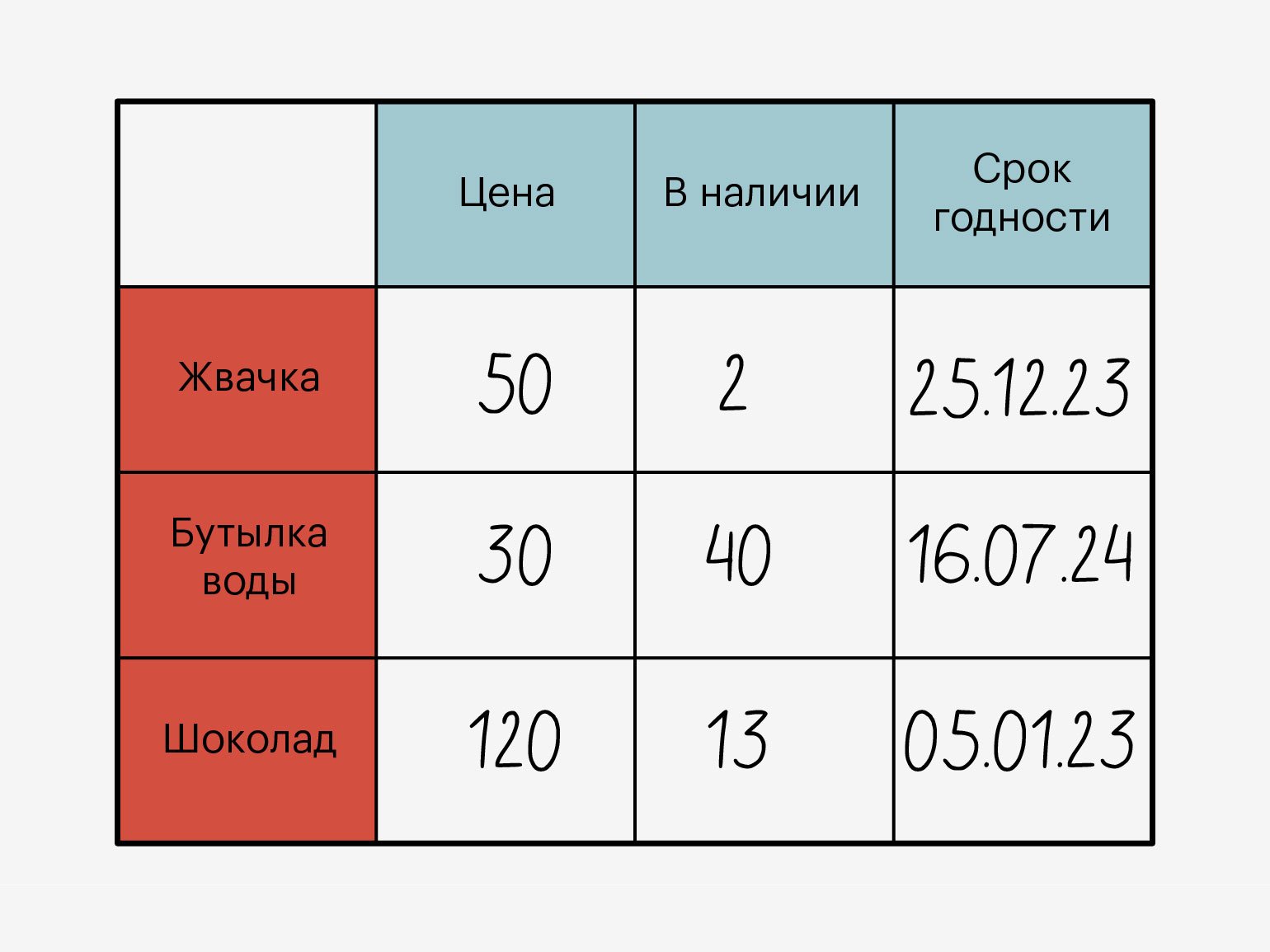
Базу данных можно представить как таблицуИллюстрация: Оля Ежак для Skillbox Media
Базы данных — это просто файлы на диске компьютера, куда можно записывать новые элементы. Но сами БД ничего не умеют и для них нужно писать свои методы для управления — например, для добавления нового элемента или поиска нужной записи. Чтобы облегчить работу программистам, придумали СУБД.
Система управления базами данных (СУБД) — это набор инструментов, которые позволяют удобно управлять базами данных: удалять, добавлять, фильтровать и находить элементы, менять их структуру и создавать резервные копии.
СУБД можно представить как прослойку между базой данных и пользовательскими запросами к ней.
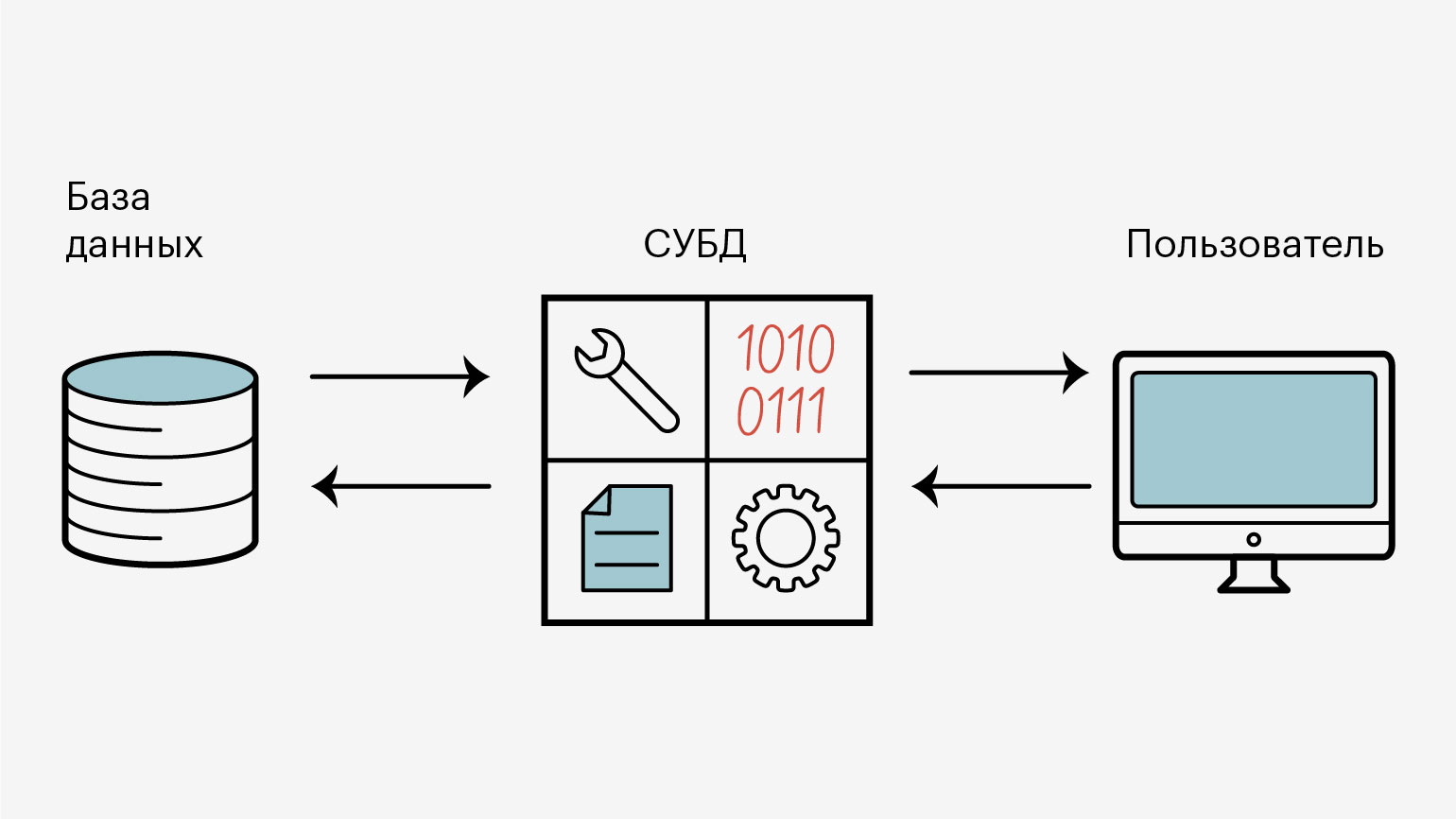
СУБД — это прослойка между базой данных и пользователемИллюстрация: Оля Ежак для Skillbox Media
Когда пользователь нажимает на кнопку на сайте — например, чтобы скачать картинку, — сайт составляет специальный запрос к базе данных и отправляет его в СУБД. Она разбирает его и ищет в базе данных запрашиваемую информацию, а затем возвращает обратно сайту. Он уже конвертирует их в читаемый для пользователя вид и отдаёт ему.
Без СУБД разработчикам пришлось бы самостоятельно искать в файлах баз данных информацию, которая им нужна. Можно сказать, что база данных без СУБД — это как машина без кузова. В теории это машина: можно её заправлять, менять масло и детали. Но нормально поездить на ней не получится. Придётся сначала всё прикрутить, сделать кузов и только потом уже ехать.

Базы данных без СУБД — примерно то же, что эта машинаИзображение: Big Pants Production / Shutterstock / Skillbox Media
Что такое СУБД
У Вас может возникнуть вопрос, если база данных это некая информация, которая хранится в таблицах, то как она выглядит физически? Как на нее посмотреть в целом?
Если очень коротко, то это просто файл, созданный в специальном формате, именно так и выглядит база данных (в большинстве случаев БД включает несколько файлов, но сейчас на этом уровне это не так важно). Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е
реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами
Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е. реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами.
Таким инструментом как раз и выступает СУБД – это система управления базами данных, сокращенно СУБД.
«Стандартные отчеты» в пользовательском интерфейсе Management Studio
SQL Server Management Studio предоставляет минимальный необходимый набор стандартных отчетов для получения информации о размере базы данных/ее файлов/таблиц/индексов в режиме пользовательского интерфейса.
Доступ к этим отчетам может быть выполнен через «Обозреватель объектов» (Object explorer) → Правый клик мыши по базе данных → «Отчеты» (Reports) → «Стандартный отчет» (Standard reports)Стандартные отчеты по использованию дискового пространства
Отчет «Занято места на диске» (Disk Usage)
Отчет содержит общие сведения об использовании места на диске базой данных.
В отчете представлена информация следующего рода:
- Общий объем, занятый на диске (Total space reserved)
- Место, занятое файлами данных (Data files space reserved)
- Место, занятое журналом транзакций (Transaction log space reserved)
- Отражает графически процент пространств в составе файлов данных: индексов (index), данных (data), не выделенного (unallocated) и не используемого (unused)
- Отражает графически процент примененного (used) и неиспользуемого (unused) пространства в составе журнала транзакций
- Выводит записи событий автоматического увеличения (autogrow) и/или сжатия (autoshrink) для базы данных
- Выводит информацию о месте на диске, используемом файлами данных
Отчет «Занято места на диске» (Disk Usage)
Отчет содержит подробные данные об использовании места на диске таблицами, расположенными в базе данных. Отличие этих двух отчетов заключается лишь в том что в отчете «By Top Tables» вывод происходит только для «верхних» (первых) 1000 таблиц.
В отчете представлена информация:
- Количество записей в таблице базы данных (Records)
- Размер зарезервированного пространства на диске (Reserved)
- Размер данных на диске (Data)
- Общий размер индексов таблицы на диске (Indexes)
- Размер не используемого пространства (Unused)
Отчет «Использование дисковой памяти таблицей» (Disk Usage by Table)
Отчет «Использование дисковой памяти секцией» (Disk Usage by Partition)
Отчет содержит подробные данные об использовании места на диске индексом и секциями, расположенными в базе данных.
Хотел бы обратить Ваше внимание что в данном отчете неверно рассчитывается дисковое пространство по кластерному индексу. Для получения реально используемого дискового пространства кластерным индексом можно: из «объема, используемого всеми индексами таблицы» (указанном в отчете «Использование дисковой памяти таблицей») вычесть «объем всех не кластерных индексов» (по отчету «Использование дисковой памяти секцией»). В отчете представлена информация:
В отчете представлена информация:
- Число записей в индексе/секции (Records)
- Зарезервированное пространство на диске (Reserved)
- Используемое пространство на диске (Used)
Отчет «Использование дисковой памяти секцией» (Disk Usage by Partition)
Three Essential SQL Server Skills for Developers
SQL is the first and most obvious skill that you need to be competent in. One of the primary reasons for learning this scripting language (besides the fact that it’s fun) is how transferable it is—even across other RDBMSs. Of course, I am talking about American National Standards Institute (ANSI) Standard SQL (SQL) syntax, not necessarily T-SQL, which is Microsoft’s dialect of SQL. Personally, I have also found that it is easier to learn new elements of SQL/T-SQL syntax than to adjust to new features on a graphical user interface. For the purposes of this article, I’ll focus on T-SQL based on the assumption that anyone reading this piece is some variation of a SQL Server developer.
PowerShell is the second skill. PowerShell is another scripting language that allows users to automate a variety of useful tasks, which often involve running SQL Server Reporting Services reports, scheduling jobs, and basically doing a lot of database administrator (DBA) work. What makes PowerShell even more attractive, however, is the fact that it is a replacement for the Windows DOS batch language (i.e., the batch language that you use in command prompt) that uses .NET objects and methods. Yet another reason for its value is the fact that, unlike T-SQL, PowerShell can automate tasks that span the Windows and SQL Server environments.
Besides these two rich scripting languages, there’s a third skill that would greatly benefit any SQL Server user who is well-versed in it, which is the use of metadata. Technically, understanding SQL Server metadata (for the purposes of this article, all references of “metadata” will imply “SQL Server” unless explicitly specified) is a subject to study and an opportunity to exercise and apply skills (i.e., memorizing relationships and learning T-SQL)—not really a skill in itself. For this reason, whenever I refer to “the use of metadata,” I mean, “how well a developer applies knowledge of metadata in T-SQL.”
I would argue, however, that metadata is also one of the most overlooked and underestimated topics within the developer community (while learning T-SQL is clearly not). Many introductory SQL Server or T-SQL books do not even discuss it until later chapters, if at all, and even then, in little detail.
Familiarizing yourself with SQL Server metadata is a considerably more valuable skill than most instructors seem to think, particularly for beginners, because it is a practical means of applying knowledge in theoretical concepts within the SQL language, database design, and both physical and logical processing.
Even for more experienced developers and DBAs, SQL Server metadata can be extremely valuable, because its utility scales with your creativity and competence in other areas of database design and programming. Throughout the article, I will provide examples of T-SQL scripts that increase in complexity and demonstrate how familiarizing yourself with metadata can prove invaluable when trying to solve problems.
Before I dive into the examples, however, I should make a couple of important general points. Microsoft’s website, commonly referred to as the “Books Online” (BOL), is the single greatest resource that I can recommend on this topic. In fact, you should view this page to familiarize yourself with the various types of metadata and this page on how you should access the metadata (i.e., use catalog views).
Как проектируют базы данных
Обычно современные СУБД содержат
средства, позволяющие создавать таблицы и ключи.
Существуют и утилиты, поставляемые отдельно от
СУБД (и даже обслуживающие несколько различных
СУБД одновременно), позволяющие создавать
таблицы, ключи и связи.
Еще один способ создать таблицы, ключи
и связи в базе данных — это написание так
называемого DDL-сценария (DDL — Data Definition Language; о нем
мы поговорим чуть позже).
Наконец, есть еще один способ, который
становится все более и более популярным, — это
использование специальных средств, называемых CASE-средствами (CASE означает Computer-Aided
System Engineering). Существует несколько типов
CASE-средств, но для создания баз данных чаще всего
используются инструменты для создания диаграмм «сущность-связь» (entity-relationship diagrams, E/R
diagrams). С помощью этих инструментов создается так
называемая логическая модель данных, описывающая факты и объекты,
подлежащие регистрации в ней (в таких моделях
прототипы таблиц называются сущностями (entities), а поля — их
атрибутами (attributes). После установления связей между
сущностями, определения атрибутов и проведения
нормализации, создается так называемая физическая модель
данных для конкретной СУБД, в которой
определяются все таблицы, поля и другие объекты
базы данных. После этого можно сгенерировать
либо саму базу данных, либо DDL-сценарий для ее
создания.
Список наиболее популярных в настоящее время CASE-средств.
Начало работы в Microsoft SQL Server Management Studio
Для создания баз данных используем среду Microsoft SQL Server Management Studio. На запрос соединения с сервером выбираем (рис. 1):
Тип сервера: Компонент Database Engine
Имя сервера: SQL-MS.
Под таким именем в домене fizmat.vspu.ru. доступна машина, на которой установлены серверные компоненты MS SQL Server 2005. Можно попробовать выбрать сервер из выпадающего списка серверов. Можно также обратиться к этой машине по IP-адресу 192.168.10.152 из локальной сети.

Проверка подлинности: Проверка подлинности SQL Server.
Такая настройка позволяет создавать пользователей данного экземпляра SQL Server независимо от компьютера, с которого производится вход.
Имя входа: studentMBS21.
Пароль: student.
Рисунок 1. Окно входа в Microsoft SQL Server Management Studio 2005
Примечание. Пользователь studentMBS21 обладает большими полномочиями на этом сервере, поэтому пользоваться им надо очень аккуратно. Под этим пользователем мы создадим базу данных, а заполнять её и производить поиск по ней мы будем под другими пользователями. Предпочтительнее всего использовать свою учетную запись в домене fizmat.vspu.ru. В этом случае надо выбирать проверку подлинности Windows.
Теперь нажимаем кнопку «Параметры» и выбираем (рис. 2):
Соединение с базой данных → Обзор сервера… → Пользовательские базы данных → trial_base.
Сетевой протокол → TCP/IP
Нажимаем кнопку «Соединить».
Рисунок 2. Окно входа в Microsoft SQL Server Management Studio 2005 (вкладка Параметры)
Примечание. База данных trial_base является базой данной по умолчанию для пользователя studentMBS21, она была создана при регистрации этого пользователя. В случае, когда права доступа пользователя не ограничены (как в рассматриваемом случае), вкладку Параметры можно не открывать. Если же пользователь имеет доступ только к определенным базам данных, при подключении к серверу нужно одну из этих баз указывать.
После успешного соединения с базой данных на экране видим следующую картинку (рис. 3):
Рисунок 3. Подключение к SQL — серверу установлено
Среда MS SQL Management Studio предоставляет удобный инструментарий для создания, редактирования, заполнения баз данных. Но настоящие профессионалы в своей работе редко пользуются этой средой, а для выполнения своих задач используют SQL-запросы. Мы будем пользоваться, когда это удобно и наглядно, графическим режимом, но основной упор будем делать на освоении базы языка SQL.
Visual Schema Browsing
If you’re using a good visual interface to PostgreSQL, browsing the schema can be really easy. Below we also show you how to , but unless you just can’t use one of these tools I highly suggest you browse the schema visually. It’s just easier.
Schemas in PGAdmin
Once connected to a database, you can expand the trees in the left sidebar in PGAdmin to find the database, schema, tables and columns available:
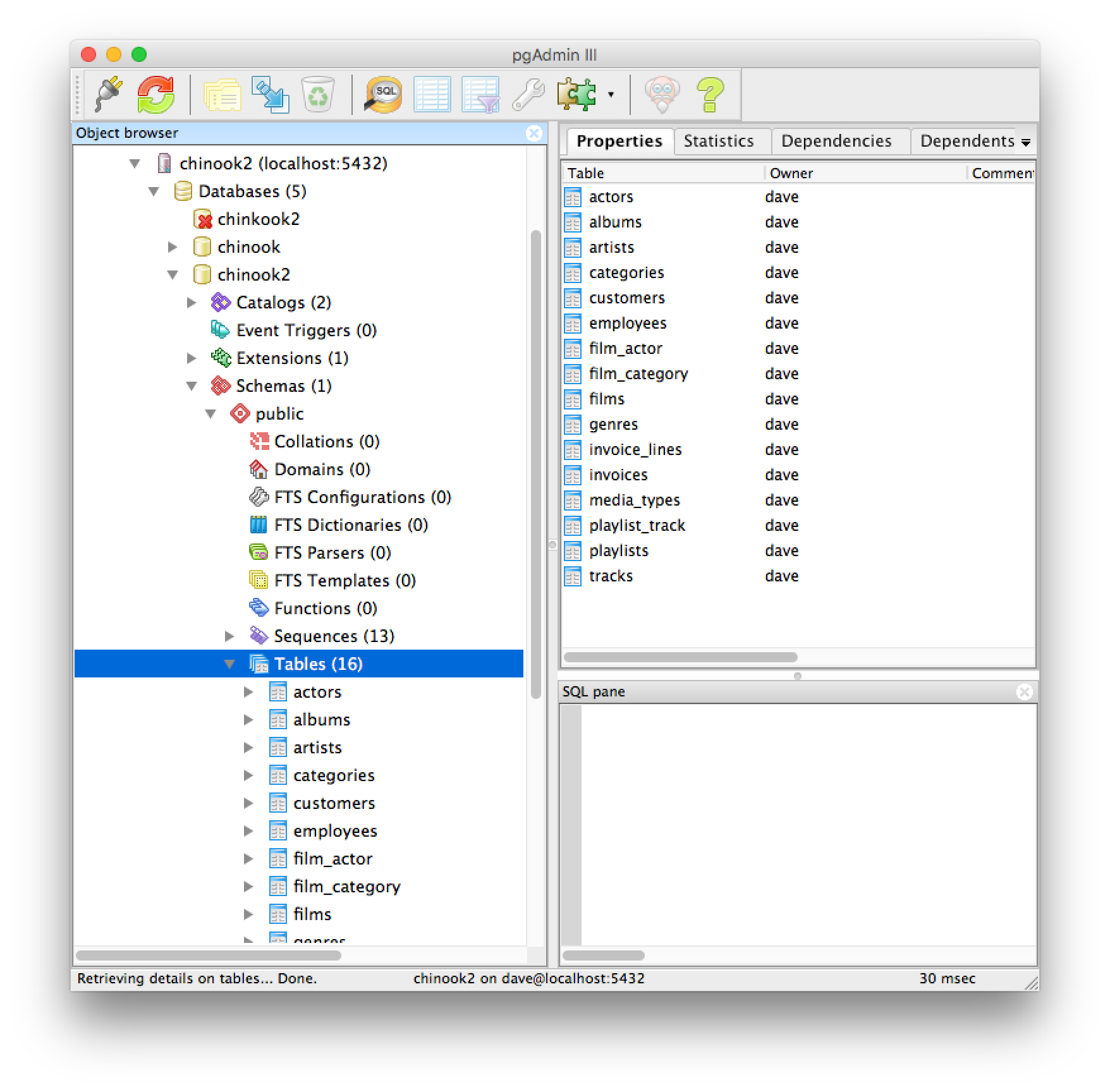
The “Properties” tab in the right top of the interface will display all of the extra properties that the information_schema holds on the table or column including default values, data type, and more.
Schemas in Chartio
Chartio’s schema viewer simply lists the tables in the Schema tab of any data source connection.
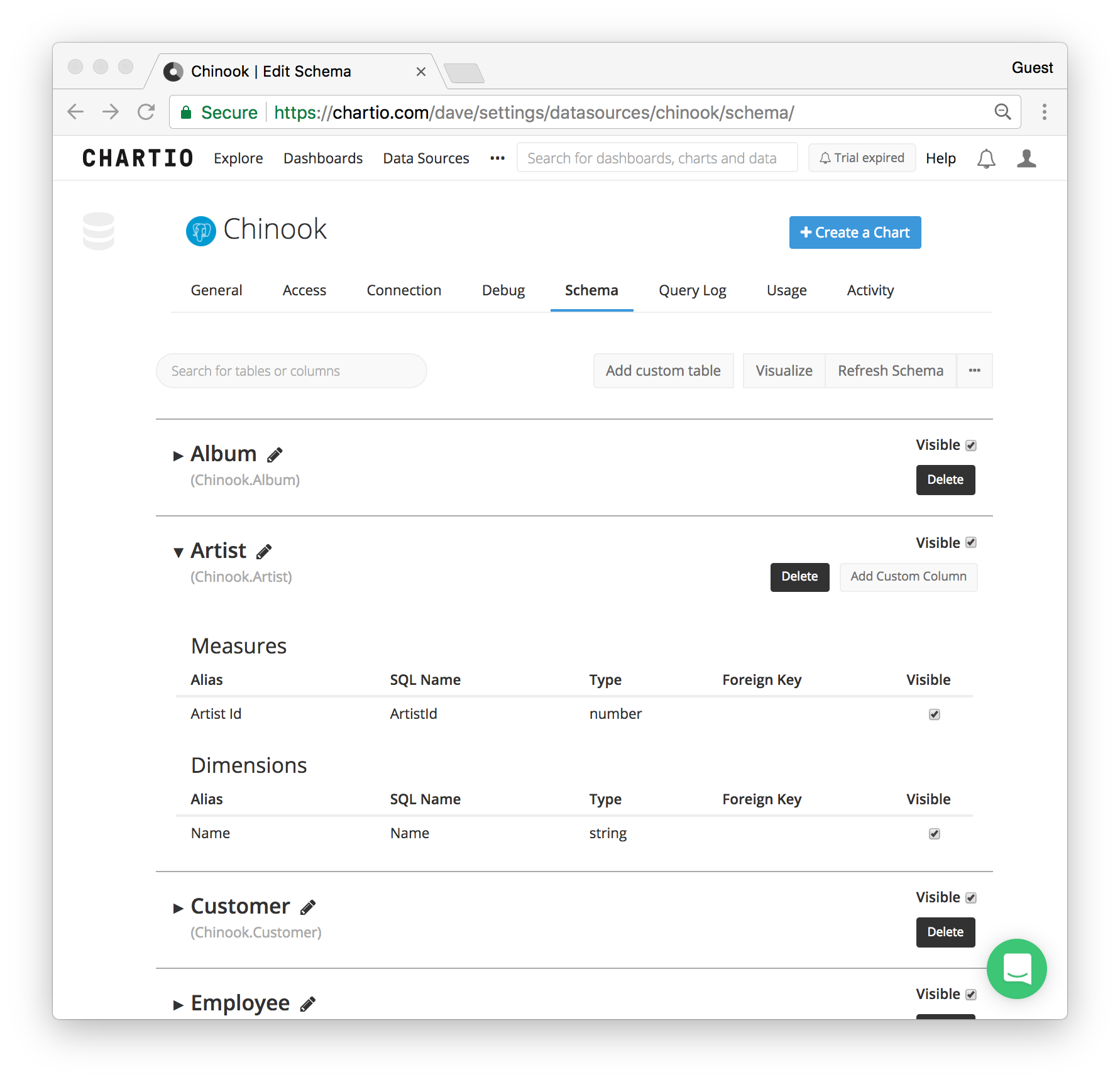
Each table can be expanded to show the columns underneath. In Chartio you can actually change the name/alias, define relationships and create custom tables and columns. This isn’t mapped back to database, but used only for the Chartio Visual Data Explorer.
Clicking on “Visualize” from the data source Schema page will also create a nice visualization of all of the tables, with their columns listed. In this view, relationships that are defined are also drawn as connections from one table to another.
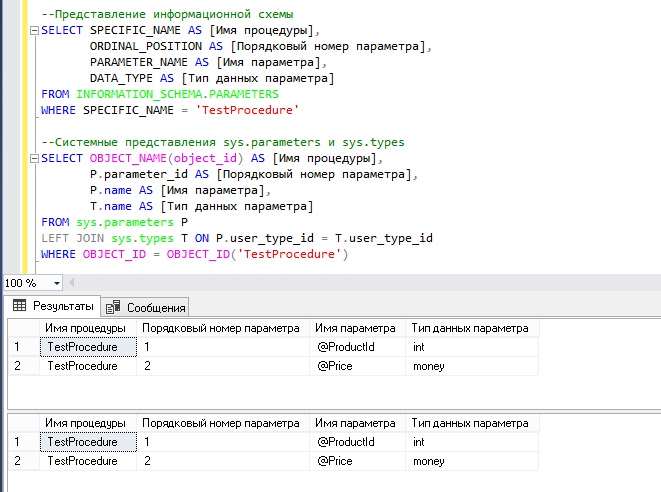
Пример 3. Получаем список и описание всех параметров хранимой процедуры в SQL сервере
Сейчас давайте рассмотрим случай, когда Вам необходимо получить список параметров процедуры, включая их тип данных. В этом случае можно использовать представление информационной схемы PARAMETERS (TestProcedure, как помните, имя моей тестовой процедуры).
SELECT SPECIFIC_NAME AS ,
ORDINAL_POSITION AS ,
PARAMETER_NAME AS ,
DATA_TYPE AS
FROM INFORMATION_SCHEMA.PARAMETERS
WHERE SPECIFIC_NAME = 'TestProcedure'
В данном случае, также можно использовать альтернативный вариант, а именно системное представление sys.parameters, только в данном случае потребуется дополнительное объединение с системным представлением sys.types и вызов функции OBJECT_NAME.
SELECT OBJECT_NAME(object_id) AS ,
P.parameter_id AS ,
P.name AS ,
T.name AS
FROM sys.parameters P
LEFT JOIN sys.types T ON P.user_type_id = T.user_type_id
WHERE OBJECT_ID = OBJECT_ID('TestProcedure')
На этом у меня все, надеюсь, статья была Вам полезной, всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL, пока!
Нравится7Не нравится1
Что такое схемы базы данных?
Когда дело доходит до выбора базы данных, одна из вещей, о которой вы должны подумать, — это форма ваших данных, модель, которой они будут следовать, и то, как сформированные отношения помогут нам при разработке схемы.
Схема базы данных — это план или архитектура того, как будут выглядеть наши данные. Он не содержит самих данных, а вместо этого описывает форму данных и то, как они могут быть связаны с другими таблицами или моделями. Запись в нашей базе данных будет экземпляром схемы базы данных. Он будет содержать все свойства, описанные в схеме.
Думайте о схеме базы данных как о типе структуры данных. Он представляет собой структуру и структуру содержимого данных организации.
Схема базы данных будет включать:
- Все важные или важные данные
- Единое форматирование для всех записей данных
- Уникальные ключи для всех записей и объектов базы данных
- Каждый столбец в таблице имеет имя и тип данных.
Размер и сложность схемы вашей базы данных зависит от размера вашего проекта. Визуальный стиль схемы базы данных позволяет программистам правильно структурировать базу данных и ее взаимосвязи, прежде чем переходить к коду. Процесс планирования дизайна базы данных называется моделированием данных.
Схемы важны для проектирования систем управления базами данных (СУБД) или систем управления реляционными базами данных (СУБД). СУБД — это программное обеспечение, которое хранит и извлекает пользовательские данные безопасным способом в соответствии с концепцией ACID.
Во многих компаниях ответственность за проектирование базы данных и СУБД обычно ложится на роль администратора базы данных (DBA). Администраторы баз данных несут ответственность за обеспечение беспрепятственного доступа к информации аналитикам данных и пользователям баз данных. Они работают вместе с командами менеджеров для планирования и безопасного управления базой данных организации.
Type of Database in SQL Server
There are two types of databases in SQL Server: System Database and User Database.
System databases are created automatically when SQL Server is installed. They are used by SSMS and other SQL Server APIs and tools, so it is not recommended to modify the system databases manually.
The followings are the system databases:
-
master: master database stores all system level information for an instance of SQL Server.
It includes instance-wide metadata such as logon accounts, endpoints, linked servers, and system configuration settings. - model: model database is used as a template for all databases created on the instance of SQL Server
- msdb: msdb database is used by SQL Server Agent for scheduling alerts and jobs and by other features such as SQL Server Management Studio, Service Broker and Database Mail.
- tempdb: tempdb database is used to hold temporary objects, intermediate result sets, and internal objects that the database engine creates.
User-defined Databases are created by the database user using T-SQL or SSMS for your application data.
A maximum of 32767 databases can be created in an SQL Server instance.
There are two ways to create a new user database in SQL Server:
Переходим к делу
Для примера возьмем задачу по автоматизации отчета по эффективности контекстной рекламы.
К данному отчету заказчиком предъявляются следующие требования:
- Отчет должен содержать исторические данные по вчерашний день;
- Отчет должен обновляться ежедневно в автоматизированном режиме;
- Помимо Power BI, должна быть возможность подключения к отчету через Excel.
Также отчет должен содержать следующие параметры и показатели:
- Дата;
- Источник/Канал
- Кампания
- Сумма расходов;
- Кол-во показов;
- Кол-во кликов;
- Кол-во сеансов;
- Кол-во заказов;
- Доход;
- Рассчитываемые показатели — CPC, CR и ROMI.
Естественно, все данные должны быть предварительно загружены в хранилище, но это тема отдельного поста и обычно этим занимаются data-инженеры. Мы же с вами аналитики и используем те данные, которые для нас любезно сложили в DWH (хранилище данных).

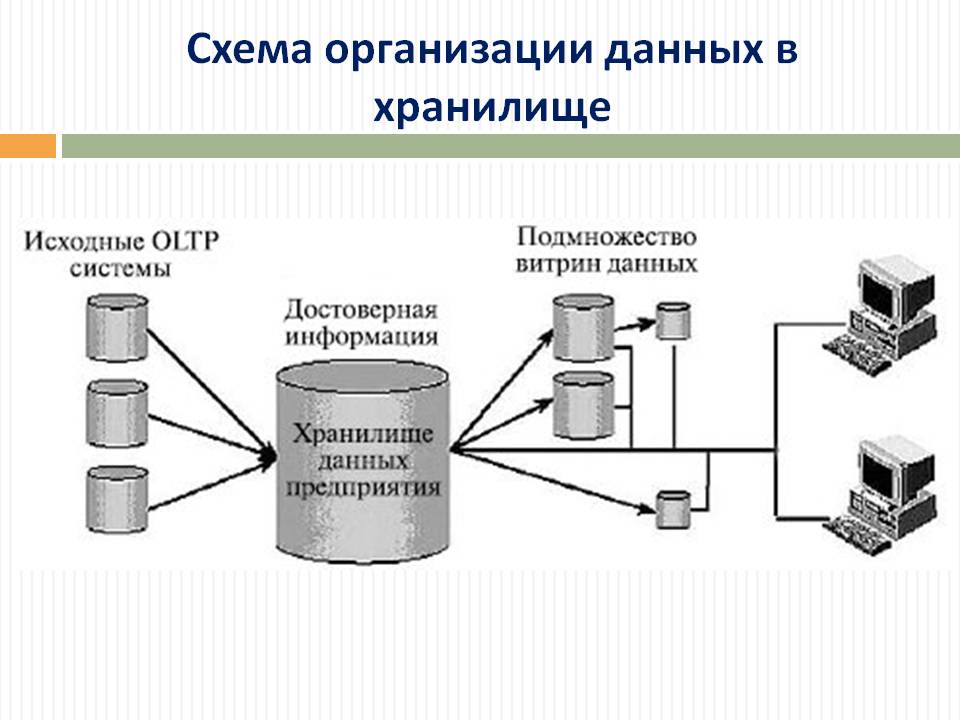
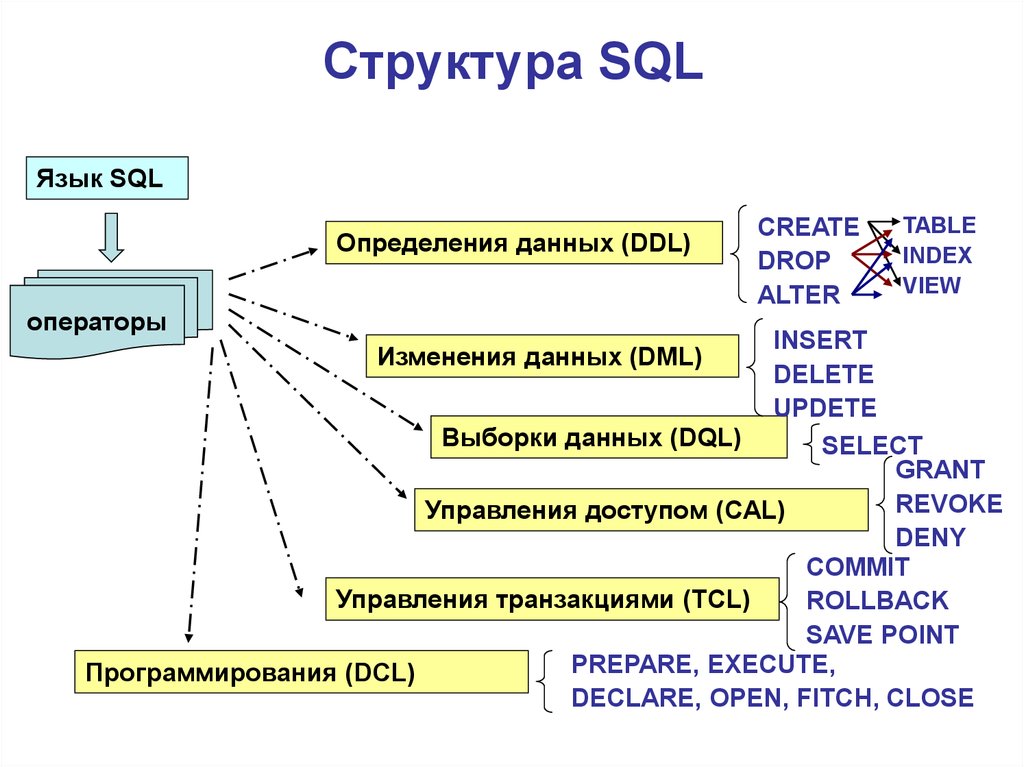
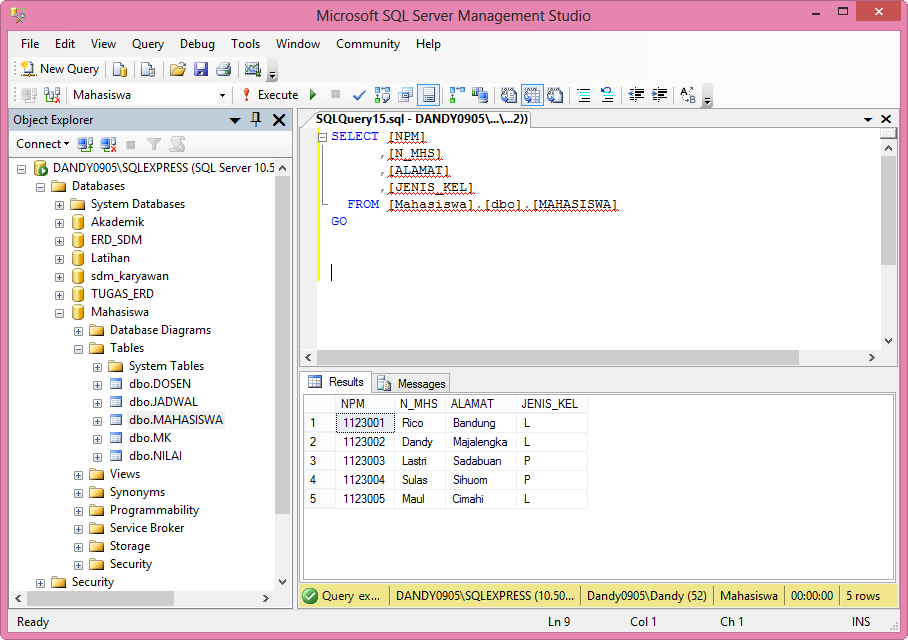
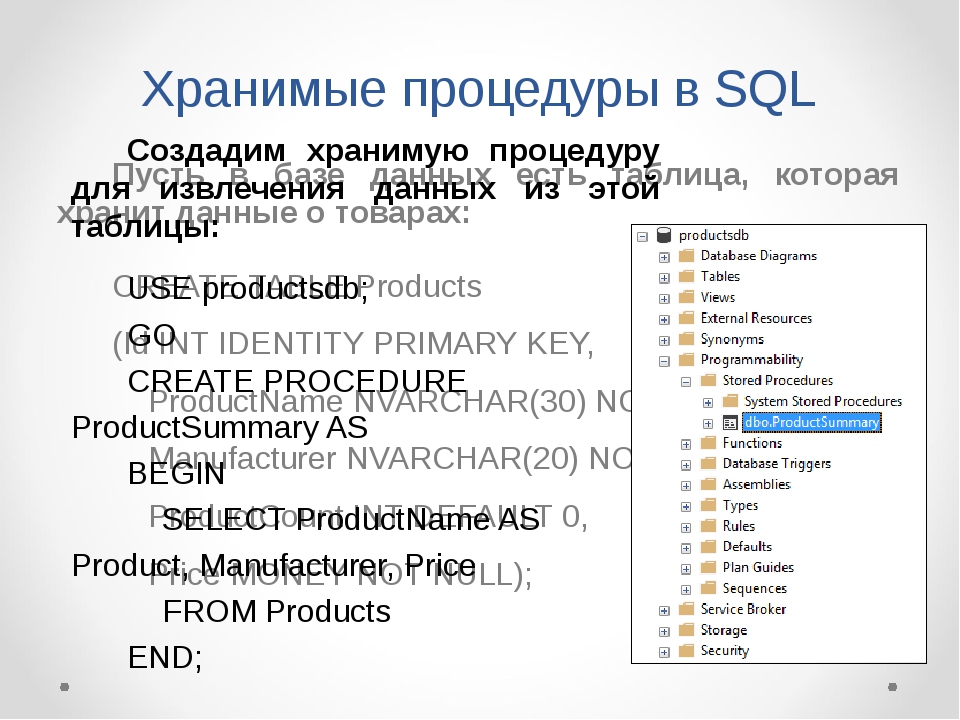

В моем случае DWH работает на базе MS SQL Server и содержит следующие таблицы:
- sessions — данные из Google Analytics загруженные посредством коннектора к Reporting API v4;
- costs — данные по расходам, предварительно загруженные в Google Analytics;
- orders — данные по заказам и доходу из внутренней CRM-системы.
Для работы нам потребуется установить:
- SQL Server Management Studio — для подключения к DWH;
- Power BI Desktop — для создания отчета.
Опущу совсем уж базовые вещи, такие как регистрация аккаунтов и установка программ, с этим вы без проблем справитесь и сами.
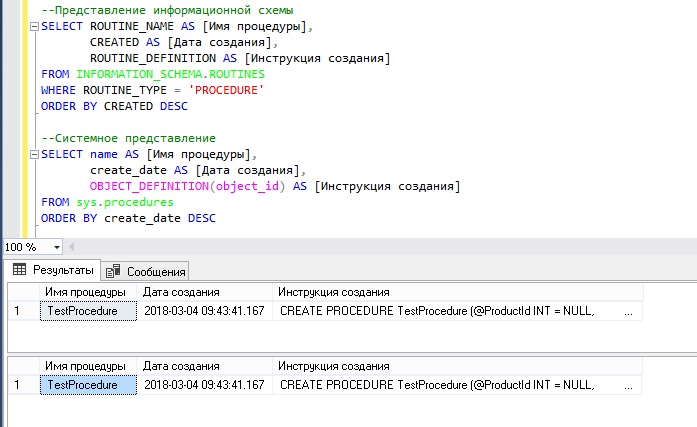
Пример 1. Получаем список всех хранимых процедур в MS SQL Server
Допустим, у Вас возникала необходимость получить список всех процедур с датой, когда они были созданы и текстом исходной SQL инструкции. Для этого мы можем написать следующий запрос.
SELECT ROUTINE_NAME AS ,
CREATED AS ,
ROUTINE_DEFINITION AS
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_TYPE = 'PROCEDURE'
ORDER BY CREATED DESC
В данном случае мы обратились к представлению ROUTINES информационной схемы. В качестве альтернативы можно использовать и системное представление sys.procedures, но только в этом случае для определения исходной SQL инструкции создания процедуры, нам нужно будет использовать функцию OBJECT_DEFINITION, так как в этом представлении такой информации нет.
SELECT name AS ,
create_date AS ,
OBJECT_DEFINITION(object_id) AS
FROM sys.procedures
ORDER BY create_date DESC
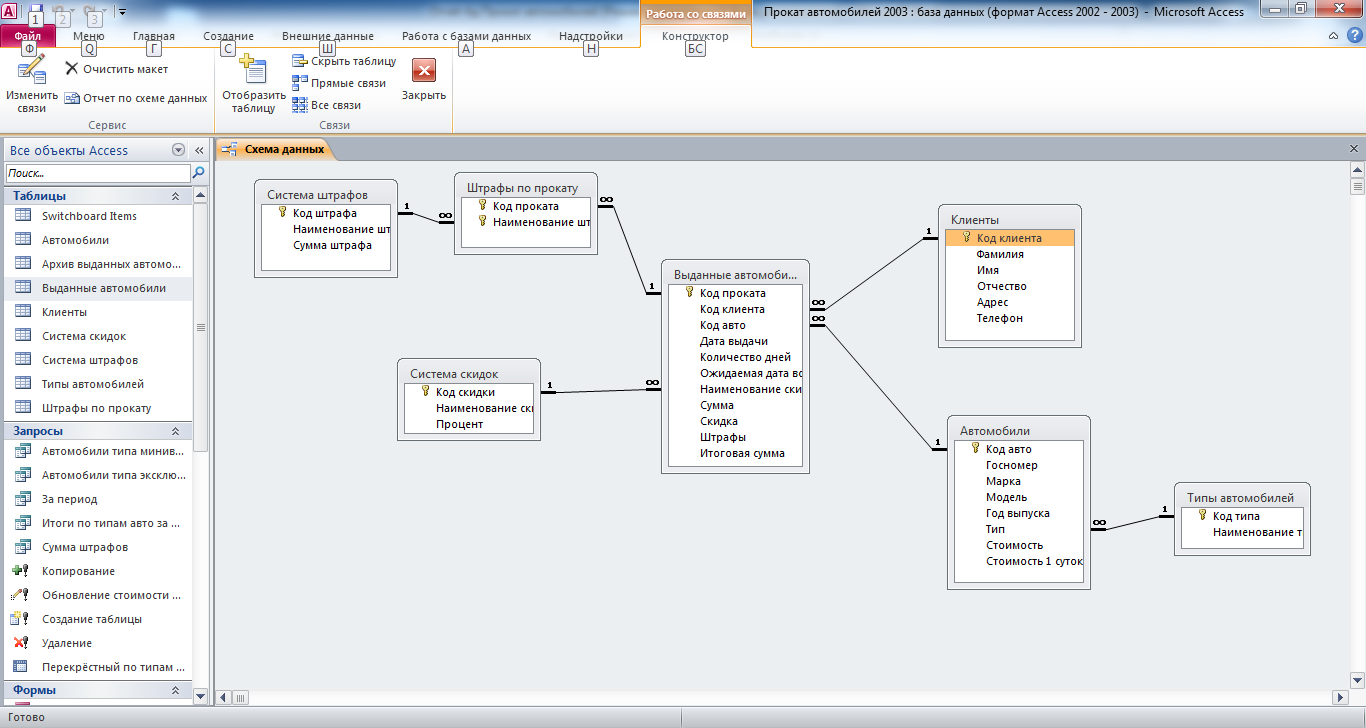
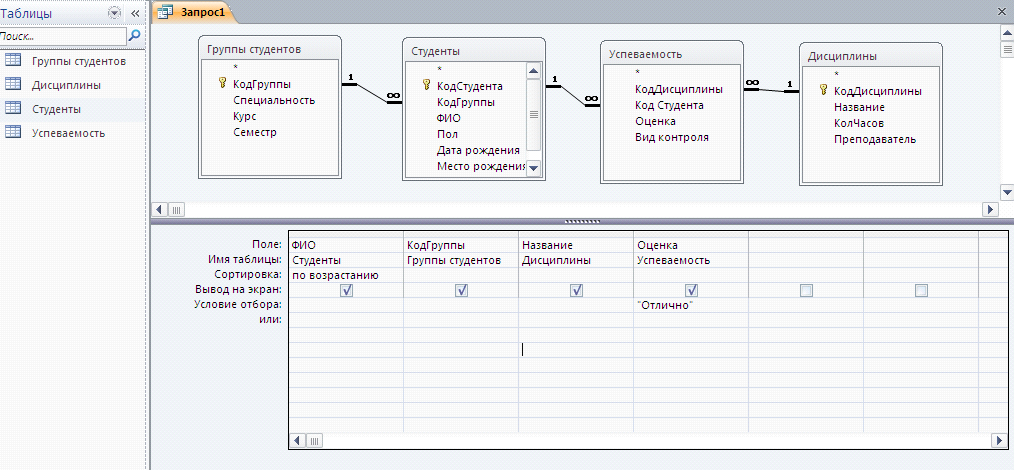
Просмотр связей таблиц в среде SQL Server Management Studio
в среде SQL Server Management Studio установлены отношения между таблицами.
есть ли способ отобразить вид всех таблиц со смежными линиями, как в Microsoft Access? Нужно ли мне открывать новый запрос и запускать что-то или есть кнопка, которую я пропустил?
4 ответов
Если вы используете Management Studio 2008:
разверните корневую базу данных, попробуйте развернуть папку диаграммы базы данных, он должен сказать что-то вроде «нет диаграмм».
Если он просит вас создать диаграмму сказать Да, а затем добавить таблицы и вуаля!
Если нет, прямо в папке диаграмм базы данных и создать новую диаграмму.
ApexSQL Search-это бесплатная среда SQL Server Management Studio и надстройка Visual Studio, которая, помимо прочего, имеет функцию просмотра зависимостей. Функция просмотр зависимостей имеет возможность визуализировать отношения всех объектов базы данных SQL, в том числе между зашифрованными и системными объектами, определенными объектами SQL server 2012 и объектами, хранящимися в базах данных, зашифрованных с помощью прозрачного шифрования данных (TDE)
Просмотр зависимостей функция также позволяет настроить и настроить макет диаграммы визуальных зависимостей, в том числе отношения, которые будут представлены, макет и размер созданной диаграммы, а также глубина детализации зависимостей
Если вы хотите отобразить зависимости для конкретной таблицы, просто выберите таблицу и щелкните правой кнопкой мыши просмотр зависимостей. проверьте, как просмотреть зависимости.
среда SQL Server 2005 позволяет отображать зависимости такой
SQL Server 2008 имеет sys.sql_expression_dependencies следовать этой ссылке
Я читаю этот вопрос в 2015 году, и я использую SQL Server 2012. В этом сценарии для просмотра зависимостей таблицы можно выполнить следующие действия: 1. В корневой папке базы данных находится папка диаграммы базы данных. Разверните эту базу данных и нажмите » Да » во всплывающем окне, которое появится; 3. Щелкните правой кнопкой мыши поле, которое вы подозреваете, что у него есть зависимость, обычно у них есть идентификатор букв в их именах, например, я нахожусь в EPM базы данных и в таблице MSP_Projects у нас есть поле Proj_UID, щелкните правой кнопкой мыши поле; 4. В появившемся контекстном меню выберите пункт связи. В левой части окна вы увидите внешние ключи, связанные с этим первичным ключом, а в правой части окна вы увидите свойства существующего отношения.
Проект «Сиэтл»
На встрече со Славой на следующий день я быстро узнал, что за несколько часов мы приступили к одному из самых амбициозных усовершенствований SQL Server, которые я когда-либо наблюдал за всю свою карьеру. Я говорю это, уже зная, что мы выводим на рынок SQL Server под Linux, что ранее считалось невозможным.
Слава и команда проекта выбрали для проекта кодовое название «Сиэтл», потому что в качестве кодового названия SQL Server 2017 использовалось «Хельсинки», и команда и искала новое наименование города для кодового названия проекта. По иронии судьбы, никто в Microsoft раньше не использовал название «Сиэтл», поэтому оно быстро прижилось. Я спросил Славу, когда он впервые начал планировать проект «Сиэтл». Я был поражен, услышав ответ: в январе 2017 года. Тот факт, что такие люди, как Слава, Конор Каннингем (Conor Cunningham) и Трэвис Райт (Travis Wright), планировали проект «Сиэтл», работая над завершением SQL Server 2017 на Linux, стал свидетельством их преданности команде, их стремления удерживать SQL Server на позиции лидера инноваций в отрасли баз данных.
Трудно было поверить, что мы могли так быстро запланировать нечто большее, после того как предоставили так много полезных и инновационных функций в SQL Server 2016 и SQL Server 2017.
В SQL Server 2016 мы добавили новые возможности диагностики производительности с помощью Query Store, а именно новые функции для разработчиков, такие как временные таблицы и интеграция c JSON. Мы повысили безопасность работы благодаря технологии Always Encrypted, динамическому маскированию данных и защите на уровне строк. И мы представили две новые инновационные возможности, выходящие за пределы «обычных» функций для реляционной системы управления базами данных. Одной из них была интеграция языка R для моделей машинного обучения. Второй была интеграция с системами Hadoop при помощи Polybase (что в итоге приведет к чему-то большему в 2019 году; однако я забегаю вперед). Создание возможностей для включения новых сценариев, таких как машинное обучение и большие данные, привело меня и других сотрудников Microsoft к мысли о том, что SQL Server — уже не просто механизм управления реляционными базами данных, а платформа данных.
Однако, чтобы создать современную и полнофункциональную платформу данных, нам нужно было расширять возможности приложений в системах, отличных от Windows Server. Это привело к появлению в SQL Server 2017 поддержки Linux и Docker-контейнеров. Запуск на Linux и использование контейнеров стали очень большим шагом вперед для Microsoft, но SQL Server 2017 также включал другие возможности, такие как адаптивная обработка запросов (Adaptive Query Processing), автоматическая настройка, графовая база данных, группы доступности вне кластеров и интеграция с Python, в дополнение к поддержке языка R для служб машинного обучения.
Учитывая все эти новые возможности, как мы можем за короткий период времени спланировать и создать что-то более новое, замечательное и интересное, чем SQL Server 2016 и 2017? Я задал себе этот вопрос, внимательно слушая коллег во время моей первой встречи с командой проекта «Сиэтл». В первые несколько минут меня познакомят с идеей, которая, когда ее позже объявят общественности, будет считаться довольно радикальной. И это новшество было «краеугольным камнем» проекта «Сиэтл», который имеет собственный код проекта: Aris.