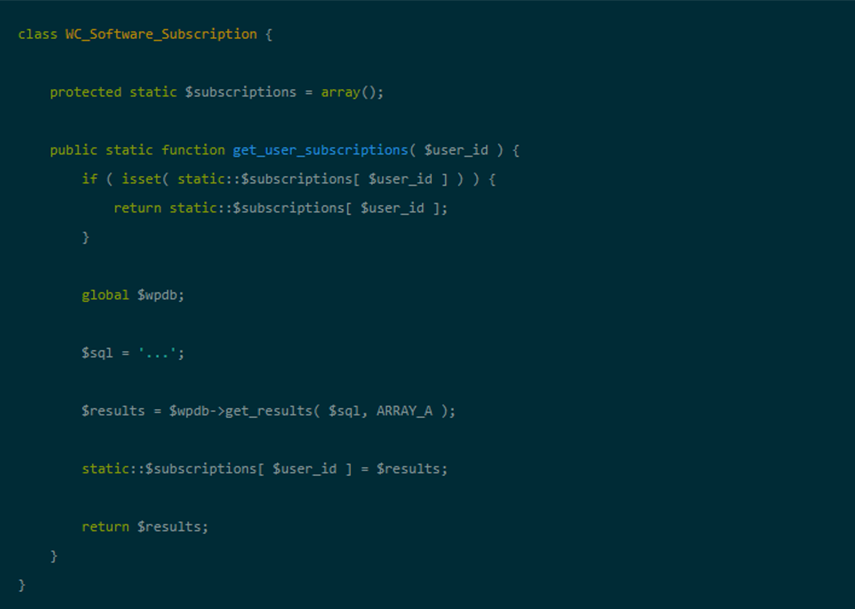
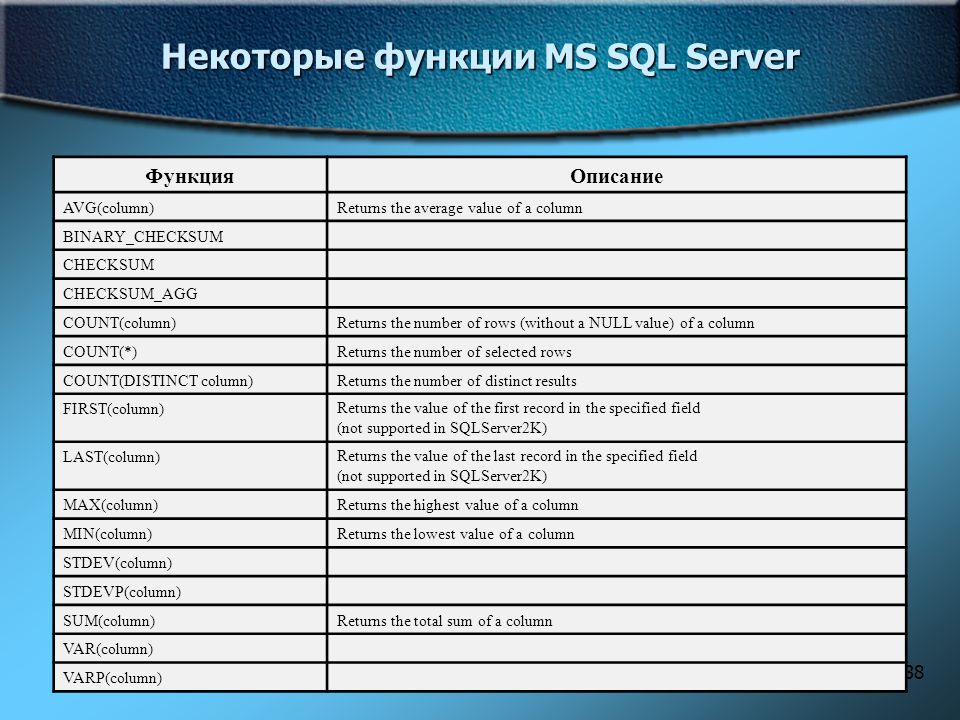
Oracle строковых функций
| Функции | Описание |
|---|---|
| ASCII | Возвращает код числа, представляющий указанный символ |
| ASCIISTR | Преобразует строку в любой набор символов в строку ASCII с помощью набора символов базы данных |
| CHR | Возвращает символ, основанный на коде номера |
| COMPOSE | Возвращает строку Юникода |
| CONCAT | Позволяет объединять две строки |
| Concat with || | Позволяет объединять две или более строк |
| CONVERT | Преобразует строку из одного набора символов в другой |
| DECOMPOSE | Принимает строку и возвращает строку Юникода |
| DUMP | Возвращает значение VARCHAR2, включающее код типа данных, длину в байтах и внутреннее представление выражения |
| INITCAP | Устанавливает первый символ в каждом слове в верхний регистр, а остальное — в нижний регистр |
| INSTR | Возвращает расположение подстроки в строке |
| INSTR2 | Возвращает расположение подстроки в строке с использованием UCS2 кодовых точек |
| INSTR4 | Возвращает расположение подстроки в строке с использованием укс4 кодовых точек |
| INSTRB | Возвращает расположение подстроки в строке, используя байты вместо символов |
| INSTRC | Возвращает расположение подстроки в строке с использованием полных символов Юникода |
| LENGTH | Возвращает длину указанной строки |
| LENGTH2 | Возвращает длину указанной строки с использованием UCS2 кодовых точек |
| LENGTH4 | Возвращает длину указанной строки с использованием укс4 кодовых точек |
| LENGTHB | Возвращает длину указанной строки, используя байты вместо символов |
| LENGTHC | Возвращает длину указанной строки, используя Unicode полные символы |
| LOWER | Преобразует все буквы в указанной строке в нижний регистр |
| LPAD | Прокладка левой стороны строки с определенным набором символов |
| LTRIM | Удаляет все указанные символы с левой стороны строки |
| NCHR | Возвращает символ, основанный на номере кода в наборе национальных символов |
| REGEXP_INSTR | Возвращает расположение шаблона регулярного выражения в строке |
| REGEXP_REPLACE | Позволяет заменить последовательность символов в строке другим набором символов с помощью сопоставления шаблона регулярного выражения |
| REGEXP_SUBSTR | Позволяет извлечь подстроку из строки с помощью сопоставления шаблона регулярного выражения |
| REPLACE | Заменяет последовательность символов в строке другим набором символов |
| RPAD | Прокладка правой стороны строки с определенным набором символов |
| RTRIM | Удаляет все указанные символы с правой стороны строки |
| SOUNDEX | Возвращает фонетическое представление (как это звучит) строки |
| SUBSTR | Позволяет извлечь подстроку из строки |
| TRANSLATE | Заменяет последовательность символов в строке другим набором символов |
| TRIM | Удаляет все указанные символы из начала или конца строки |
| UPPER | Преобразует все буквы в указанной строке в верхний регистр |
| VSIZE | Возвращает число байтов во внутреннем представлении выражения |
Функции SQL для обработки чисел
Функции обработки чисел предназначены для выполнения математических операций над числовыми данными. Эти функции предназначены для алгебраических и геометрических вычислений, поэтому они используются значительно реже функций обработки даты и времени. Однако числовые функции наиболее стандартизированными для всех версий SQL. Давайте взглянем на перечень числовых функций:
Мы привели лишь несколько основных функций, однако вы всегда можете обратиться к документации вашей СУБД, чтобы увидеть полный перечень функций, которые поддерживаются с их подробным описанием.
Например, напишем запрос для получения корня квадратного для чисел в столбце Amount
с помощью функции SQR()
:
SELECT
Amount, SQR(Amount) AS
Amount_SQR FROM
Sumproduct
DB2
Платформа DB2 не поддерживает функцию CONVERT, а поддержка функции TRANSLATE не соответствует стандарту ANSI. Функция TRANSLATE используется для преобразования подстрок и, как исторически сложилось, является синонимом функции UPPER, поскольку функция UPPER только недавно была добавлена в DB2. Если функция TRANSLATE используется в DB2 с единственным аргументом в виде символьного выражения, то результатом будет та же строка, преобразованная в верхний регистр. Если функция используется с несколькими аргументами, например TRANSLATE(ucmo4HUK, замена, совпадение), то функция преобразует все символы в источнике, которые также есть в параметре совпадение. Каждый символ в источнике, который находится в том же положении, что в параметре совпадение, будет заменен символом из параметра замена. Ниже приводится пример.
TRANSLATE(«Hello, World! «) «HELLO; WORLD!»
TRANSLATE(«Hello, World1», «wZ», «1W») «Hewwo, Zorwd1
Как обрезать строку в sql
The SUBSTR functions return a portion of char , beginning at character position , substring_length characters long. SUBSTR calculates lengths using characters as defined by the input character set. SUBSTRB uses bytes instead of characters. SUBSTRC uses Unicode complete characters. SUBSTR2 uses UCS2 code points. SUBSTR4 uses UCS4 code points.
If position is 0, then it is treated as 1.
If position is positive, then Oracle Database counts from the beginning of char to find the first character.
If position is negative, then Oracle counts backward from the end of char .
If substring_length is omitted, then Oracle returns all characters to the end of char . If substring_length is less than 1, then Oracle returns null.
char can be any of the data types CHAR , VARCHAR2 , NCHAR , NVARCHAR2 , CLOB , or NCLOB . The exceptions are SUBSTRC , SUBSTR2 , and SUBSTR4 , which do not allow char to be a CLOB or NCLOB . Both position and substring_length must be of data type NUMBER , or any data type that can be implicitly converted to NUMBER , and must resolve to an integer. The return value is the same data type as char , except that for a CHAR argument a VARCHAR2 value is returned, and for an NCHAR argument an NVARCHAR2 value is returned. Floating-point numbers passed as arguments to SUBSTR are automatically converted to integers.
Oracle Database Globalization Support Guide for more information about SUBSTR functions and length semantics in different locales
Appendix C in Oracle Database Globalization Support Guide for the collation derivation rules, which define the collation assigned to the character return value of SUBSTR
Функция LTRIM
Далее идет тоже в некоторых случаях полезная функция, LTRIM
– эта функция удаляет крайние левые символы, которые Вы укажите. Например, у Вас в базе есть колонка «город», в которой город указан в виде «г.Москва», а также есть города которые указанны в виде просто «Москва». Но Вам нужно вывести отчет только в виде «Москва» без «г.», но как это сделать, если есть и такие и такие? Вы просто указываете своего рода шаблон «г.» и если крайние левые символы начинаются с «г.», то эти символы просто не будут выводиться.
SELECT LTRIM (city, «г.») AS gorod FROM table
Данная функция просматривает символы слева, если символов по шаблону нет в начале строки, то она возвращает исходное значение ячейки, а если есть, то удаляет их.
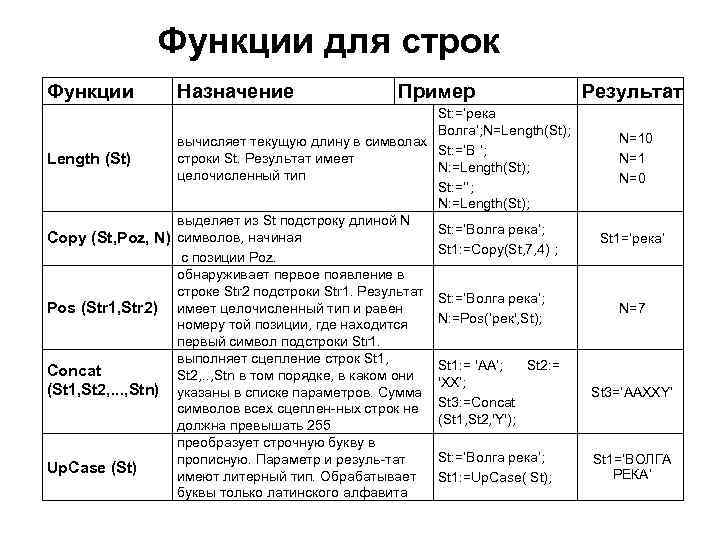
Строковые функции
| Функция | Описание |
|
ASCII |
Возвращает числовой код, который представляет конкретный символ |
|
CHAR_LENGTH |
Возвращает длину указанной строки (в символах) |
|
CHARACTER_LENGTH |
Возвращает длину указанной строки (в символах) |
|
CONCAT |
Объединяет два или более выражения вместе |
|
CONCAT_WS |
Объединяет два или более выражения вместе и добавляет разделитель между ними |
|
FIELD |
Возвращает позицию значения в списке значений |
|
FIND_IN_SET |
Возвращает позицию строки в списке строк |
|
FORMAT |
Форматирует число как формат «#, ###. ##», округляя его до определенного количества знаков после запятой |
|
INSERT |
Вставляет подстроку в строку в указанной позиции для определенного количества символов |
|
INSTR |
Возвращает позицию первого вхождения строки в другую строку |
|
LCASE |
Преобразует строку в нижний регистр |
|
LEFT |
Извлекает подстроку из строки (начиная слева) |
|
LENGTH |
Возвращает длину указанной строки (в байтах) |
|
LOCATE |
Возвращает позицию первого вхождения подстроки в строку |
|
LOWER |
Преобразует строку в нижний регистр |
|
LPAD |
Возвращает строку, которая добавлена в левую сторону с указанной строкой до определенной длины |
|
LTRIM |
Удаляет ведущие пробелы из строки |
|
MID |
Извлекает подстроку из строки (начиная с любой позиции) |
|
POSITION |
Возвращает позицию первого вхождения подстроки в строку |
|
REPEAT |
Повторяет строку определенное количество раз |
|
REPLACE |
Заменяет все вхождения указанной строки |
|
REVERSE |
Отменяет строку и возвращает результат |
|
RIGHT |
Извлекает подстроку из строки (начиная справа) |
|
RPAD |
Возвращает строку с правой строкой с определенной строкой до определенной длины |
|
RTRIM |
Удаляет конечные пробелы из строки |
|
SPACE |
Возвращает строку с заданным количеством пробелов |
|
STRCMP |
Проверяет, одинаковы ли две строки |
|
SUBSTR |
Извлекает подстроку из строки (начиная с любой позиции) |
|
SUBSTRING |
Извлекает подстроку из строки (начиная с любой позиции) |
|
SUBSTRING_INDEX |
Возвращает подстроку string и перед integer вхождений delimiter |
|
TRIM |
Удаляет начальные и конечные пробелы из строки |
|
UCASE |
Преобразует строку в верхний регистр |
|
UPPER |
Преобразует строку в верхний регистр |
PostgreSQL
Платформа PostgreSQL поддерживает инструкцию CONVERT стандарта ANSI, а преобразования здесь можно определять при помощи команды CREATE CONVERSION. Реализация функции TRANSLATE в PostgreSQL предоставляет расширенный набор функций, которые позволяют преобразовать любой текст в другой текст в пределах указанной строки.







TRANSLATE (символьная строка, из_текста, в_текст)
Вот несколько примеров:
SELECT TRANSLATE(«12345abcde», «5а», «XX»); «1234XXbcde»
SELECT TRANSLATE(title, «Computer», «PC»)
FROM titles
WHERE type=»Personal_computer»
SELECT CONVERT(«PostgreSQL» USING iso_8859_1_to_utf_8) «PostgreSQL»
Функции SUBSTR и INSTR в Oracle SQL
В посте рассматриваются однострочные функции SUBSTR и INSTR, работающие с символьными данными.
Символьные данные или строки являются универсальными, т.к. они позволяют хранить практически любой тип данных. Функции, которые работают с символьными данными, классифицируются на функции преобразования регистра символов и манипулирования символами.
Функции манипулирования символами используются для извлечения, преобразования и форматирования символьных строк. К этому классу относятся функции CONCAT, LENGTH, LPAD, RPAD, TRIM, REPLACE и рассматриваемые нижу функции SUBSTR и INSTR.
Функция SUBSTR принимает три параметра и возвращает строку, состоящую из количества символов, извлеченных из исходной строки, начиная с указанной начальной позиции:
SUBSTR (строка, начальная позиция, количество символов).
В приведенном примере извлекаются символы с первой по четвертую позиции из значений колонки last_name. Для сравнения выводятся исходные значения колонки last_name.

Функция INSTR возвращает число, представляющее позицию в исходной строке, начиная с заданной начальной позиции, где n-ное вхождение элемента поиска начинается:
INSTR (строка, элемент поиска, ,
Следующий запрос показывает позицию строчной буквы a для каждой строки колонки last_name. Если в строке встречаются два или более символов a, то будет отображена позиция первого/начального из них. Для сравнения и анализа выводятся исходные значения колонки.
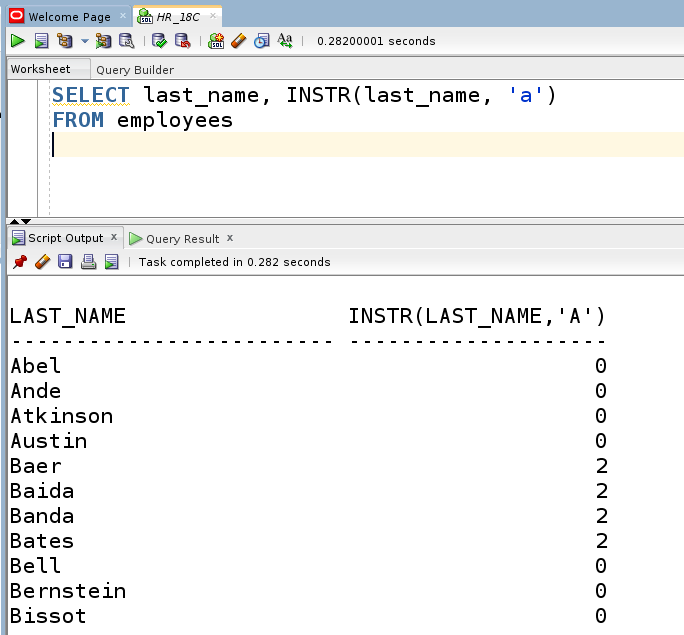
Если необходимо также отобразить позицию заглавной буквы А в фамилии, то надо предварительно перевести все символы фамилии в строчные, используя вложенную функцию LOWER. Запрос выглядит следующим образом:
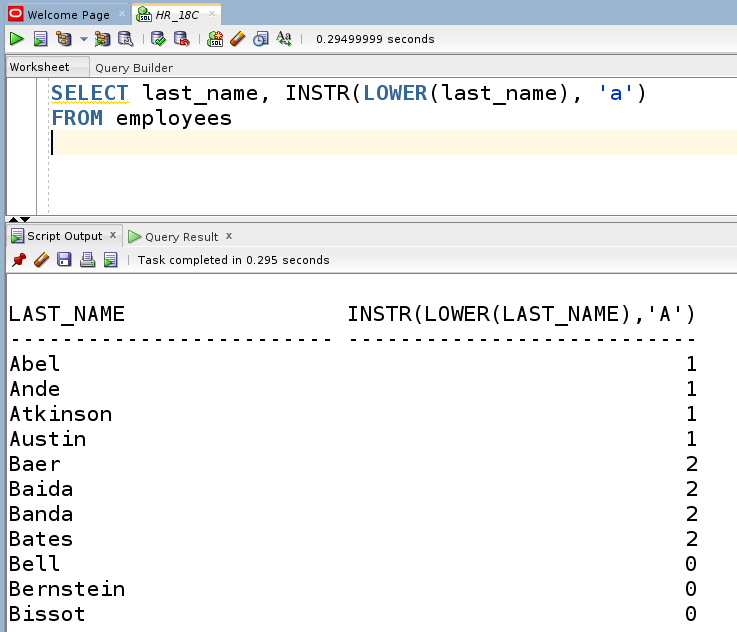
Как видно из результата, теперь позиция заглавной буквы A тоже определяется, например, для Abel, Ande, Atkinson, Austin возвращается значение 1.
В посте приведен пример совместного применения таких функций, как LENGTH, SUBSTR и INSTR.
SQL Server
Платформа SQL Server не поддерживает функцию TRANSLATE. Реализация функции CONVERT в SQL Server не соответствует стандарту SQL 2003. Эта функция в SQL Server эквивалентна функции CAST.
CONVERT (тип_данных, выражение, стиль])
Предложение стиль используется для определения формата преобразования даты. За дополнительной информацией обращайтесь к документации SQL Server. Ниже приводится пример.
SELECT
title,
CONVERT(char(7), ytd_sales)
FROM titles
ORDER BY title
GO
Последнее обновление: 29.07.2017
Для работы со строками в T-SQL можно применять следующие функции:
LEN
: возвращает количество символов в строке. В качестве параметра в функцию передается строка, для которой надо найти длину:
SELECT LEN(«Apple») — 5
LTRIM
: удаляет начальные пробелы из строки. В качестве параметра принимает строку:
SELECT LTRIM(» Apple»)
RTRIM
: удаляет конечные пробелы из строки. В качестве параметра принимает строку:
SELECT RTRIM(» Apple «)
CHARINDEX
: возвращает индекс, по которому находится первое вхождение подстроки в строке. В качестве
первого параметра передается подстрока, а в качестве второго — строка, в которой надо вести поиск:
SELECT CHARINDEX(«pl», «Apple») — 3
PATINDEX
: возвращает индекс, по которому находится первое вхождение определенного шаблона в строке:
SELECT PATINDEX(«%p_e%», «Apple») — 3
LEFT
: вырезает с начала строки определенное количество символов. Первый параметр функции — строка, а второй — количество символов, которые надо вырезать сначала строки:
SELECT LEFT(«Apple», 3) — App
RIGHT
: вырезает с конца строки определенное количество символов. Первый параметр функции — строка, а второй — количество символов, которые надо вырезать сначала строки:
SELECT RIGHT(«Apple», 3) — ple
SUBSTRING
: вырезает из строки подстроку определенной длиной, начиная с определенного индекса.
Певый параметр функции — строка, второй — начальный индекс для вырезки, и третий параметр — количество вырезаемых символов:
SELECT SUBSTRING(«Galaxy S8 Plus», 8, 2) — S8
REPLACE
: заменяет одну подстроку другой в рамках строки. Первый параметр функции — строка, второй — подстрока, которую надо заменить, а третий — подстрока, на которую надо заменить:
SELECT REPLACE(«Galaxy S8 Plus», «S8 Plus», «Note 8») — Galaxy Note 8
REVERSE
: переворачивает строку наоборот:
SELECT REVERSE(«123456789») — 987654321
CONCAT
: объединяет две строки в одну. В качестве параметра принимает от 2-х и более строк, которые надо соединить:
SELECT CONCAT(«Tom», » «, «Smith») — Tom Smith
LOWER
: переводит строку в нижний регистр:
SELECT LOWER(«Apple») — apple
UPPER
: переводит строку в верхний регистр
SELECT UPPER(«Apple») — APPLE
SPACE
: возвращает строку, которая содержит определенное количество пробелов
Например, возьмем таблицу:
CREATE TABLE Products
(Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL);
И при извлечении данных применим строковые функции:
SELECT UPPER(LEFT(Manufacturer,2)) AS Abbreviation,
CONCAT(ProductName, » — «, Manufacturer) AS FullProdName
FROM Products
ORDER BY Abbreviation
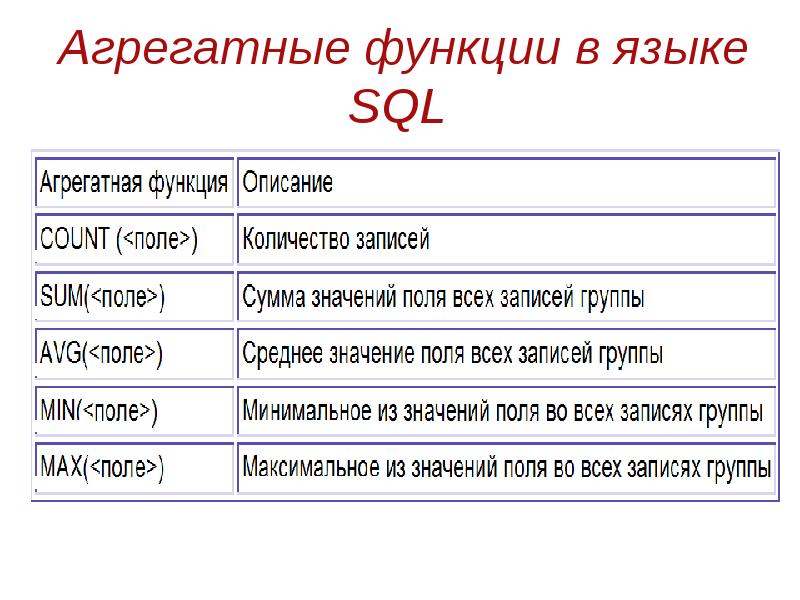
Статистические функции SQL
Статистические функции помогают нам получить готовые данные без их выборки. SQL-запросы с этими функциями часто используются для анализа и создания различных отчетов. Примером таких выборок может быть: определение количества строк в таблице, получение суммы значений по определенному полю, поиск наибольшего /наименьшего или среднего значения в указанном столбце таблицы. Также отметим, что статистические функции поддерживаются всеми СУБД без особых изменений в написании.
Список статистических функций в СУБД Access:
| Знак операции | Значение |
| COUNT() | Возвращает число строк в таблице или столбце |
| SUM() | Возвращает сумму значений в столбце |
| MIN() | Возвращает наименьшее значение в столбце |
| MAX() | Возвращает наибольшее значение в столбце |
| AVG() | Возвращает среднее значение в столбце |
Примеры использования функции COUNT():
SELECT COUNT(*) AS Count1 FROM Sumproduct — возвращает количество всех строк в таблице
SELECT COUNT(Product) AS Count2 FROM Sumproduct — возвращает количество всех непустых строк в поле Product
Мы намеренно удалили одно значение в столбце Product , чтобы показать разницу в работе двух запросов.
Примеры использования функции SUM():
SELECT SUM(Quantity) AS Sum1 FROM Sumproduct WHERE Month = ‘April’
Данным запросу мы отразили общее количество проданного товара в апреле.
SELECT SUM(Quantity*Amount) AS Sum2 FROM Sumproduct
Как видим, в статистических функциях мы можем осуществлять вычисления над несколькими столбцами с использованием стандартных математических операторов.
Пример использования функции MIN():
SELECT MIN(Amount) AS Min1 FROM Sumproduct
Пример использования функции MAX():
SELECT MAX(Amount) AS Max1 FROM Sumproduct
Пример использования функции AVG():
SELECT AVG(Amount) AS Avg1 FROM Sumproduct
Удаление пробелов из строки
Для удаления лишних пробелов из начала и конца строки в языке SQL есть три функции.
Функция LTRIM:
string
LTRIM
(str string
)
Удаляет с начала строки str пробелы и возвращает результат.
Функция RTRIM:
string
RTRIM
(str string
)
Также удаляет пробелы из строки str, только с конца. Обе функции поддерживают многобайтовые символы.







SELECT LTRIM (» текст «);
Результат: «текст »
SELECT RTRIM (» текст «);
Результат: » текст»
И третья функция TRIM позволяет сразу удалять пробелы из начала и из конца строки:
string
TRIM
([ string
FROM] str string
)
Параметр str обязательный, остальные параметры не обязательные. В случае если задан только один параметр str, то возвращает строку str удалив пробелы из начала и конца строки одновременно.
SELECT TRIM (» текст «);
Результат: «текст»
С помощью пара метра remstr можно задавать символы или подстроки, которые будут удаляться из начала и конца строки. С помощью управляющих параметров BOTH, LEADING, TRAILING можно задавать откуда будут удаляться символы:
- BOTH — удаляет подстроку remstr с начала и с конца строки;
- LEADING — удаляет remstr с начала строки;
- TRAILING — удаляет remstr с конца строки.
SELECT TRIM (BOTH «а» FROM «текст»);
Результат: «текст»
SELECT TRIM (LEADING «а» FROM «текстааа»);
Результат: «текстааа»
SELECT TRIM (TRAILING «а» FROM «ааатекст»);
Результат: «ааатекст»
Функция SPACE позволяет получить строку состоящую из определенного количества пробелов:
string
SPACE
(n integer
)
Возвращает строку, которая состоит из n пробелов.
Функция REPLACE нужна для замены заданных символов в строке
:
string REPLACE
(str string
, from_str string
, to_str string
)
Функция заменяет в строке str все подстроки from_str на to_str и возвращает результат. Поддерживает многобайтные символы.
SELECT REPLACE («замена подстроки», «подстроки», «текста»)
Результат: «замена текста»
Функция REPEAT:
string
REPEAT
(str string
, count integer
)
Функция возвращает строку, которая состоит из count повторений строки str. Поддерживает многобайтовые символы.
SELECT REPEAT («w», 3);
Результат: «www»
Функция REVERSE переворачивает строку:
string
REVERSE
(str string
)
Переставляет в строке str все символы с последнего на первый и возвращает результат. Поддерживает многобайтовые символы.
SELECT REVERSE («текст»);
Результат: «тскет»
Функция INSERT для вставки подстроки в строку:
string
INSERT
(str string
, pos integer
, len integer
, newstr string
)
Возвращает строку полученную в результате вставки в строку str подстроки newstr с позиции pos. Параметр len указывает сколько символов будет удалено из строки str, начиная с позиции pos. Поддерживает многобайтовые символы.
SELECT INSERT («text», 2, 5, «MySQL»);
Результат: «tMySQL»
«SELECT INSERT («text», 2, 0, «MySQL»);
Результат: «tMySQLext»
SELECT INSERT («вставка текста», 2, 7, «MySQL»);
Результат: «SELECT INSERT («вставка текста», 2, 7, «MySQL»);»
Если вдруг понадобиться заеменить в тексте все заглавные буквы на прописные, то можно воспользоваться одной из двух функций:
string
LCASE
(str string
) и string
LOWER
(str string
)
Обе функции заменяют в строке str заглавные буквы на прописные и возвращают результат. И та и другая поддерживают многобайтовые символы.
SELCET LOWER («АБВГДеЖЗиКЛ»);
Результат:»абвгдежзикл»
Если же наоборот необходимо прописные буквы заменить заглавными, то также можно применить одну из двух функцийй:
string
UCASE
(str string
) и string
UPPER (str string
)
Функции возвращают строку str, заменив все прописные символы на заглавные. Также поддерживают многобайтовые символы.
Пример:
SELECT UPPER («Абвгдежз»);
Результат: «АБВГДЕЖЗ»
Строковых функций в языке SQL немного больше, чем рассмотрено в данной статье. Но так как даже большинство рассмотренных здесь функций используются редко, я закончу их рассмотрение. В следующих статьях я постараюсь рассмотреть реальные практические примеры использования строковых функций SQL. Поэтому не забудьте подписаться на обновления блога . До новых встреч!
Основные строковые функции и операторы предоставляют разнообразные возможности и возвращают в качестве результата строковое значение. Некоторые строковые функции являются двухэлементными, что означает, что они могут работать одновременно с двумя строками. Стандарт SQL 2003 поддерживает строковые функции.
Функция NCHAR
NCHAR (<целое>)
возвращает символ по его юникоду. Несколько примеров.
| SELECT ASCII(‘а’), UNICODE(‘а’) |
возвращает код ASCII и юникод русской буквы «а»: 224 и 1072.
| SELECT CHAR(ASCII(‘а’)), CHAR(UNICODE(‘а’)) |
Пытаемся восстановить символ по его коду. Получаем «а» и NULL. NULL-значение возвращается потому, что кода 1072 нет в обычной кодовой таблице.
| SELECT CHAR(ASCII(‘а’)), NCHAR(UNICODE(‘а’)) |
Теперь все нормально, в обоих случаях «а». Наконец,
| SELECT NCHAR(ASCII(‘а’)) |
даст «a», т.к. юникод 224 соответствует именно этой букве.
Приведенные здесь примеры можно выполнить непосредственно на сайте, установив флажок «Без проверки» на странице с упражнениями на SELECT.
sqlite_offset(X)
Функция sqlite_offset(X) возвращает байтовое смещение в файле базы данных для начала записи, из которой будет считано значение. Если X не является столбцом в обычной таблице, то sqlite_offset (X) возвращает NULL. Значение, возвращаемое параметром sqlite_offset (X), может ссылаться на исходную таблицу или индекс в зависимости от запроса. Если значение X обычно извлекается из индекса, то функция sqlite_offset(X) возвращает смещение соответствующей записи индекса. Если значение X извлекается из исходной таблицы, то функция sqlite_offset(X) возвращает смещение записи таблицы.
Функция sqlite_offset(X) доступна если SQLite был откомпилирован с опцией -DSQLITE_ENABLE_OFFSET_SQL_FUNC.
extractTextFromHTML
Функция для извлечения текста из HTML или XHTML.
Она не соответствует всем HTML, XML или XHTML стандартам на 100%, но ее реализация достаточно точная и быстрая. Правила обработки следующие:
- Комментарии удаляются. Пример: . Комментарий должен оканчиваться символами . Вложенные комментарии недопустимы.
Примечание: конструкции наподобие и не являются допустимыми комментариями в HTML, но они будут удалены согласно другим правилам. - Содержимое CDATA вставляется дословно. Примечание: формат CDATA специфичен для XML/XHTML. Но он обрабатывается всегда по принципу «наилучшего возможного результата».
- Элементы и удаляются вместе со всем содержимым. Примечание: предполагается, что закрывающий тег не может появиться внутри содержимого. Например, в JS строковый литерал должен быть экранирован как .
Примечание: комментарии и CDATA возможны внутри или — тогда закрывающие теги не ищутся внутри CDATA. Пример: . Но они ищутся внутри комментариев. Иногда возникают сложные случаи:
Примечание: и могут быть названиями пространств имен XML — тогда они не обрабатываются как обычные элементы или . Пример: .
Примечание: пробелы возможны после имени закрывающего тега: , но не перед ним: . - Другие теги или элементы, подобные тегам, удаляются, а их внутреннее содержимое остается. Пример:
Примечание: ожидается, что такой HTML является недопустимым:
Примечание: функция также удаляет подобные тегам элементы: , , и т. д.
Примечание: если встречается тег без завершающего символа , то удаляется этот тег и весь следующий за ним текст: - Мнемоники HTML и XML не декодируются. Они должны быть обработаны отдельной функцией.
- Пробелы в тексте удаляются и добавляются по следующим правилам:
- Пробелы в начале и в конце извлеченного текста удаляются.
- Несколько пробелов подряд заменяются одним пробелом.
- Если текст разделен другими удаляемыми элементами и в этом месте нет пробела, он добавляется.
- Это может привести к появлению неестественного написания, например: , — в HTML нет пробелов, но функция вставляет их. Также следует учитывать такие варианты написания: , . Подобные результаты выполнения функции могут использоваться для анализа данных, например, для преобразования HTML-текста в набор используемых слов.
Также обратите внимание, что правильная обработка пробелов требует поддержки и свойств CSS и. Синтаксис
Синтаксис
Аргументы
x — текст для обработки. String.
Возвращаемое значение
Извлеченный текст.
Тип: String.
Пример
Первый пример содержит несколько тегов и комментарий. На этом примере также видно, как обрабатываются пробелы.
Второй пример показывает обработку и тега .
В третьем примере текст выделяется из полного HTML ответа, полученного с помощью функции url.
Запрос:
Результат:
Строковые функции SQL, описания
Функция CONCAT
Строковая функция CONCAT применяется для объединения значений двух полей в один.
Select CONCAT (value, subvalue) ЧТО_ВЫБРАТЬ FROM откуда_выбрать //объединяем столбцы value и survalue, в таблице откуда_выбрать.
Функция INITCAP
Строковая функция INITCAP возвращает значение в записи таблицы, где каждое слово начинается с заглавной, буквы, а продолжается строчными буквами.
Применяется для улучшения внешнего вида таблиц и исправления правил заполнения.
Select INITCAP (value) ЧТО_ВЫБРАТЬ FROM откуда_выбрать
Функция LOWER
Строковая функция LOWER, возвращает после запроса все слова с маленькой буквы.
Select LOWER (value) ЧТО_ВЫБРАТЬ FROM откуда_выбрать
Функция UPPER
Строковая функция UPPER, возвращает после запроса все слова с заглавной буквы.
Select UPPER (value) ЧТО_ВЫБРАТЬ FROM откуда_выбрать
Функция LPAD
Строковая функция LPAD предназначена, для дополнения значения символами слева. Используется, для увеличения длинны поля.
Select LPAD (value, 20, '-') as value FROM откуда_выбрать //увеличиваем длину поля до 20 знаков, добавляя к значению тире слева.
Функция RPAD
Строковая функция аналогична функции LPAD, только символы дополняются слева значения.
Select RPAD (value, 20, '-') as value FROM откуда_выбрать //увеличиваем длину поля до 20 знаков, добавляя к значению тире справа.
Функция LTRIM
Строковая функция LTRIM удаляет указанные символы слева значения.
Select LTRIM (city, 'г.') ЧТО_ВЫБРАТЬ FROM откуда_выбрать //удаляем г. Слева значения (город).
Функция REPLACE
Строковая функция REPLACE ищет совпадение символов в строке и возвращает после запроса строку с замененными совпадающими символами на указанные вами символы.
Select REPLACE (value, '/', '-' ) FROM откуда_выбрать //меняем символы слеш на тире.
Функция SUBSTR
Строковая функция SUBSTR возвращает только указанный диапазон символов.
Select SUBSTR (ident, '5', '9') FROM откуда_выбрать //выводим символы с 5 по 9.
Функция LENGTH
Строковая функция LENGTH считает количество символов в записи.
Select LENGTH (value) FROM откуда_выбрать
Это все строковые функции SQL, а теперь видеоурок.
SUBSTRING (Transact-SQL)
Возвращает часть символьного, двоичного, текстового или графического выражения в SQL Server.
Синтаксис
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.








Аргументы
expression Выражение типа character, binary, text, ntext или image.
start Целое число или выражение типа bigint, указывающее начальную позицию возвращаемых символов. (Нумерация начинается с 1, то есть первый символ в выражении имеет позицию 1.) Если аргумент start имеет значение меньше 1, то возвращаемое выражение начинается с первого символа, который указан в аргументе expression. В этом случае количество возвращаемых символов является наибольшим значением либо суммы start + length– 1, либо 0. Если значение start больше количества символов в выражении значения, возвращается выражение нулевой длины.
length Положительное целое число или выражение типа bigint, указывающее количество символов выражения expression, которое будет возвращено. Если значение length отрицательно, возникает ошибка и выполнение инструкции прерывается. Если сумма start и length больше количества символов в expression, то возвращается целочисленное выражение значения, начинающееся со значения start.
Типы возвращаемых данных
Возвращает символьные данные, если expression имеет один из поддерживаемых символьных типов данных. Возвращает двоичные данные, если аргумент expression имеет один из поддерживаемых двоичных типов данных. Возвращенная строка имеет тот же самый тип, как и заданное выражение. Исключения указаны в таблице.
| Заданное выражение | Возвращаемый тип |
|---|---|
| char/varchar/text | varchar |
| nchar/nvarchar/ntext | nvarchar |
| binary/varbinary/image | varbinary |
Remarks
Значения start и length должны быть указаны в виде количества символов для типов данных ntext, char или varchar и байтов для типов данных text, image, binary или varbinary.
Аргумент expression должен иметь тип varchar(max) или varbinary(max) , если аргумент start или length содержит значение, превышающее 2 147 483 647.
Дополнительные символы (суррогатные пары)
При использовании параметров сортировки дополнительных символов (SC) и start, и length обрабатывают каждую суррогатную пару в expression как один символ. Дополнительные сведения см. в статье Collation and Unicode Support.
Примеры
A. Использование SUBSTRING с символьной строкой
Следующий пример показывает, как получить часть символьной строки. Из таблицы sys.databases этот запрос возвращает имена системных баз данных в первом столбце, первую букву имени базы данных во втором столбце и третий и четвертый символы в последнем столбце.
| name | Initial | ThirdAndFourthCharacters |
|---|---|---|
| master | m | st |
| tempdb | t | mp |
| model | m | de |
| msdb | m | db |
Далее показано, как можно вывести второй, третий и четвертый символ строковой константы abcdef .
Б. Использование SUBSTRING с данными типа text, ntext или image
Для выполнения приведенных ниже примеров необходимо установить базу данных pubs.
В приведенном ниже примере показано, как вернуть первые 10 символов из каждого столбца данных text и image в таблице pub_info базы данных pubs . Данные text возвращаются как varchar, а данные image — как varbinary.
В приведенном ниже примере показано влияние функции SUBSTRING на данные типов text и ntext. Во-первых, пример создает новую таблицу в базе данных pubs под именем npub_info . Во-вторых, пример создает столбец pr_info в таблице npub_info из первых 80 символов столбца pub_info.pr_info и добавляет ü в качестве первого символа. Наконец, с помощью предложения INNER JOIN извлекаются все идентификационные номера издателей, а также обработанные функцией SUBSTRING значения столбцов типа text и ntext со сведениями об издателях.
Примеры: Azure Synapse Analytics и Система платформы аналитики (PDW)
В. Использование SUBSTRING с символьной строкой
Следующий пример показывает, как получить часть символьной строки. Из таблицы dbo.DimEmployee данный запрос возвращает фамилию в одном столбце и первую букву имени в другом.
В приведенном ниже примере показано, как получить второй, третий и четвертый символы строковой константы abcdef .