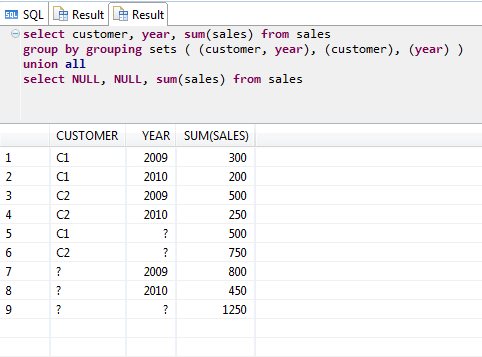
SQL Offset Groupby
Example 1: If this is not what you expected, you can add an aggregate function to your query to make the order by consistent (I used MIN here):
Example 2: I have two tables, events and eventdate, with a row event in eventdate matching the id column in events. (An event can therefore have numerous dates.)
but the following error is thrown:
ERROR: column «ed.start_date» must appear in the GROUP BY clause or
be used in an aggregate function
LINE 4: ORDER BY ed.»start_date» DESC
To be clear, I’m looking for a list of ids with a maximum of 5 entries and no duplicates (a duplicate would just be «removed»).
Given the following set:
| Id | Event | Start_date |
|---|---|---|
| 1 | 1 | |
| 2 | 2 | |
| 3 | 1 | 2 |
| 4 | 4 | 3 |
| 5 | 3 | 4 |
| 6 | 1 | 5 |
| 7 | 5 | 6 |
| 7 | 6 | 6 |
SQL Offset Orderby
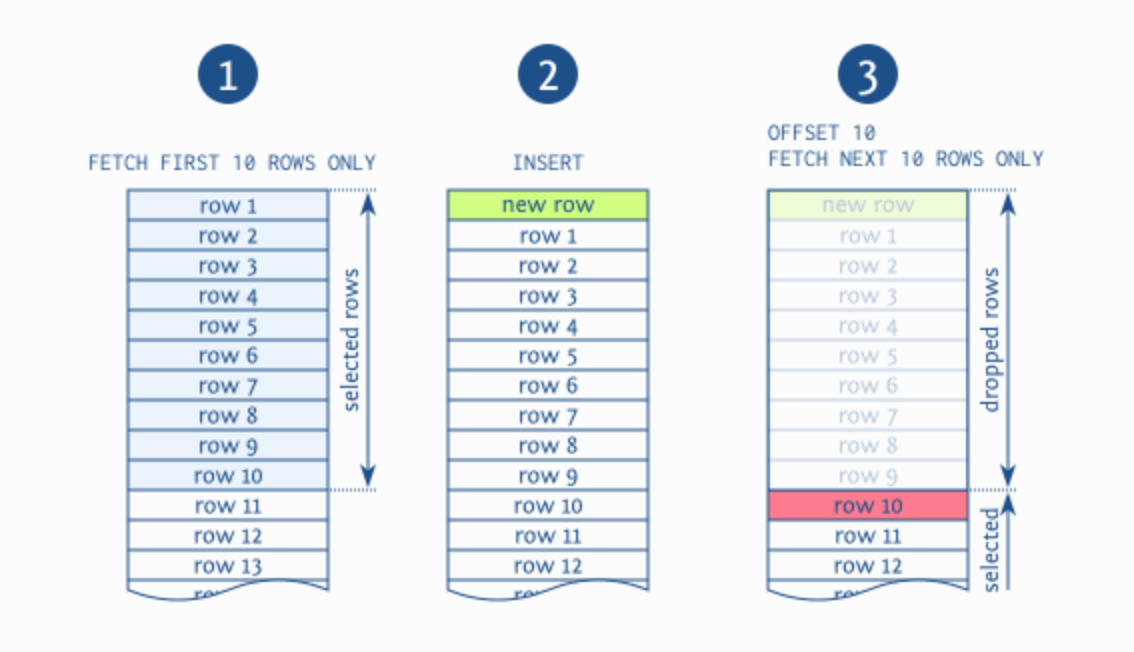
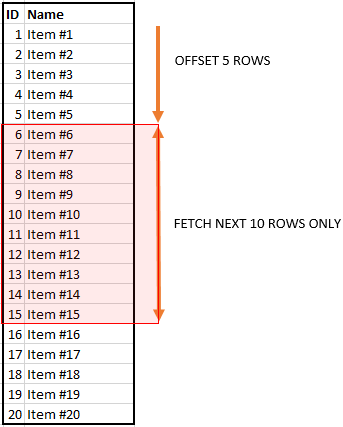
The OFFSET option is used to choose where to begin returning rows from a result. In a SELECT statement or UNION clause, OFFSET must come after the ORDER BY clause. It can not be used independently. The OFFSET specifies how many rows should be skipped before they are included in the result.
Alternatively, an undefined subset of the result set is returned.
When both LIMIT and OFFSET are specified in a SELECT statement or a UNION clause, Vertica evaluates the OFFSET statement first, then performs the LIMIT statement on the remaining data.
Any combination of Sequence BY, OFFSET, and FETCH FIRST clauses can be used in a query, but only in that sequence.
The OFFSET and FETCH FIRST clauses can only be used once per query and are not compatible with unions or view declarations. Except in a CREATE TABLE statement or an INSERT statement, they can’t be used in subselects.
The FETCH FIRST clause cannot be combined with the SELECT FIRST rowc_ount clause in the same SELECT statement.
Syntax :
Example 1: The general form for the OFFSET argument is:
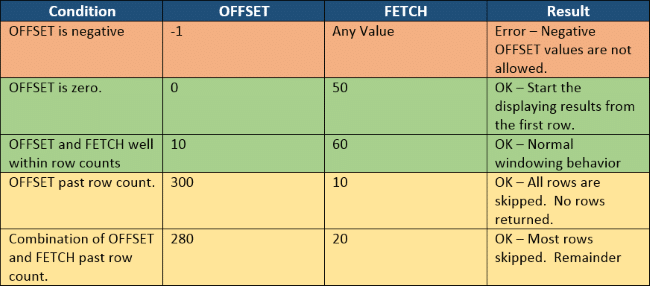
Values for OFFSET should be zero or higher. An error is produced by a negative number.
There are no rows displayed if OFFSET is higher than the number of rows in the ordered results.
Example 2: List all but 10 of the largest orders, sorted by amount:
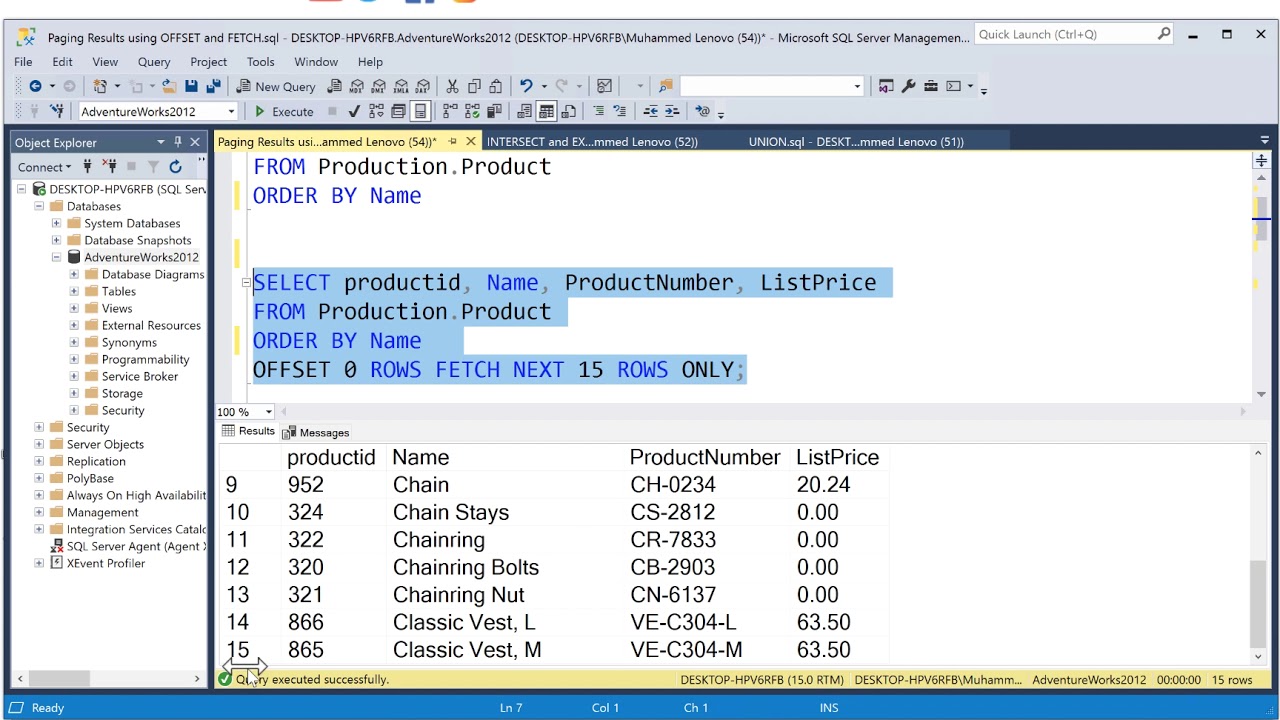
Example 3: The following query returns 14 rows from the customer_dimension table:
Output:
| Customer_name | Customer_gender |
|---|---|
| Amy X. Lang | Female |
| Anna H. Li | Male |
| Brian O. Weaver | Male |
| Craig O. Pavlov | Male |
| Doug Z. Goldberg | Male |
| Harold S. Jones | Male |
| Jack E. Perkins | Male |
| Joseph W. Overstreet | Male |
| Raja Y. Wilson | Male |
| Samantha O. Brown | Female |
| Steve H. Gauthier | Male |
| William . Nielson | Male |
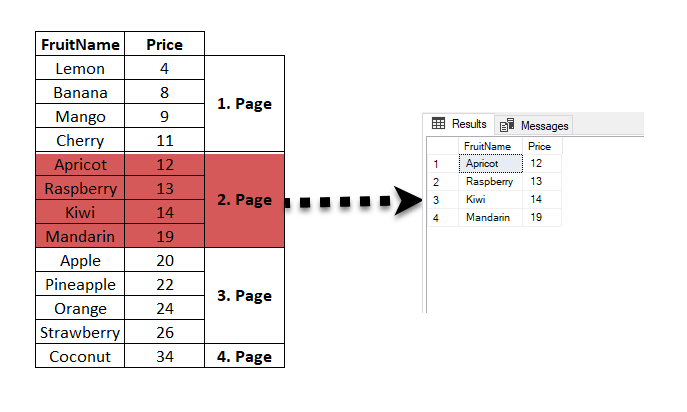
Example 4: For example, the following query returns rows starting from the 25th row of the result set:
Oracle FETCH clause syntax
The following illustrates the syntax of the row limiting clause:
clause
The clause specifies the number of rows to skip before the row limiting starts. The clause is optional. If you skip it, then offset is 0 and row limiting starts with the first row.
The offset must be a number or an expression that evaluates to a number. The offset is subjected to the following rules:
- If the offset is negative, then it is treated as 0.
- If the offset is NULL or greater than the number of rows returned by the query, then no row is returned.
- If the offset includes a fraction, then the fractional portion is truncated.
clause
The clause specifies the number of rows or percentage of rows to return.
For the semantic clarity purpose, you can use the keyword instead of , instead of . For example, the following clauses behavior the same:
The returns exactly the number of rows or percentage of rows after (or ).
The returns additional rows with the same sort key as the last row fetched. Note that if you use , you must specify an clause in the query. If you don’t, the query will not return the additional rows.
Описание табличных переменных MS SQL Server
Табличные переменные – это переменные с особым типом данных TABLE, которые используются для временного хранения результирующего набора данных в виде строк таблицы. Появились они еще в 2005 версии SQL сервера. Использовать такие переменные можно и в хранимых процедурах, и в функциях, и в триггерах, и в обычных SQL пакетах. Создаются табличные переменные так же, как и обычные переменные, путем их объявления инструкцией DECLARE.
Переменные такого типа предназначены в качестве альтернативы временным таблицам. Если говорить о том, что лучше использовать табличные переменные или временные таблицы, то однозначного ответа нет, у табличных переменных есть и плюсы, и минусы. Например, лично мне нравиться использовать табличные переменные, потому что их удобно создавать (т.е. объявлять) и не нужно думать об их удалении или очищение в конце инструкции, так как они автоматически очищаются (как и обычные переменные). Но при этом табличные переменные лучше использовать только тогда, когда Вы собираетесь хранить в них небольшой объём данных, в противном случае рекомендуется использовать временные таблицы.
Преимущества табличных переменных в Microsoft SQL Server
- Табличные переменные ведут себя как локальные переменные. Они имеют точно определенную область применения;
- Табличные переменные автоматически очищаются в конце инструкции, где они были определены;
- При использовании табличных переменных в хранимых процедурах повторные компиляции происходят реже, чем при использовании временных таблиц;
- Транзакции с использованием переменных TABLE продолжаются только во время процесса обновления соответствующей переменной. За счет этого табличные переменные реже подвергаются блокировке и требуют меньше ресурсов для ведения журналов регистрации.
Недостатки табличных переменных в MS SQL Server
- Запросы, которые изменяют переменные TABLE, не создают параллельных планов выполнения запроса;
- Переменные TABLE не имеют статистики распределения и не запускают повторных компиляций, поэтому рекомендуется использовать их для небольшого количества строк;
- Табличные переменные нельзя изменить после их создания;
- Табличные переменные нельзя создавать путем инструкции SELECT INTO;
- Переменные TABLE не изменяются в случае откатов транзакций, так как имеют ограниченную область действия и не являются частью постоянных баз данных.
Как в Oracle выбрать первые N записей
Если в таблице много записей, то порой достаточно выбрать первый десяток.
В других СУБД для этого изначально были специальные конструкции в языке SQL. В Oracle всё это появилось гораздо позже.
Есть несколько популярных способов. Каждый имеет плюсы и минусы, ну и от версии зависит.
Первый способ. С помощью конструкции «SELECT FROM SELECT»
Делаем два запроса: сначала сортируем, затем выбираем нужное количество.
Конструкции SELECT-FROM-SELECT в Oracle 7 не было и приходилось изгалятся ещё круче. Но эти коды уже канули в прошлое.
С виду похож на первый способ, но на самом деле более универсальный. Позволяет получить не только первую десятку, но и вторую, третью и т.д
Просто надо переписать последюю строку в как-то так: WHERE 0 Третий способ . «Новомодный». Работает в Oracle 12c.
Здесь всё за счёт конструкции FETCH FIRST ROWS. Oracle потребовалось дойти до 12-ой версии, чтобы эту конструкцию ввести в язык.
Если нужно перенести объекты схемы из одной базы в другую, то проще всего это сделать с помощью технологии Oracle Data Pump. Прежде чем вникать в детали работы с Data Pump, давайте уточним: у нас есть физические резервные копии и логические дампы.
Чтобы после сбоя в системе (например, отказа жесткого диска) восстановить базу нужно иметь под рукой резервную копию. (Нет резервной копии — прощай работа )) Чем свежее копия, тем лучше. Более того: резервная копия базы должна быть полной и непротиворечивой.
Долго не мог понять, почему люди не любят пользоваться SQL*Plus. Оказывается: интерфейс убогий и бестолковый. Словом, не графический – мышкой ткнуть не куда (значит интуитивно не понятный). Мда. ..редко встретишь кодера, умеющего мышкой воять SELECT’ы.
Источник статьи: http://oracle-teach.ru/post_1474450881.html
Использование временной таблицы
Заносим промежуточный результат (только ключевые поля) во временную таблицу с
пронумерованными строками, отсекая по верхней границе, затем выбираем из нее нужный
диапазон, соединяя с основной таблицей.
Не забудьте увеличить размер системной базы tempdb. Для данного примера она составила
1,5 Гбайта. В отсутствии верхнего предела для временных данных и заключается основной
недостаток метода: чем больше исходная таблица и чем дальше от начального значения
мы запрашиваем очередной пакет, тем больше потребуется заливать данных во временную
таблицу. Конечно, дисковое пространство нынче большое и дешевое, но все таки винчестер
не резиновый, да и скорость с ростом числа загружаемых во временную таблицу строк
будет падать.
DECLARE @offset int, @batch_size int;
SELECT @offset = 400001, @batch_size = 100000;
CREATE TABLE #orders(
row_num int identity(1, 1) NOT NULL,
product_code nvarchar(18) NOT NULL,
customer_code nvarchar(15) NOT NULL,
order_type nvarchar(4) NOT NULL,
qty_date datetime NOT NULL
);
INSERT INTO #orders (product_code, customer_code, order_type, qty_date)
SELECT TOP (@offset + @batch_size)
O.product_code, O.customer_code, O.order_type, O.qty_date
FROM orders O INNER JOIN customers C ON O.customer_code = C.customer_code
WHERE C.country_code = 'IT'
ORDER BY O.product_code ASC, O.customer_code ASC, O.order_type ASC, O.qty_date ASC;
SELECT O.*
FROM #orders T INNER JOIN orders O
ON T.product_code = O.product_code AND
T.customer_code = O.customer_code AND
T.order_type = O.order_type AND
T.qty_date = O.qty_date
WHERE T.row_num BETWEEN @offset and @offset + @batch_size - 1;
DROP TABLE #orders;
Ограничения
Нет ограничения на число столбцов в предложении ORDER BY, однако общий размер столбцов, перечисленных в нем, не может превышать 8060 байт.
Столбцы типа ntext, text, image, geography, geometry и xml не могут использоваться в предложении ORDER BY.
Нельзя указывать целое число или константу, если аргумент order_by_expression присутствует в ранжирующей функции. Дополнительные сведения см. в статье Предложение OVER (Transact-SQL).





Если в качестве имени таблицы в предложении FROM используется псевдоним, то только псевдоним может быть использован для обозначения столбца этой таблицы в предложении ORDER BY.
Имена и псевдонимы столбцов, указанные в предложении ORDER BY, должны быть определены в списке выбора, если инструкция SELECT содержит одно из следующих предложений или операторов:
-
UNION, оператор
-
Оператор EXCEPT
-
INTERSECT, оператор
-
SELECT DISTINCT
Кроме того, если в инструкцию входит оператор UNION, EXCEPT или INTERSECT, то имена и псевдонимы столбцов должны быть указаны в списке выбора первого (слева) запроса.
В запросе, содержащем оператор UNION, EXCEPT или INTERSECT, предложение ORDER BY допускается только в конце инструкции. Это ограничение применяется только при использовании операторов UNION, EXCEPT и INTERSECT в запросах верхнего уровня, но не во вложенных запросах. См подраздел «Примеры» ниже.
Предложение ORDER BY недопустимо в представлениях, встроенных функциях, производных таблицах и вложенных запросах, если также не указаны предложения TOP либо OFFSET и FETCH. В этих объектах предложение ORDER BY используется только для определения строк, возвращаемых предложением TOP или OFFSET и FETCH. Предложение ORDER BY не гарантирует упорядочивания результатов при запросе этих конструкций, если оно не указано в самом запросе.
Предложения OFFSET и FETCH не поддерживаются в индексированных представлениях и представлениях, определенных с предложением CHECK OPTION.
Предложения OFFSET и FETCH могут быть использованы в любом запросе, допускающем применение TOP и ORDER BY, со следующими ограничениями.
-
Предложение OVER не поддерживает OFFSET и FETCH.
-
Предложения OFFSET и FETCH не могут быть указаны прямо в инструкциях INSERT, UPDATE, MERGE и DELETE, но могут быть указаны во вложенных запросах, определяемых этими инструкциями. Например, в инструкции INSERT INTO SELECT предложения OFFSET и FETCH могут быть указаны в инструкции SELECT.
-
В запросе, содержащем оператор UNION, EXCEPT или INTERSECT, предложения OFFSET и FETCH могут быть указаны только в конечном запросе, который определяет порядок следования результатов запроса.
-
TOP нельзя сочетать с OFFSET и FETCH в одном выражении запроса (в той же области запроса).
SQL Server / Oracle SQL
SQL Introduction
SQL Syntax
SQL Select
SQL Insert
SQL Update
SQL Delete
SQL Joins
SQL Examples of Joins
SQL Explicit vs. Implicit Joins
SQL Group By Examples
SQL Having
SQL — IN
SQL — NULLs
Functional Dependencies
Normalization
ACID Properties
SQL SubQueries
SQL — Queries With Examples
SQL Views
Insert, Update, Delete Views
SQL Join Views
SQL Inline Views
SQL — Nth Highest Salary
SQL Second Highest Salary
SQL — Difference Truncate / Delete
SQL — Difference Truncate / Drop
SQL — Difference HAVING / WHERE
SQL — Difference CAST / CONVERT
SQL — Difference NOT IN / NOT EXIST
SQL — Difference IN / EXISTS
SQL — Difference UNION / UNION ALL
SQL — Difference Nested / Correlated Subquery
SQL — REPLACE
SQL — TOP
SQL — LIKE
SQL — SELECT INTO
SQL — CREATE TABLE
SQL — CREATE TABLE (More Examples)
SQL — ALTER TABLE
SQL — Difference views / Materialized views
SQL Count
SQL Update
SQL Clustered / Non-Clustered Indexes
SQL — Delete Duplicate Records
SQL — Difference Unique/Primary Key
SQL — GETDATE()
SQL — DATEDIFF()
SQL — DATEADD()
SQL — DATEPART()
SQL — Convert()
SQL — SUM()
SQL — AVG()
SQL — MIN()
SQL — MAX()
SQL — Insert Into Select
SQL — Insert Multiple Values In Table
SQL — Referential Integrity
SQL — Not Null Constraint
SQL — Unique Constraint
SQL — Primary Key Constraint
SQL — Foreign Key Constraint
SQL — Default Constraint
SQL — Check Constraint
SQL — ROLLUP
SQL — CUBE
SQL — STUFF()
SQL — Count_Big
SQL — Binary_Checksum
SQL — Checksum_AGG
SQL — Index Include
SQL — Covered Query
SQL — Identity
SQL — sp_columns
SQL — Diff Local/Global Temporary Tables
SQL — Stored Procedure
SQL — sp_who
SQL — Session
SQL — Dynamic SQL
SQL — SQL Server Execution Plan
SQL — sp_executesql
SQL — Difference Execute/Execute()
SQL — Case Expression
SQL — XML Variable Example
SQL — Pivot
SQL — Merge
Example of SQL Merge
SQL Server — Difference Rank, Dense_Rank & Row_Number
SQL Server — PATINDEX Examples
SQL Server — COLLATE Examples
SQL Server — Difference CHAR / VARCHAR
SQL Server — Interview Questions for Testers
SQL Interview Questions
Difference GRANT / DENY / REVOKE
Subqueries in WHERE clause — Examples
How to check indexes on a table?
DATENAME examples
SQL Join Interview Questions
Кейс. Модели атрибуции
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.
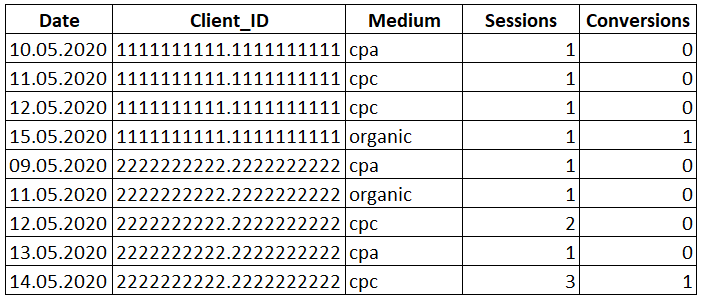
Первый клик
В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.
SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders
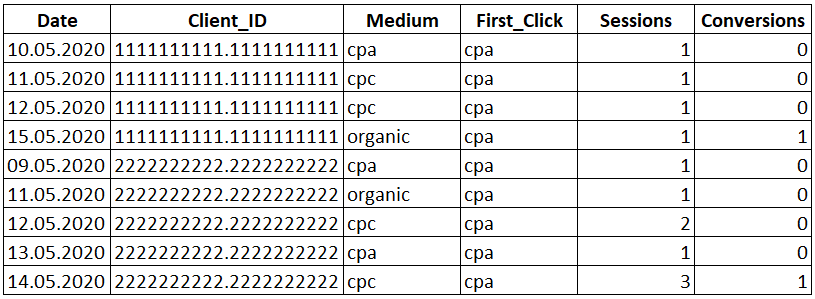
Рядом со столбцом «Medium» появился новый столбец «First_Click», в котором указан канал в первый раз приведший посетителя к нам на сайт и вся ценность зачтена данному каналу.
Произведем агрегацию и получим отчет.
WITH First AS ( SELECT Date , Client_ID , Medium , FIRST_VALUE(Medium) OVER(PARTITION BY Client_ID ORDER BY Date) AS 'First_Click' , Sessions , Conversions FROM Orders ) SELECT First_Click , SUM(Conversions) AS 'Conversions' FROM First GROUP BY First_Click
С учетом давности взаимодействий
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.
SELECT Date , Client_ID , Medium -- Присваиваем ранг в зависимости от близости к дате конверсии , DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks' , Sessions , Conversions FROM Orders
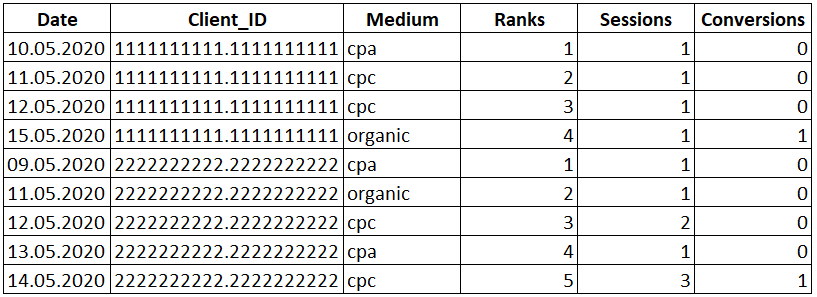
Рядом со столбцом «Medium» появился новый столбец «Ranks», в котором указан ранг каждой строки в зависимости от близости к дате конверсии.
Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.
SELECT
Date
, Client_ID
, Medium
-- Делим ранг определенной строки на сумму рангов по пользователю
, ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay'
, Sessions
, Conversions
FROM (
SELECT
Date
, Client_ID
, Medium
-- Присваиваем ранг в зависимости от близости к дате конверсии
, DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks'
, Sessions
, Conversions
FROM Orders
) rank_table
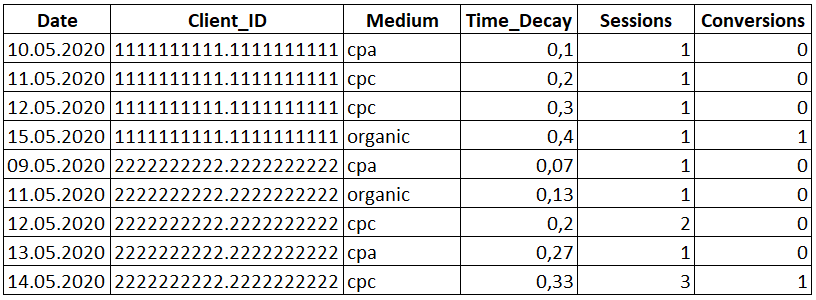
Рядом со столбцом «Medium» появился новый столбец «Time_Decay» с распределенной ценностью.
И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.
WITH Ranks AS (
SELECT
Date
, Client_ID
, Medium
-- Делим ранг определенной строки на сумму рангов по пользователю
, ROUND(CAST(DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS FLOAT) / CAST(SUM(ranks) OVER(PARTITION BY Client_ID) AS FLOAT), 2) AS 'Time_Decay'
, Sessions
, Conversions
FROM (
SELECT
Date
, Client_ID
, Medium
-- Присваиваем ранг в зависимости от близости к дате конверсии
, DENSE_RANK() OVER(PARTITION BY Client_ID ORDER BY Date) AS 'Ranks'
, Sessions
, Conversions
FROM Orders
) rank_table
)
SELECT
Medium
, SUM(Time_Decay) AS 'Value'
, SUM(Conversions) AS 'Conversions'
FROM Ranks
GROUP BY Medium
ORDER BY Value DESC
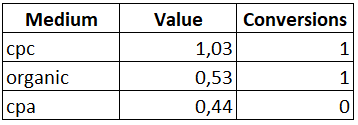
Из получившегося отчета видно, что самым весомым каналом является канал «cpc», а канал «cpa», который был бы исключен при применении стандартной модели атрибуции, тоже получил свою долю при распределении ценности.
Полезные ссылки:
- SELECT — предложение OVER (Transact-SQL)
- Как работать с оконными функциями в Google BigQuery — подробное руководство
- Модель атрибуции на основе онлайн/офлайн данных в Google BigQuery
Роман Романчук
Эксперт по аналитике данных, ex-директор по аналитике Сравни.ру.
Директор команды данных в Xsolla.
- Кейс: как построить отдел аналитики в большой компании? — 06.05.2022
- Учимся применять оконные функции — 29.09.2020
- Автоматизация отчетности при помощи SQL и Power BI — 05.04.2020
Пример — использование ключевого слова LIMIT
Рассмотрим, как использовать в SQLite оператор SELECT LIMIT.
Например:
PgSQL
SELECT employee_id,
last_name,
first_name
FROM employees
WHERE favorite_website = ‘Google.com’
ORDER BY employee_id DESC
LIMIT 5;
|
1 2 3 4 5 6 7 |
SELECTemployee_id, last_name, first_name FROMemployees WHEREfavorite_website=’Google.com’ ORDERBYemployee_idDESC LIMIT5; |
В этом SQLite примере SELECT LIMIT будут выбраны первые 5 записей из таблицы employees, где любимый веб-сайт — ‘Google.com’
Обратите внимание, что результаты сортируются по employee_id в порядке убывания, поэтому это означает, что 5 самых больших значений employee_id будут возвращены оператором SELECT LIMIT
Если в таблице employees есть другие записи со значением веб-сайта Google.com, они не будут возвращены оператором SELECT LIMIT в SQLite.





Если бы мы хотели выбрать 5 самых минимальных значений employee_id вместо самых больших, мы могли бы изменить порядок сортировки следующим образом:
PgSQL
SELECT employee_id,
last_name,
first_name
FROM employees
WHERE favorite_website = ‘Google.com’
ORDER BY employee_id ASC
LIMIT 5;
|
1 2 3 4 5 6 7 |
SELECTemployee_id, last_name, first_name FROMemployees WHEREfavorite_website=’Google.com’ ORDERBYemployee_idASC LIMIT5; |
Теперь результаты будут отсортированы по employee_id в порядке возрастания, поэтому первые 5 наименьших записей employee_id, которые имеют fav_website ‘Google.com’, будут возвращены этим оператором SELECT LIMIT. Никакие другие записи не будут возвращены этим запросом.
👌 Ответ:
Вы должны использовать вложенный запрос как:
=> В PL / SQL «ROWNUM = 1» НЕ равно «TOP 1» TSQL.
Таким образом, вы не можете использовать такой запрос: «выберите * из any_table_x, где rownum = 1 order by any_column_x;» Поскольку оракул получает первую строку, он применяет предложение order by.
- 1 Пожалуйста, добавьте пояснение к своему ответу
- Необычного синтаксиса следует избегать без уважительной причины. В этом случае было бы полезно указать либо тестовый пример, либо номер ошибки. Я смутно припоминаю некоторые странные проблемы с , но мы не должны больше позволять старым ошибкам влиять на наш код.
- 7 @hgwhittle, Причина, по которой Fuat прав, заключается в том, что ROWNUM не заботится о ‘ordery by’, он просто берет первую запись, которую может найти, и немедленно возвращает ее. Другими словами, квалификатор ROWNUM не учитывает команду «Упорядочить по». Я бы хотел, чтобы это было не так, но Фуат прав, если использовать вложенный запрос.
Насколько я знаю, Таблица в Oracle — это специальная таблица с одной строкой. Итак, этого было бы достаточно:
- это неправда, выберите пользователя из двойного, вы должны предоставить вам всех пользователей
- Как и в Википедии о двойственности в Oracle
- 1 .. и только что опробовал на моей системе, работает как ypercube и вся сопутствующая документация. @Бен
- 1 @Ben dual — это не просмотр каталога, он не отображает «всех пользователей». Для этой цели вы должны использовать представление типа ALL_USERS.
Здесь нет условие (это MySQL / PostgresSQL) в Oracle, вам необходимо указать .
«FirstRow» является ограничением и поэтому находится в пункт не в пункт. И это называется rownum
1 Обратите внимание, что это не будет работать должным образом в сочетании с , так как заказ происходит только после предложение where. Другими словами, для получения вершины определенного отсортированного запроса rownum совершенно бесполезен. @Nyerguds, это правда только наполовину
Вы можете использовать заказ до с запросом просмотра. 4 Что, так ? Что ж, это может сработать, но выглядит довольно глупо, черт возьми
@Nyerguds, это правда только наполовину. Вы можете использовать заказ до с запросом просмотра. 4 Что, так ? Что ж, это может сработать, но выглядит довольно глупо, черт возьми.
Если подойдет любая строка, попробуйте:
Пункт не где.
9 Конечно, вам понадобится всего несколько секунд, чтобы попробовать это на себе
будет работать лучше всего, другой вариант:
в сценариях, где вам нужны разные подмножества, но я думаю, вы также можете использовать Но мне также нравится поскольку группировка не требуется.
Если вы хотите вернуть только первую строку отсортированного результата с наименьшим количеством подзапросов, попробуйте следующее:
Где sysdate_col — это имя любого столбца, по которому вы хотите выполнить сортировку, и, конечно же, table_name — это имя таблицы, из которой должны поступать отсортированные данные.
Более гибкий, чем является:
Объявление переменных в языке Transact-SQL
Инструкция DECLARE инициализирует переменную Transact-SQL следующим образом:
- Назначение имени. Первым символом имени должен быть одиночный символ @.
- Назначение длины и типа данных, определяемого системой или пользователем. Для числовых переменных задаются также точность и масштаб. Для переменных типа XML может быть дополнительно задана коллекция схем.
- Присваивает созданной переменной значение NULL.
Например, следующая инструкция DECLARE создает локальную переменную @mycounter типа int.
Инструкция DECLARE позволяет объявить несколько переменных одинакового или разного типов через запятую.
Например, следующая инструкция DECLARE создает три локальные переменные с именем @LastName, @FirstName и @StateProvince, присваивая каждой из них значение NULL:
Областью видимости переменной называют диапазон инструкций Transact-SQL, которые могут к ней обращаться. Областью видимости переменной являются все инструкции между ее объявлением и концом пакета или хранимой процедуры, где она объявлена. Например, следующий скрипт содержит синтаксическую ошибку, поскольку переменная объявлена в одном пакете, а используется в другом:
Переменные имеют локальную область видимости и доступны только внутри пакета или процедуры, где они объявлены. В следующем примере вложенная область видимости, созданная для выполнения процедуры sp_executesql, не имеет доступа к переменной, объявленной в более высокой области видимости, и возвращает ошибку:
Секция SELECT
указанные в секции анализируются после завершения всех вычислений из секций, описанных выше. Вернее, анализируются выражения, стоящие над агрегатными функциями, если есть агрегатные функции.
Сами агрегатные функции и то, что под ними, вычисляются при агрегации (). Эти выражения работают так, как будто применяются к отдельным строкам результата.
Если в результат необходимо включить все столбцы, используйте символ звёздочка (). Например, .
Чтобы включить в результат несколько столбцов, выбрав их имена с помощью регулярных выражений re2, используйте выражение .
Например, рассмотрим таблицу:
Следующий запрос выбирает данные из всех столбцов, содержащих в имени символ .
Выбранные стоблцы возвращаются не в алфавитном порядке.
В запросе можно использовать несколько выражений , а также вызывать над ними функции.
Например:
Каждый столбец, возвращённый выражением , передаётся в функцию отдельным аргументом. Также можно передавать и другие аргументы, если функция их поддерживаем. Аккуратно используйте функции. Если функция не поддерживает переданное количество аргументов, то ClickHouse генерирует исключение.
Например:
В этом примере, возвращает два столбца: и . возвращает столбец . Оператор не работает с тремя аргументами, поэтому ClickHouse генерирует исключение с соответствущим сообщением.





Столбцы, которые возвращаются выражением могут быть разных типов. Если не возвращает ни одного столбца и это единственное выражение в запросе , то ClickHouse генерирует исключение.
Звёздочка
В любом месте запроса, вместо выражения, может стоять звёздочка. При анализе запроса звёздочка раскрывается в список всех столбцов таблицы (за исключением и столбцов). Есть лишь немного случаев, когда оправдано использовать звёздочку:
- при создании дампа таблицы;
- для таблиц, содержащих всего несколько столбцов — например, системных таблиц;
- для получения информации о том, какие столбцы есть в таблице; в этом случае, укажите . Но лучше используйте запрос ;
- при наличии сильной фильтрации по небольшому количеству столбцов с помощью ;
- в подзапросах (так как из подзапросов выкидываются столбцы, не нужные для внешнего запроса).
В других случаях использование звёздочки является издевательством над системой, так как вместо преимуществ столбцовой СУБД вы получаете недостатки. То есть использовать звёздочку не рекомендуется.
Экстремальные значения
Вы можете получить в дополнение к результату также минимальные и максимальные значения по столбцам результата. Для этого выставите настройку extremes в 1. Минимумы и максимумы считаются для числовых типов, дат, дат-с-временем. Для остальных столбцов будут выведены значения по умолчанию.
Вычисляются дополнительные две строчки — минимумы и максимумы, соответственно. Эти две дополнительные строки выводятся в форматах , , и отдельно от остальных строчек. В остальных форматах они не выводится.
Во форматах , экстремальные значения выводятся отдельным полем ‘extremes’. В форматах , строка выводится после основного результата и после ‘totals’ если есть. Перед ней (после остальных данных) вставляется пустая строка. В форматах , строка выводится отдельной таблицей после основного результата и после если есть.
Экстремальные значения вычисляются для строк перед , но после . Однако при использовании , строки перед включаются в . В потоковых запросах, в результате может учитываться также небольшое количество строчек, прошедших .
Замечания
Вы можете использовать синонимы (алиасы ) в любом месте запроса.
В секциях , и можно использовать не названия столбцов, а номера. Для этого нужно включить настройку . Тогда, например, в запросе с будет выполнена сортировка сначала по первому, а затем по второму столбцу.
Учебный курс «Основы технологий баз данных»
(курс читает профессор СПбГУ Б. А. Новиков)
«Основы технологий баз данных» — современный курс университетского уровня, сочетающий глубокую теоретическую составляющую с актуальными практическими аспектами применения и проектирования систем. Курс построен на примере PostgreSQL, наиболее продвинутой СУБД с открытым исходным кодом, и содержит как лекционную часть, так и практические занятия.
Курс рассчитан на студентов младших курсов (бакалавриата) классических и технических университетов, а также других вузов, имеющих базовую подготовку по программированию и продолжающих специализироваться в областях, близких к программированию.
Курс читается по одноименному учебному пособию, разработанному коллективом автором СПбГУ при участии компании Постгрес Профессиональный. Материал первой части пособия составляет основу для данного базового курса и содержит краткий обзор требований и критериев оценки СУБД и баз данных, теоретическую реляционную модель данных, основные конструкции языка запросов SQL, обработку транзакций, организацию доступа к базе данных PostgreSQL, вопросы проектирования приложений и основные расширения, доступные в системе PostgreSQL.
Курс читается на ВМК МГУ в аудитория П-13 с 12 сентября по средам с 17:00 до 20:00.
Курс состоит из 24 часов лекционных занятий и 8 часов практических занятий.
Расписание обоих курсов нагляно представлено на схеме ниже. Картинка кликабельна. Желающим посещать крурсы рекомендуется её скачать на свой компьютер/телефон.
Использование Bulk (множественного) SQL в динамическом SQL
SQL Bulk связывает целые коллекции, а не только отдельные элементы. Этот метод повышает производительность за счет минимизации количества переключений контекста между механизмами PL/SQL и SQL. Вы можете использовать один оператор вместо цикла, который выдает оператор SQL на каждой итерации.
Используя следующие команды, предложения и атрибут курсора, ваши приложения могут создавать объемные операторы SQL, а затем выполнять их динамически во время выполнения:
- BULK FETCH предложение
- BULK EXECUTE IMMEDIATE предложение
- FORALL предложение
- COLLECT INTO выражение
- RETURNING INTO выражение
- %BULK_ROWCOUNT атрибут курсора