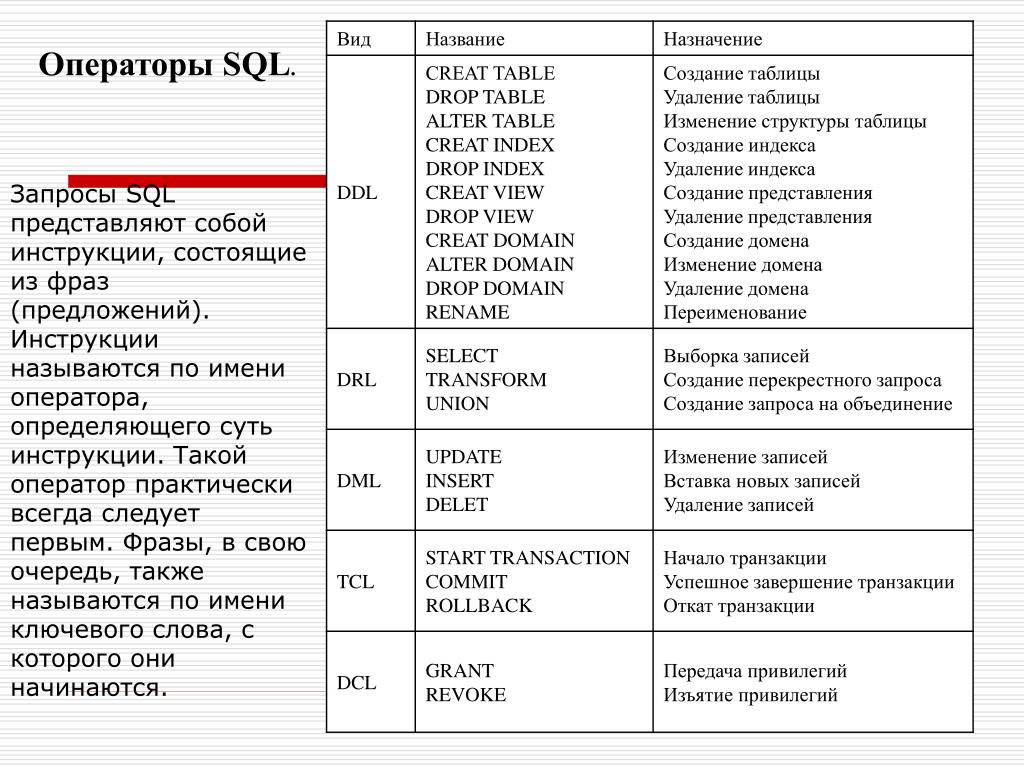
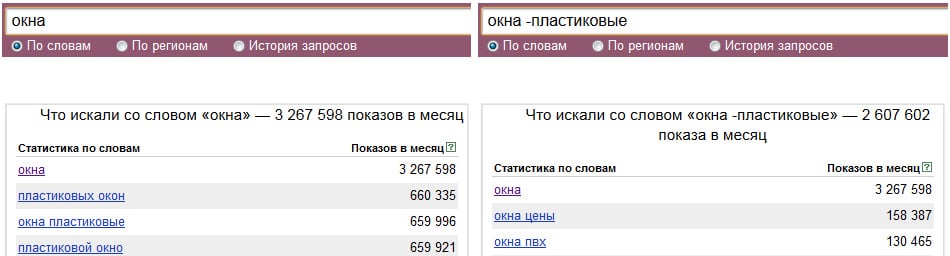
2.7. Оператор Like и символы подстановки в запросах
Очень часто при выполнении запроса известна
только часть содержимого поля Для этой цели Access
предлагает воспользоваться оператором «Like» и символами подстановки (п.2.3.1.1.).
Для выполнения отбора данных с
использование оператора Like»
вы должны указать в ячейке «Условия отбора» того поля по содержимому, которого будет вестись
отбор записей. Таким образом, Access будет выполнять поиск в заданном поле по «Маске».
G Задание. Вы решили дать премию только Агентам.
· Откройте в режиме Конструктора запрос «Расчет премии
Запрос».
· Щелкните на строке «Условия отбора» поля
«Должность»
· Введите в эту строку «Like А*»
· Выполните запрос
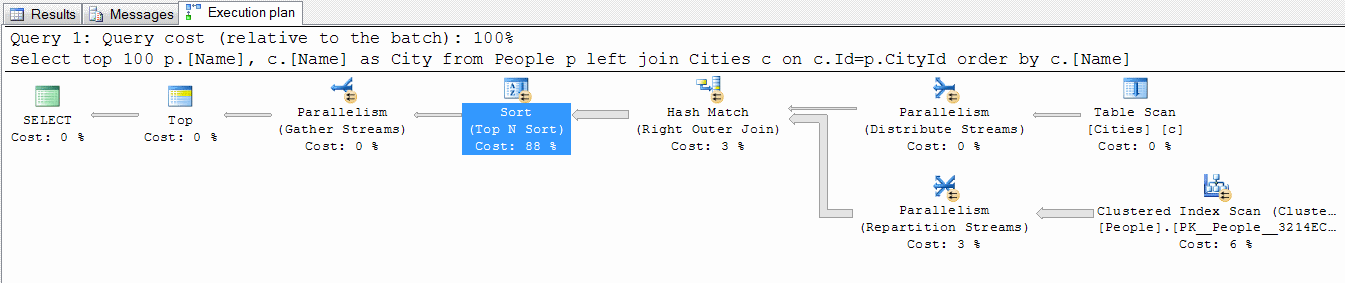
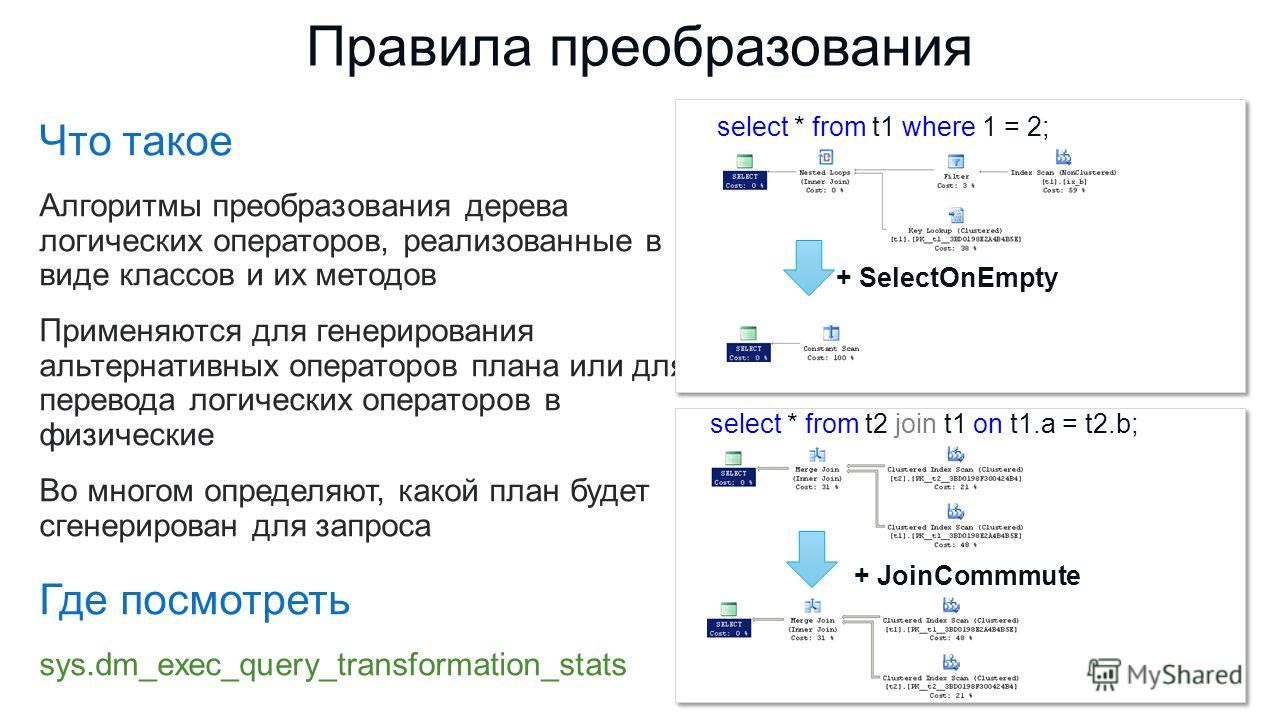
Key Lookup
Поиск ключей. Возникает, когда SQL Server предполагает, что он с большей эффективностью может использовать некластеризованный индекс, а затем перейти к кластерзованному индексу для поиска оставшихся значения строк, которые отсутствуют в некластеризованном индексе. Это не всегда плохо: обращение SQL Server к кластеризованному индексу для извлечения недостающих значений довольно эффективный метод по сравнению с необходимостью создавать и поддерживать совершенно новые индексы.
Однако, если все, что нужно SQL Server от операции Key Lookup, это единственный столбец данных, гораздо проще добавить этот столбец в ваш существующий некластеризованный индекс. Размер индекса увеличится на один столбец, но SQL Server сможет избежать необходимости обращаться к двум индексам для извлечения всех необходимых данных и это в целом окажется более эффективным решением.
Hash Match Join
Операция используется всегда, когда невозможно применить другие виды соединения. Она выбираются оптимизатором запросов по одной из двух причин:
- Соединяемые наборы данных настолько велики, что они могут быть обработаны только с помощью Hash Match Join.
- Наборы данных не упорядочены по столбцам соединения, и SQL Server думает, что вычисление хэшей и цикл по ним будет быстрей, чем сортировка данных.
При первом сценарии трудно оптимизировать выполнение запроса, если только не найти способа соединять меньшие объемы данных.
При втором же сценарии, если есть некоторый способ получить данные в упорядоченном виде до соединения, типа предопределенного порядка сортировки в индексе, то возможно, что SQL Server выберет вместо этой операции более быстрый алгоритм соединения.
Операторы Hash Match Join достаточно эффективны тогда, когда не сбрасывают данные в tempdb.
Предложение ORDER BY
Сортировка происходит после того, как в базе данных будет готов весь набор результатов (после фильтрации, группировки, удаления дубликатов). После этого база данных может теперь сортировать результирующий набор, используя столбцы, выбранные псевдонимы или функции агрегирования, даже если они не являются частью выбранных данных. Единственным исключением является использование ключевого слова DISTINCT, которое предотвращает сортировку по не выбранному столбцу, так как в этом случае порядок набора результатов будет неопределенным.
Вы можете выбрать сортировку данных по убыванию (DESC) или по возрастанию (ASC). Заказ может быть уникальным для каждой из частей заказа, поэтому действует следующее: ORDER BY firstname ASC, age DESC
Методы, основанные на процедурах и процедурных подходах к запросам
Что мы хотели сказать вышеупомянутыми анти-шаблонами, так это указать тот факт, что они сводятся к различию в методах подхода, основанного на наборе данных и процедурномподходе к созданию запросов.
Процедурный подход к созданию запросов – это подход, который очень похож на обычное процедурное программирование: вы сообщаете системе, что делать и как это делать.
Примером такого подхода является избыточные условия в соединениях или случаях, когда вы злоупотребляете предложением , как в приведенных выше примерах, когда вы запрашиваете базу данных, выполняя функцию, а затем вызываете другую функцию или используете логику, содержащую цикл, условия, пользовательские функции (UDF), курсоры, … для получения окончательного результата. При таком подходе вы часто будете спрашивать подмножество данных, затем запрашивать другое подмножество из данных и так далее.
Неудивительно, что этот подход часто называют «поэтапным» или запросом «по очереди».
Другой подход — это подход, основанный на наборе данных, когда вы просто указываете, что делать. Ваша роль состоит в том, чтобы указать условия или повторные запросы для набора результатов, который вы хотите получить. То, как именно будут извлекаться ваши данные, остается на совести внутренних механизмов, которые определяют реализацию запроса: то есть вы позволяете механизму базы данных определять наилучшие алгоритмы или логику обработки для выполнения вашего запроса.
Поскольку SQL настроен на подход, основанный на наборе данных, вряд ли вас удивит, что этот подход будет более эффективным, чем процедурный, и это также объясняет, почему в некоторых случаях SQL может работать быстрее, чем код.
Совет. Подход, основанный на наборе данных, требуется большинству ведущих работодателей! Поэтому вам потребуется часто переключаться между этими двумя подходами.
Обратите внимание: если вы будете разрабатывать процедурный запрос, вам следует рассмотреть возможность его перезаписи или рефакторинга
Добавление нового оператора JOIN
В предыдущих примерах рассматривалась одна таблица. Давайте добавим вторую таблицу, используя оператор JOIN. Предположим, мы хотим получить фамилии и идентификаторы сотрудников, работающих в отделах с бюджетом более 275 000. Запрос для этой ситуации выглядит следующим образом:
SELECT EMPLOYEE_ID, LAST_NAME
FROM EMPLOYEES
JOIN DEPARTMENT
ON DEPARTMENT = DEPT_NAME
WHERE BUDGET > 275000
Опять же, сначала мы выполняем FROM EMPLOYEE, который извлекает эти данные:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT |
|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING |
| 101 | Mary | Sexton | 82,000 | IT |
| 102 | Chun | Yen | 80,500 | ACCOUNTING |
| 103 | Agnes | Miller | 95,000 | IT |
| 104 | Dmitry | Komer | 120,000 | SALES |
Во-вторых, мы применяем условие JOIN, генерируя новый промежуточный результат, объединяющий обе таблицы:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT | DEPT_NAME | MANAGER | BUDGET |
|---|---|---|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING | ACCOUNTING | 100 | 300,000 |
| 101 | Mary | Sexton | 82,000 | IT | IT | 101 | 250,000 |
| 102 | Chun | Yen | 80,500 | ACCOUNTING | ACCOUNTING | 100 | 300,000 |
| 103 | Agnes | Miller | 95,000 | IT | IT | 101 | 250,000 |
| 104 | Dmitry | Komer | 120,000 | SALES | SALES | 104 |
В-третьих, применяется функция WHERE BUDGET > 275000:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | SALARY | DEPARTMENT | DEPT_NAME | MANAGER | BUDGET |
|---|---|---|---|---|---|---|---|
| 100 | James | Smith | 78,000 | ACCOUNTING | ACCOUNTING | 100 | 300,000 |
| 102 | Chun | Yen | 80,500 | ACCOUNTING | ACCOUNTING | 100 | 300,000 |
| 104 | Dmitry | Komer | 120,000 | SALES | SALES | 104 |
Наконец, выполняется SELECT EMPLOYEE_ID, LAST_NAME, выдавая конечный результат запроса:
| EMPLOYEE_ID | LAST_NAME |
|---|---|
| 100 | Smith |
| 102 | Yen |
| 104 | Komer |
Порядок выполнения в этом примере следующий:
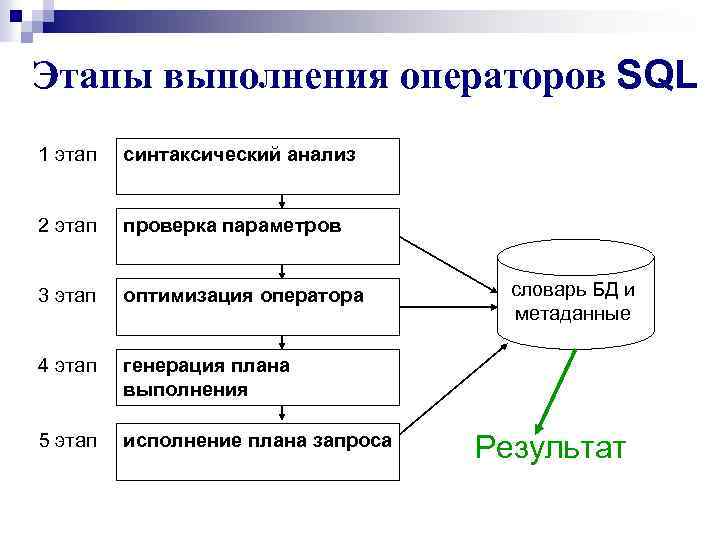
 Порядок выполнения операций SQL
Порядок выполнения операций SQL
Заключительные слова
В этой статье мы рассмотрели порядок выполнения SQL-запросов на примерах. Из этих примеров видно, что существует определенный порядок, но этот порядок может меняться в зависимости от того, какие пункты присутствуют в запросе. В качестве общего руководства можно сказать, что порядок выполнения следующий:
 Порядок выполнения операций SQL
Порядок выполнения операций SQL
Однако если один из этих пунктов отсутствует, порядок выполнения будет другим. SQL — это простой язык начального уровня, но как только вы погрузитесь в него, вам предстоит изучить множество интересных концепций.

Возможно вам будет интересно:
метод 1-использование SQL Server Management Studio
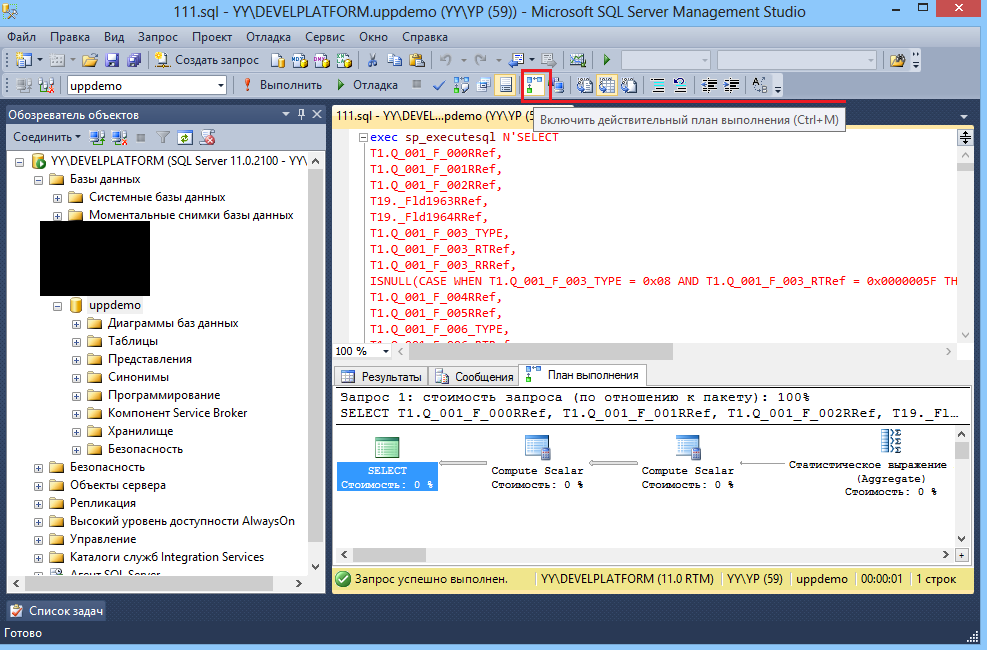
SQL Server поставляется с пара аккуратных функций, которые позволяют очень легко захватить план выполнения, просто убедитесь, что пункт меню» включить фактический план выполнения «(находится в меню» запрос») отмечен галочкой и запустите запрос как обычно.
![]()
если вы пытаетесь получить план выполнения инструкций в хранимой процедуре, то вы должны выполнить хранимую процедуру, вот так:
когда ваш запрос завершится, вы увидите дополнительную вкладку под названием «План выполнения» появится в области результатов. Если вы выполнили много операторов, вы можете увидеть много планов, отображаемых на этой вкладке.
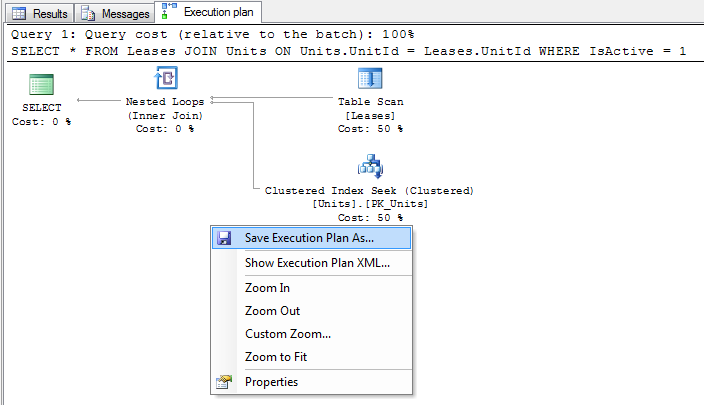
отсюда вы можете проверить план выполнения в SQL Server Management Studio или щелкнуть правой кнопкой мыши по плану и выбрать «Сохранить план выполнения как …»чтобы сохранить план в файл в формате XML.
Предоставлять, отзывать и запрещать разрешения для базы данных
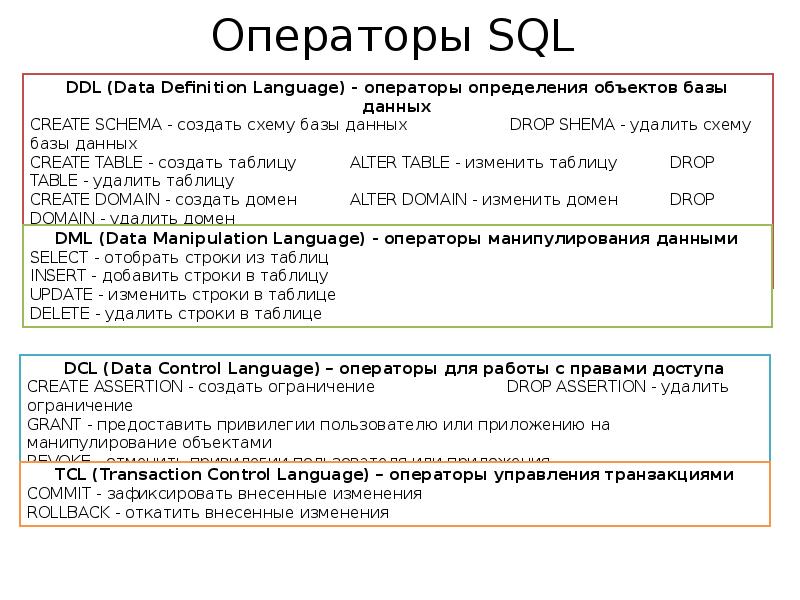
Язык управления данными (DCL) является подмножеством языка структурированных запросов (SQL) и позволяет администраторам баз данных настраивать безопасный доступ к реляционным базам данных. Он дополняет язык определения данных (DDL), который используется для добавления и удаления объектов базы данных, и язык манипулирования данными (DML), используемый для извлечения, вставки и изменения содержимого базы данных.
DCL является самым простым из подмножеств SQL, поскольку он состоит только из трех команд: GRANT, REVOKE и DENY. В совокупности эти три команды предоставляют администраторам возможность гибко устанавливать и удалять разрешения для базы данных.
Добавление разрешений с помощью команды GRANT
Команда GRANT используется администраторами для добавления новых разрешений пользователю базы данных. У него очень простой синтаксис, определенный следующим образом:
GRANT ON TO
Вот краткое описание каждого из параметров, которые вы можете указать с помощью этой команды:
Привилегия – может быть ключевым словом ALL (для предоставления широкого спектра разрешений) или определенным разрешением базы данных или набором разрешений. Примеры включают CREATE DATABASE, SELECT, INSERT, UPDATE, DELETE, EXECUTE и CREATE VIEW.
Объект – может быть любым объектом базы данных. Допустимые параметры привилегий зависят от типа объекта базы данных, который вы включаете в это предложение. Как правило, объект будет либо базой данных, функцией, хранимой процедурой, таблицей или представлением.
Пользователь – может быть любым пользователем базы данных. Вы также можете заменить роль для пользователя в этом пункте, если хотите использовать безопасность баз данных на основе ролей.
Если вы добавите необязательное условие WITH GRANT OPTION в конце команды GRANT, вы не только предоставите указанному пользователю разрешения, определенные в операторе SQL, но и дадите пользователю возможность предоставить те же разрешения. другим пользователям базы данных
По этой причине используйте этот пункт с осторожностью.
Например, предположим, что вы хотите предоставить пользователю Джо возможность извлекать информацию из таблицы сотрудников в базе данных под названием HR. Вы можете использовать следующую команду SQL:
ВЫБРАТЬ ГРАНТ НА HR.employees TO Джо
Теперь у Джо будет возможность извлекать информацию из таблицы сотрудников. Однако он не сможет предоставить другим пользователям разрешение на извлечение информации из этой таблицы, поскольку вы не включили условие WITH GRANT OPTION в оператор GRANT.
Отмена доступа к базе данных
Команда REVOKE используется для удаления доступа к базе данных у пользователя, ранее предоставившего такой доступ. Синтаксис этой команды определяется следующим образом:
REVOKE ON FROM
Вот краткое описание параметров команды REVOKE:
- Разрешение – указывает разрешения для базы данных, которые необходимо удалить для указанного пользователя. Команда отменяет оба утверждения GRANT и DENY, ранее сделанные для указанного разрешения.
- Объект – может быть любым объектом базы данных. Допустимые параметры привилегий зависят от типа объекта базы данных, который вы включаете в это предложение. Как правило, объект будет либо базой данных, функцией, хранимой процедурой, таблицей или представлением.
- Пользователь – может быть любым пользователем базы данных. Вы также можете заменить роль для пользователя в этом пункте, если хотите использовать безопасность баз данных на основе ролей.
- Предложение GRANT OPTION FOR устраняет возможность указанного пользователя предоставлять указанное разрешение другим пользователям. Примечание . Если вы включите условие GRANT OPTION FOR в оператор REVOKE, основное разрешение будет не отменено. Этот пункт отменяет только возможность предоставления.
- Параметр CASCADE также отменяет указанное разрешение у всех пользователей, которым указанный пользователь предоставил разрешение.
Например, следующая команда отзывает разрешение, предоставленное Джо в предыдущем примере:
ОТМЕНИТЬ ВЫБРАТЬ НА HR.employees ОТ Джо
Явный отказ в доступе к базе данных
Команда DENY используется для явного запрета пользователю получать определенное разрешение. Это полезно, когда пользователь является участником роли или группы, которой предоставлено разрешение, и вы хотите запретить этому отдельному пользователю наследовать разрешение путем создания исключения. Синтаксис этой команды следующий:
DENY ON TO
Параметры для команды DENY идентичны параметрам, используемым для команды GRANT.Например, если вы хотите, чтобы Мэтью никогда не получал возможность удалять информацию из таблицы сотрудников, введите следующую команду:
УДАЛЕНИЕ ДЕНИ НА HR.employees TO Matthew
Какие СУБД бывают
На самом деле, существует достаточно много различных СУБД, некоторые из них платные и стоят немалых денег, если говорить о полнофункциональных версиях, но даже у самых, так скажем, «крутых» есть бесплатные редакции, которые, кстати, отлично подходят для обучения.
- Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях. И это не просто СУБД – это целый комплекс приложений, позволяющий хранить и модифицировать данные, анализировать их, осуществлять безопасность этих данных и многое другое;
- Oracle Database – это система управления базами данных от компании Oracle. Это также очень популярная СУБД, и также среди крупных компаний. По своим возможностям и функциональности Oracle Database и Microsoft SQL Server сопоставимы, поэтому являются серьезными конкурентами друг другу, и стоимость их полнофункциональных версий очень высока;
- MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила очень широкую популярность в интернет сегменте, т.е. именно на MySQL работают чуть ли не все сайты в интернете, иными словами, большинство сайтов в интернете используют эту СУБД как средство хранения данных;
- PostgreSQL – эта система управления базами данных также является бесплатной, и она очень популярна и функциональна.
Index Scan
Сканирование некластеризованного индекса. Обычно наличие этой операции плохо отражается на производительности, поскольку она предполагает последовательное чтение индекса для извлечения большого числа строк, приводя к более медленной обработке. Но бывают исключения, например, применение директивы TOP, ограничивающей число возвращаемых записей; если возвращать всего несколько строк, то операция сканирования будет выполняться достаточно быстро, и вы не сможете получить лучшую производительность, чем ту, которую уже имеете, даже если вы попытаетесь перестроить запрос/индексы, чтобы добиться операции Index Seek.
Скажите нет грубой силе
Этот последний совет на самом деле означает, что вы не должны слишком сильно ограничивать запрос, потому что это может повлиять на его производительность. Это особенно верно для объединений и для предложения .
Когда вы объединяете две таблицы, может быть важно рассмотреть порядок объединения таблиц. Если вы заметили, что одна таблица значительно больше другой, вы можете переписать свой запрос так, чтобы самая большая таблица была помещена последней в объединении
Избыточные условия для объединений
Когда вы добавляете слишком много условий для объединений, вы, по сути, предписываете SQL выбрать определенный путь. Может быть, однако, что этот путь не всегда более эффективен.
Предложение было первоначально добавлено в SQL, потому что ключевое слово не могло использоваться с агрегатными функциями. обычно используется с предложением , чтобы ограничить группы возвращаемых строк только теми, которые соответствуют определенным условиям. Однако, если вы используете это предложение в своем запросе, индекс не используется, который, как вы уже знаете, что может привести к запросу, который будет не реально выполнить.
Если вы ищете альтернативу, подумайте об использовании предложения . Рассмотрим следующие запросы:
SELECT state, COUNT(*) FROM Drivers WHERE state IN ('GA', 'TX') GROUP BY state ORDER BY state
SELECT state, COUNT(*) FROM Drivers GROUP BY state HAVING state IN ('GA', 'TX') ORDER BY state
В первом запросе используется предложение , чтобы ограничить количество строк, которые нужно суммировать, тогда как второй запрос суммирует все строки в таблице, а затем использует для отбрасывания вычисленных сумм. В таких случаях альтернатива с предложением , очевидно, лучше, поскольку вы не тратите никаких ресурсов.
Вы видите, что здесь речь идет не о ограничении результатов запроса, а об ограничении промежуточного количества записей в запросе.
Обратите внимание, что разница между этими двумя предложениями заключается в том, что оператор вводит условие для отдельных строк, тогда как оператор вводит условие агрегирования или повторных выборов, в которых один результат, такой как , , , … был создан из нескольких строк. Как видите, оценка качества, запись и переписывание запросов –непростая задача, если учесть, что они должны быть максимально эффективными
Избегание анти-шаблонов и использование альтернативных вариантов в написании запросов также являются частью вашей заботы при написании очередей, которые можно запускать в базах данных в профессиональной среде
Как видите, оценка качества, запись и переписывание запросов –непростая задача, если учесть, что они должны быть максимально эффективными. Избегание анти-шаблонов и использование альтернативных вариантов в написании запросов также являются частью вашей заботы при написании очередей, которые можно запускать в базах данных в профессиональной среде.

![Sql [айти бубен]](https://wudgleyd.ru/wp-content/uploads/f/6/4/f6474ba53b2335a00ffee65514905966.png)

Этот список был всего лишь небольшим обзором некоторых анти-шаблонов и советов, которые, надеюсь, помогут новичкам. Если вы хотите получить представление о том, что более старшие разработчики считают наиболее частыми антишаблонами, ознакомьтесь с этим обсуждением.
Виды операторов и принцип их действия
Чтобы не быть голословными, рассмотрим способы использования каждого оператора на примере сервиса WordStat — это позволит наглядно продемонстрировать особенности действия каждого спецсимвола.
Кавычки
Оператор «Кавычки» — «» — запрещает добавлять к введенной конструкции дополнительные слова. Это означает, что, используя данный оператор, Вы получите данные только по введенному запросу, без каких-либо «хвостов».
Например, анализируя через WordStat запрос «”подбор слов”», Вы не увидите в выдаче позиции с дополнительными словами: «подбор слов яндекс», «подбор ключевых слов» и т.д. При этом останутся показы, состоящие из различных форм введенных слов: «подборы слов», «слова подбор» и т.д.
Восклицательный знак
Восклицательный знак делает неизменной форму слова, перед которым ставится. Применяется данный оператор лишь к тому слову, перед которым он стоит. Если фраза состоит из нескольких слов, форму которых необходимо зафиксировать, восклицательный знак ставится перед каждым из них.
Если использовать данный оператор в WordStat, результаты выдачи могут содержать дополнительные слова, но при этом в каждом запросе обязательно будет содержаться слово в указанной форме.
Используя оператор «Восклицательный знак» при настройке контекстной рекламы, Вы ограничиваете выдачу. Так, например, если набрать «!зеленое !платье» объявления будут отображаться по запросам «купить зеленое платье», «зеленое платье 40 размера» и т.д. А вот запросы «зеленые платья оптом», «дизайн зеленого платья» уже будут проигнорированы.
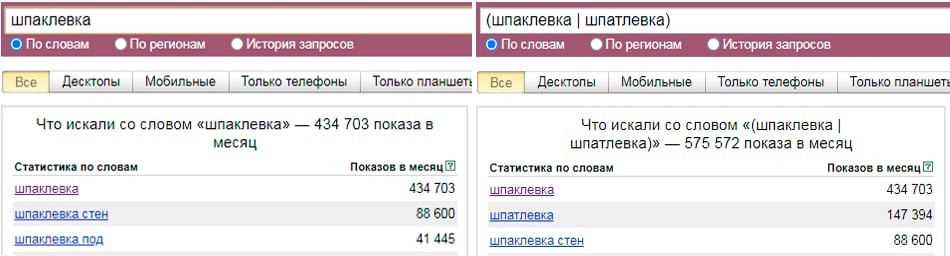
«Или»
Оператор «Или» задается символом «|» и используется в том случае, когда необходимо охватить несколько фраз или синонимов. Как правило, используется данный символ только при анализе статистики запросов для быстрого подбора семантики.
Так, например, специалист может смешать запросы «шпаклевка» и «шпатлевка», так как пользователи руководствуются единой целью, когда вводят их. В данном случае учет нетипичной словоформы позволил определить значительный прирост количества показов, а значит имеет смысл добавление данного ключа в семантическое ядро.
Квадратные скобки
Оператор «Квадратные скобки» задается символами «[]» между которым заключена фраза. Подобная конструкция позволяет фиксировать порядок слов в поисковом запросе.
Данный оператор может использовать в различных кампаниях, но достаточно редко. Однако есть вертикаль, в которой без кавычек не обойтись — туризм, авиа- и железнодорожные перевозки.
Так, например, запросы «билеты Москва Лондон» и «билеты Лондон Москва» кардинально различаются. Проводя рекламную кампанию, не конкретизируя последовательность слов, Вы рискуете получить большое количество нецелевых переходов.
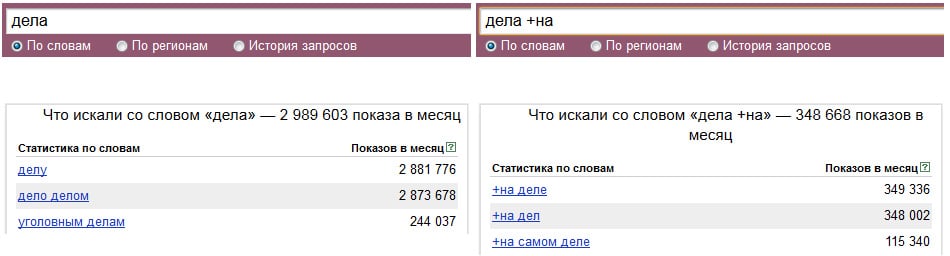
Плюс
Оператор «плюс» позволяет сделать определенное слово в поисковой фразе обязательным. Как правило, используется перед важными предлогами и союзами, которые «Яндекс» по умолчанию не учитывает.
Минус
Оператор «минус» задается символом «-», стоящим перед словом, которое необходимо исключить из поискового запроса. Как правило, в роли таких слов выступают минус-слова — те ключи, которые приводят нецелевой трафик.
Использование оператора «минус» позволяет трезво оценить ситуацию и выявить лишь целевой трафик. Как показывает практика, в большинстве ниш после комплексной проработки минус-слов и минус-фраз целевой трафик уменьшается от 2 до 10 раз. Однако при этом его качество пропорционально возрастает.
«Группировка»
Оператор «Группировка» задается круглыми скобками, в которые заключаются ключевые слова и применяемые к ним прочие операторы.
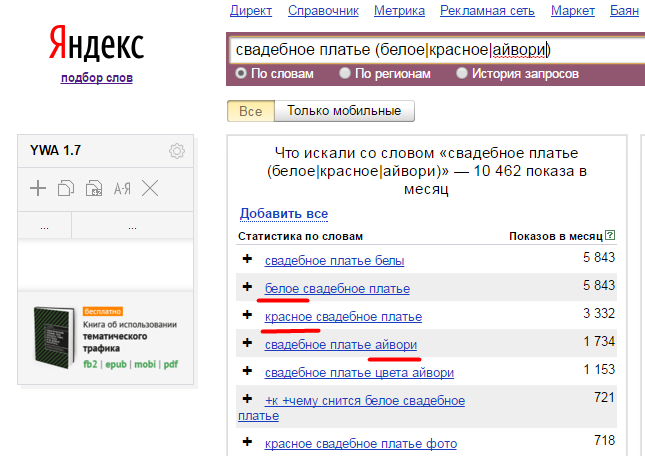
Допустим, свадебный салон запустить отдельную рекламную кампанию по запросам с указанием конкретного цвета платья. Применение оператора «Группировка» можно из 3 разных ключевых запросов сконструировать один общий: Свадебное платье (белое|красное|айвори). Теперь реклама будет показываться всем, кто введет в поисковую строку запрос «свадебное платье» с указанием цвета.
Операторы контекстной рекламы могут применяться как к одному слову из запроса, так и к группе элементов. Также нередко операторы комбинируются — об этом мы поговорим далее.
Функции «слоупока»: как заставить открываться «Все функции» в 97 раз быстрее!
Наверное, каждый программист 1С (да и не только программист), открывая «Функции для технического специалиста» (ранее «Все функции») на массивных конфигурациях вроде ERP 2.4 и т.п., в своей жизни много раз задавался вопросом – почему же они так долго открываются??
Действительно, в зависимости от мощностей сервера «Все функции» могут открываться от 20 секунд до 2 минут!
«Ну, слишком много объектов в конфигурации, огромное количество констант, справочников, документов, регистров… – Отвечали себе страдающие пользователи. – Пока программа обойдёт в цикле все метаданные, пока построит дерево… Тут ничего не поделаешь…».
И все они были не правы! Я провёл собственное расследование, которое показало, что 97% времени построения дерева метаданных тратится на…
1 стартмани
09.03.2022
18549
73
XilDen
76
221
Sort
Сортировка является одной из наиболее дорогих операций, которые могут быть в плане выполнения, поэтому лучше избегать ее, насколько это возможно.
Простой способ избежать оператора сортировки – иметь данные, хранящиеся в предварительно упорядоченном виде. Это может быть выполнено созданием индекса с ключевыми столбцами, перечисленными в том же самом порядке, который использует оператор сортировки.
Если SQL Server должен выполнить сортировку одних и тех же данных в одном и том же порядке несколько раз в плане выполнения, то еще одним выходом является разбиение запроса на несколько этапов при использовании временных индексированных таблиц для сохранения данных между этапами. В таком случае, если вы будете повторно использовать временную таблицу в плане выполнения вашего запроса, то вы получите чистую экономию.
Зачем мне изучать SQL, если я занимаюсь данными?
SQL весьма далек от забвения – напротив, это один из самых востребованных навыков, который вы можете найти в описаниях вакансий в области обработки больших данных, независимо от того, хотите ли вы устроиться на должность аналитика данных, инженера по данным, научного сотрудника в области данных или в качестве еще кого-либо. Этот факт подтверждается результатами исследования рынка труда, проведенным O’Reilly в 2016 году: 70% респондентов, участвовавших в опросе, подтвердили, что в своей профессиональной деятельности они используют SQL. Более того, в обзоре результатов этого исследования язык SQL занимает более высокую позицию, по сравнению с другими языками программирования, такими как R (57%) и Python (54%).
Теперь вы понимаете в чем тут дело: SQL является обязательным навыком, если вы хотите получить работу в сфере обработки больших данных.
Неплохо для языка, который был разработан еще в начале 1970-х годов прошлого века, не правда ли?
Но почему так часто используется именно этот язык? И почему он до сих пор не мертв, как многие другие языки того же поколения?
Для объяснения этого факта можно найти несколько причин: во-первых, компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в системах управления реляционными потоками данных (RDSMS), и SQL требуется для доступа к таким хранимым данным. SQL – это универсальный язык данных: он дает вам возможность взаимодействовать практически с любой базой данных или даже создавать свои локальные базы данных!
Только имейте в виду, что существует немало реализаций SQL, которые несовместимы между собой и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является обязательным для каждого, желающего найти свой путь в это наукоемкой отрасли.
Кроме того, можно с уверенностью сказать, что SQL также включается в новые технологии, такие как Hive, SQL-подобный язык запросов, ориентированный на запросы и управление большими наборами данных, или Spark SQL, которые вы можете использовать для выполнения SQL запросов. Но еще раз напоминаем, SQL, который вы найдете в этих технологиях, будет отличаться от стандартного, который вы, возможно, уже знаете, но разобраться в особенностях конкретной реализации, зная стандартный SQL, вам будет значительно проще.
Если хотите, можем привести такую аналогию с линейной алгеброй: сосредоточив все усилия только на этой одной области математики, вы сможете использовать полученные знания и как хорошую основу для овладения машинным обучением!
Короче говоря, вот причины, по которым вам следует изучить язык структурированных запросов:
- Он довольно прост в изучении, даже для новичков. Рост знаний и навыков происходит довольно быстро, и вы в кратчайшие сроки научитесь писать запросы.
- Изучение SQL подчиняется принципу «однажды изученное может применяться повсюду», поэтому это отличное вложение вашего времени и сил!
- Это отличное дополнение к языкам программирования. В некоторых случаях писать запрос даже предпочтительнее, чем писать код, потому что он более эффективен!
- …
И чего же ты все еще ждешь?
SELECT раздел ORDER BY
ORDER BY используется для того, чтобы упорядочить строки, извлекаемые запросом.
В предложении ORDER BY SQL можно задавать несколько выражений. Сначала сортируются строки, основываясь на их значениях для первого выражения. Строки с одним и тем же значением для первого выражения затем сортируются по второму выражению и так далее. NULL- значения располагает после всех других при упорядочивании в порядке возрастания и перед всеми другими при сортировке в убывающем порядке.
ORDER BY подчинено следующим ограничениям:
- Если в утверждении SELECT используются и оператор ORDER BY и оператор DISTINCT, то предложение ORDER BY не может ссылаться на столбцы, не упоминаемые в списке выбора выбираемых столбцов.
- Предложение ORDER BY не может появляться в подзапросах внутри других утверждений.
Пример. ORDER BY в возрастающем (ASC по умолчанию ) и убывающем (DESC) порядке. Выбрать из таблицы peers записи, упорядоченные сначала по возрастанию данных в столбце code, а затем по убыванию данных в столбце sale:
SELECT ename, deptno, sal FROM peers ORDER BY code ASC, sale DESC;
При задании в операторе ORDER BY числовой константы сортировка осуществляется по столбцу с за данным в списке SELECT порядковым номером. Когда в ORDER BY задается функция, сортировке подвергается результат, возвращаемый функцией для каждой строки.
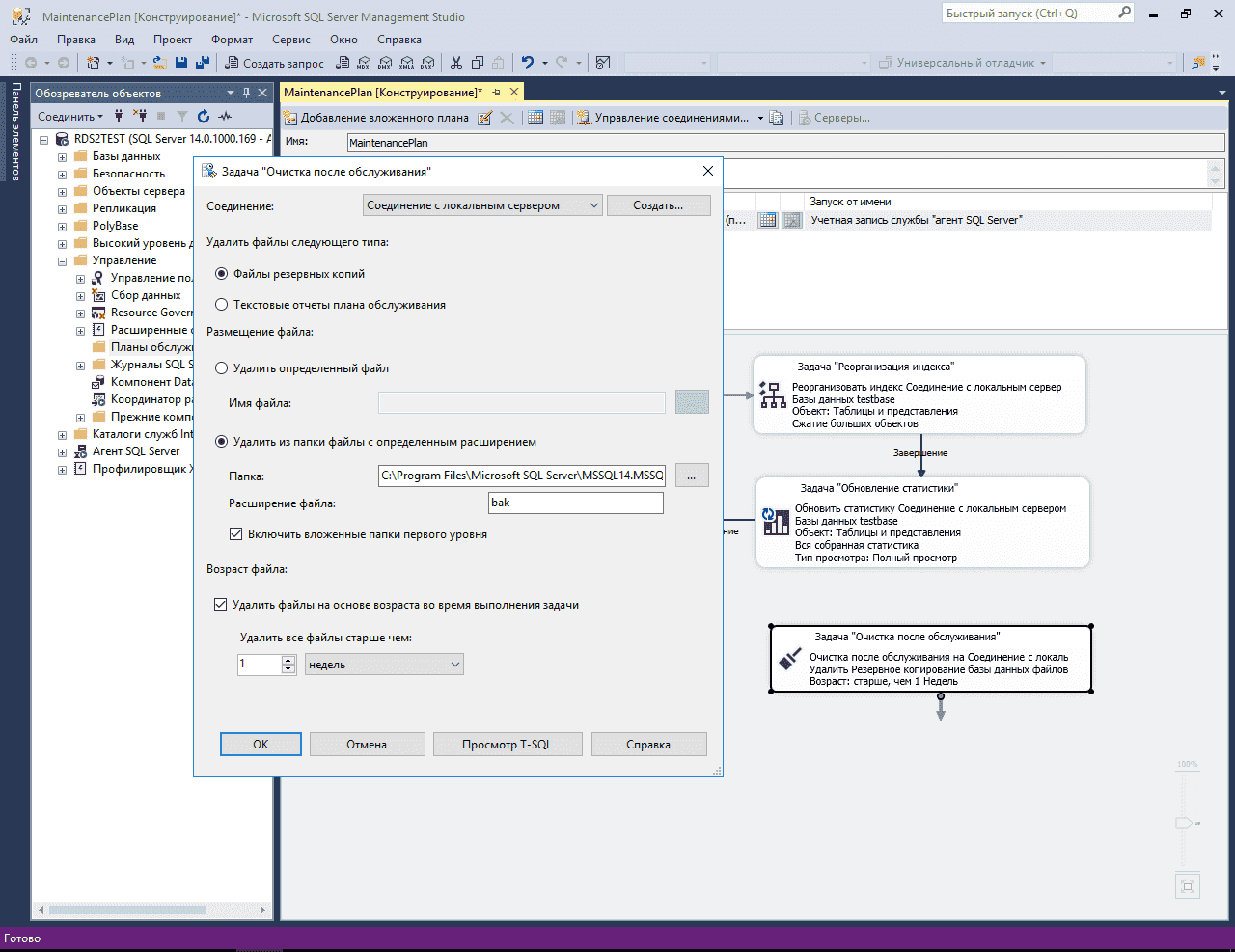
Очистка устаревших бэкапов.
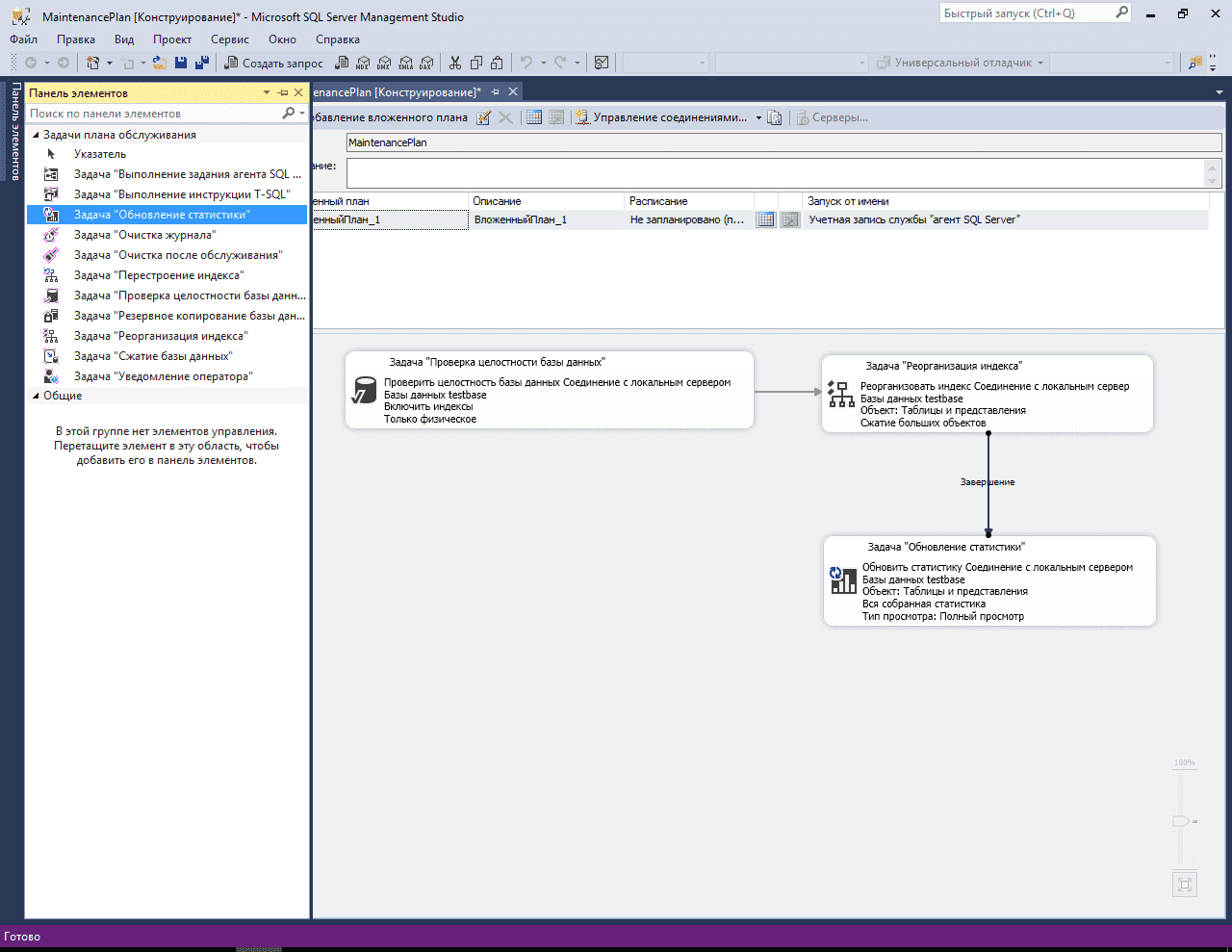
Для очистки устаревших бэкапов баз 1С Предприятия в MS SQL выбираем на панели элементов плана обслуживания Задачу «Очистка после обслуживания».
Перетаскиваем задачу с Панели элементов в план и задаем такие настройки:
- Удалить файлы следующего типа: Файлы резервных копий;
- Удалить из папки файлы с определенным расширением: указываем папку хранения бэкапов баз 1С;
- Включить вложенные папки первого уровня: отмечаем галочкой, потому-что у нас для бэкапов баз создаются отдельные папки
- Удалить файлы на основе возраста во время выполнения задачи: здесь все ограничивается лишь вашими потребностями и объемом жесткого диска, а мне достаточно 4 недель.
Чтобы в текущем плане после выполнения первого задания начало выполнятся следующее, их необходимо соединить между собой стрелками. Для этого выделяем первое задание и ведем стрелку от него к следующему.
По умолчанию стрелка зеленого цвета. Это значит, что следующее задание будет выполняться только при успешном завершении первого. Это условие подходит для моего случая.
Переходим к очень важному и ответственному пункту: Перестроение индекса и обновление статистики